Introduction
XPath Analyzer is an attempt to build a query analyzer for XPath language, accessible over the Internet. XPath is a very efficient language to address specific nodes in an XML document. It is frequently used in XSLT to transform XML document to another document format. However, with the introduction of .NET that strongly supports XML, XPath has earned a new position in the hand of developers, and is used extensively to assist XML processing.
Given an XML document and an XPath string, the script will produce any possible result from an XPath query. In fact, the script tries to run the XPath query, and if successful (no errors occur), returns a set of nodes with any child nodes, value and attributes they have. The script could differentiate between element, attribute, text, and comment node and will process each node accordingly.
If you ever use the XPath evaluator from Altova's XML Spy, then the XPath Analyzer tries to clone some parts of its functionality and bring them online. I should also honor work by Chris Payne in his book titled 'Teach Yourself: ASP.NET', published by Sams, which becomes the basis of the script.
Hopefully this little script could assist web developers to analyze and fine tune XPath query, as well as become a learning tool for XPath enthusiasts.
About the demo
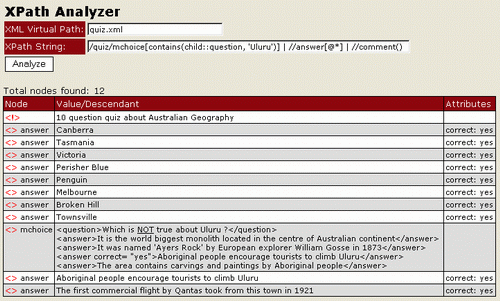
Included with the demo package is an XML document, quiz.xml. It is a similar XML document from my previous article titled Online Quiz.
The script will accept virtual path of XML document. So if the XML document you want to evaluate resides in the same folder with the script, then just type the file name like mydata.xml. If it resides in a folder downward, then type like myfolder/mydata.xml.
You can input any XPath string, in unabbreviated form, such as descendant::answer or abbreviated form, such as //answer, as long as they meet these conditions:
- Originated from the document root. Therefore always start with '/'
- Produce a node set, does not matter whether they are elements, attributes, comments, texts, or a mix. XPath string that produces value are not handled yet.
Try the following XPath string to query quiz.xml:
| XPath | Expected result |
/descendant::mchoice[count(child::answer)> | Selects multiple choice (mchoice) that has more than 4 answers |
/quiz/mchoice[contains(child::question, 'NOT')] | Selects multiple choice which question child element contains string 'NOT' |
/quiz/mchoice/answer[@correct='yes'] | Selects all correct answers |
//mchoice[last()] | Selects the last multiple choice of the quiz |
//mchoice[position()=2] | //mchoice[position()=5] | Selects the second and the fifth multiple choice |
The script explained
The XPath Analyzer script uses three classes intensively. They are XPathDocument, XPathNavigator, and XPathNodeIterator. All classes are derived from System.Xml.XPath.
The XPathDocument provides a high performance XML reader optimized for XPath processing. Somehow, XPathDocument provides less overhead than XMLDocument class, since it does not need to build a tree-like structure in the cache.
A piece of code below creates an instance of XPathDocument class and loads employee.xml into the cache. It assumes the XML document is located in the same folder as the aspx script.
Dim xDoc as New XPathDocument(Server.MapPath("quiz.xml"))
Navigating cursor
Navigation through the XML document is provided by XPathNavigator class. An XPathNavigator object acts like a cursor, addressing a node in the XML document at a time. To create an XPathNavigator object of the corresponding XPathDocument, we invoke CreateNavigator method. This method also applies to XMLNode class, so you could use the cursor in XML DOM as well.
Dim xNav as XPathNavigator = xDoc.CreateNavigator()
There is a bunch of move methods to move the cursor through the XML document.
| Method | What it does? |
MoveToFirst() | Moves to the first sibling of the current node |
MoveToFirstAttribute() | Moves to the first attribute of the current node. It could be used to check whether the current node has any attributes. |
MoveToFirstChild() | Moves to the first child of the current node. It could be used to check whether the current node has any child nodes. |
MoveToNext() | Moves to the next sibling of the current node |
MoveToNextAttribute() | Moves to the next attribute. |
MoveToNextChild() | Not available! Use MoveToNext() instead. |
MoveToParent() | Moves to the parent of the current node. Call this method to return cursor to the original position after processing its attributes or direct child nodes. |
MoveToPrevious() | Moves to the previous sibling of the current node. |
MoveToRoot() | Moves to the root node. |
Accessing attributes of an element is a bit tricky though! First, we have to invoke MoveToFirstAttribute method to move the cursor to the first attribute. Then we iterate through all attributes by invoking MoveToNextAttribute until all attributes has been processed. Finally, MoveToParent method is invoked to return the cursor to the corresponding element.
The following code shows this technique:
If xNav.MoveToFirstAttribute() Then
Do
Response.Write(xNav.Name & ": " & xNav.Value & "<br>")
Loop While xNav.MoveToNextAttribute()
xNav.MoveToParent()
End If
XPathNavigator class provides a bunch of properties to retrieve information about current node. The following table describes some frequently used properties:
| Property | What it does? | Example |
Name | Retrieves node's name |
Response.Write(xNav.Name) |
Value | Retrieves node's value |
strNodeValue = xNav.Value |
NodeType | Retrieves node type as XPathNodeType enumeration, such as Element and Attribute. |
Select Case xNav.NodeType
Case XPathNodeType.Element
strNodeType = "An element"
Case XPathNodeType.Attribute
strNodeTyoe = "An attribute"
End Select |
HasAttributes | Checks whether the current node has any attributes. Unlike MoveToFirstAttribute(), it does not move the cursor position. |
If xNav.HasAttributes Then
xNav.MoveToFirstAttribute()
...
End If |
HasChildren | Checks whether the current node has any child nodes. Unlike MoveToFirstChild(), it does not move the current position. |
If xNav.HasChildren Then
xNav.MoveToFirstChild()
...
End If |
Iterating through selected nodes
XPathDocument object is optimized for XPath processing, therefore it is recommended to navigate the cursor using XPath language. The XPathNavigator provides Select method to query the XML document using an XPath string. The method will return an XPathNodeIterator object.
The XPathNodeIterator is a special object for forward-only iteration through the resultant node set. The MoveNext method will move the cursor to the next node in the set. It will return true if the move is successful or false if the end of node set has been reached. The Current property of xPathNodeIterator is used to extract information about the current node. It will return an XPathNavigator object, so we could use XPathNavigator properties (shown in the previous table) to retrieve individual information from the node.
For instance, the following code will invoke Select method to select all answers of the first multiple choice of the quiz in quiz.xml. Then it will iterate through the resultant nodes using XPathNodeIterator object and print each node's name and value.
Dim xNodeIterator as XPathNodeIterator
xNodeIterator = xNav.Select("/quiz/mchoice[1]/answer")
Response.Write("Number of nodes: " & _
xNodeIterator.Count.ToString() & "<br>")
While xNodeIterator.MoveNext()
Response.Write("Node Name: " & XNodeIterator.Current.Name & _
"Node Value: " & xNodeIterator.Current.Value & "<br>")
End While
The Count property as in the previous code, is to count the number of nodes in the node set. To get that figure, it will transparently iterate through the set, so be very wise when to use it! Alternatively, in the XPath Analyzer script, I use an Integer variable, named intTotalNode to do just the same thing but with much less overhead.
RenderTree function
RenderTree is an iterative function to recreate a portion of XML document. The function will start from the current node, as indicated by the XPathNavigator object, and traverse all the way down through any attributes and any child nodes, exhaustively.
Although the scripts have been heavily commented, I present a block of algorithm to make the function easier to understand.
Function RenderTree
Loop through all sibling nodes
If current node is a text node
Print node's value
If current node is a comment node
Print node's value with its opening & closing tags
If current node is anything else
Print node's opening tag
If current node has any attributes
Loop through all attributes
Print attribute's name and value
End Loop
If current node has any child nodes
Call this function recursively
Print node's closing tag
End of Loop
End of Function
There is a RenderHTMLSpace function, which does a simple task of returning a number of or 'space' in HTML. Back to classic VB programming, there was a string function that does the same thing. But I could not find similar function in .NET. Anyone could help?
Displaying the Result
The script displays a table with three columns: node, value/descendant, and attributes.
- The node column could contains elements, attributes or both. Elements are indicated with
<> sign, attributes with = sign, comments with <!> sign, and text with Abc sign.
- The value/descendant column contains node value or any descendants of the current node.
- The attributes columns contains a list of attributes if the corresponding node is an element and has attributes. If the node is an attribute, this column is not available, as indicated by
n/a sign.
All results are stored temporarily in a DataTable object with three String-typed columns. Each node is stored as a row in the DataTable. The result table is rendered using Repeater control by data-binding the Repeater with a DataTable object.
Conclusions
This article presents a script to analyze XPath query against an XML document. The scripts uses XPathDocument, XPathNavigator, and XPathNodeIterator classes intensively. The XPathDocument is a resource-efficient XML reader optimized for XPath query. Navigation through the XML is handled by a cursor-like mechanism using XPathNavigator object. The XPathNavigator object could also execute XPath query and return the resultant node set as XPathNodeIterator, a special object used to iterate through the node set.
Currently, he is in Singapore doing a contract work for a multinational company. During weekend, he is busy exploring Singapore with his lovely fiance to find the best food.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




