What is Lucene.Net?
Lucene.Net is a high performance Information Retrieval (IR) library, also known as a search engine library. Lucene.Net contains powerful APIs for creating full text indexes and implementing advanced and precise search technologies into your programs. Some people may confuse Lucene.net with a ready to use application like a web search/crawler, or a file search application, but Lucene.Net is not such an application, it's a framework library. Lucene.Net provides a framework for implementing these difficult technologies yourself. Lucene.Net makes no discriminations on what you can index and search, which gives you a lot more power compared to other full text indexing/searching implications; you can index anything that can be represented as text. There are also ways to get Lucene.Net to index HTML, Office documents, PDF files, and much more.
Lucene.Net is an API per API port of the original Lucene project, which is written in Java even the unit tests were ported to guarantee the quality. Also, Lucene.Net index is fully compatible with the Lucene index, and both libraries can be used on the same index together with no problems. A number of products have used Lucene and Lucene.Net to build their searches; some well known websites include Wikipedia, CNET, Monster.com, Mayo Clinic, FedEx, and many more. But, it’s not just web sites that have used Lucene; there is also a product that has used Lucene.Net, called Lookout, which is a search tool for Microsoft Outlook that just brought Outlook’s integrated search to look painfully slow and inaccurate.
Lucene.Net is currently undergoing incubation at the Apache Software Foundation. Its source code is held in a subversion repository and can be found here. If you need help downloading the source, you can use the free TortoiseSVN, or RapidSVN. The Lucene.Net project always welcomes new contributors. And, remember, there are many ways to contribute to an open source project other than writing code.
Welcome to the second article
Hey i would just like to welcome you to my second article on code project. For those of you who seemed to have stumbled upon this first, check out my first article Introducing Lucene.Net. The goal of this article is to introduce you to Lucene.Net Analyzers, more about on how they work and how the affect your searching.
What are Analyzers?
An Analyzer has a single job, and that is to be a advanced word breaker. Which an object that will read a stream of text and break apart the words into objects called Tokens. The Token class will generally hold the results of the analysis as individual words. This is a very brief summary of what an Analyzer can do and how it affects your full text index. A good Analyzer will not only break the words apart, but it is also performs a transformation of the text to make it more suitable for indexing. One simple transformation an Analyzer can do is to lowercase everything it comes across, that way your index will be case insensitive.
In the Lucene framework there are two major spots where an Analyzer is used, and that is when indexing and then searching. For the indexing portion, the direct results of the Analyzer is what gets indexed. So for example, in a previous example of an Analyzer that will convert everything to lowercase, if we come across the word "CAT", the analyzer will output "cat", and in the full text index, a Term of "cat" will be associated with the Document. For an even bigger example if we use an Analyzer that will break the words apart with the spaces, and then the Analyzer will convert it all to lowercase the follow the results should look something like this.
NOTE: The brackets show the different Tokens returned from the Analyzer.
Source Text
The Cat in the Hat.
Analysis Output
[the] [cat] [in] [the] [hat.]
Now, when you are searching, most of the time you will be using the QueryParser class you will use to construct the Query object that you will use to search the full text index with. Part of using the QueryParser class, is that you will have to supply an instance of an Analyzer to the QueryParser, The QueryParser will use the Analyzer to normalize the Term or Terms that you will actually be querying for.
Now there is a relationship between the Analyzer that works with the indexing process and the Analyzer that works with building the Query object. Most of the time this will be the exact same kind of Analyzer will be used to do both of the jobs. This is because during the search process, it will only match terms that are exactly the same as what is in the index, this includes case sensitivity. according to the index, when you index the Term "cat", it is considered a completely different term than the word "Cat". This includes punctuational as well. So like in our Analysis sample above the output of [the] [cat] [in] [the] [hat.]. if we were to directly search for the word, "hat", this document would not be a match, because what is index is the Term [hat.] (with a period).
The point here is that the Terms being indexed must be the same as the Terms that you are searching with. This can be achieved by using a consistent method of analysis in both indexing and searching.
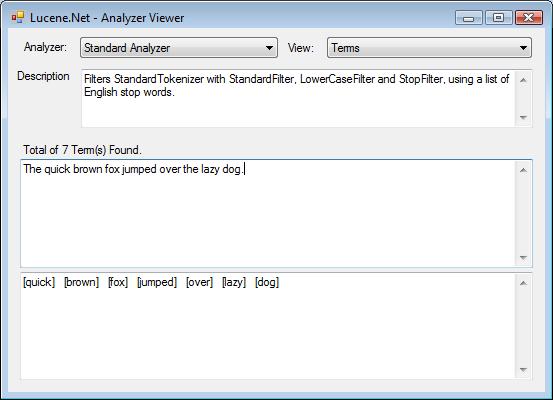
The Analyzer Viewer Application
Attached to this article is the the Analyzer Viewer application, that I made. Attached are both the source and a ready to run binary of the application.. The sample is more like a little utility to see how the basic Analyzers included with Lucene.Net will view text. The application will allow you to directly input some text, and it will show you all the results of the text analysis, and how it split them up into tokens and what transformations it applied.
Some interesting things to looks at include, typing in email addresses, numbers with letters, numbers alone, acronyms, alternating cases, and just anything else you want to play with to see how the indexing process goes.
The Built-in Analyzers
Lucene.Net has several different built-in analyzers. Each has it's own uses, here's a list of the built-in analyzers.
KeywordAnalyzer
"Tokenizes" the entire stream as a single token. This is useful for data like zip codes, ids, and some product names.
WhitespaceAnalyzer
An Analyzer that uses WhitespaceTokenizer.
StopAnalyzer
Filters LetterTokenizer with LowerCaseFilter and StopFilter.
SimpleAnalyzer
An Analyzer that filters LetterTokenizer with LowerCaseFilter.
StandardAnalyzer
Filters StandardTokenizer with StandardFilter, LowerCaseFilter and StopFilter, using a list of English stop words.
PerFieldAnalyzerWrapper
This analyzer is used to facilitate scenarios where different fields require different analysis techniques. When you create an PerFieldAnalyzerWrapper object you must specify an analyzer to use for default, then use AddAnalyzer(string fieldName, Analyzer analyzer) to add a non-default analyzer on a field name basis.
How Does This Work?
An Analyzer is an object that inherits from an abstract base class called Analyzer. The Analyzer class lives in the Lucene.Net.Analysis namespace. To implement a custom Analyzer you only need to implement one method called TokenStream. Which takes two parameters, a string of the field name that will be passed to you, and a TextReader object that will contain the text to be read. The signature will be as follows:
public override TokenStream TokenStream(string fieldName, System.IO.TextReader reader)
{
}
An Analyzer builds a TokenStream, which is simply just a stream of Token objects. So when an analyzer get's used, it will return a TokenStream object that you can use to iterate over the tokens that will be returned from the analysis. Here we are introducing two new classes to become familiar with. The first being a TokenStream and the second being a Token. The summary from Lucene's documentation are
TokenStream - A TokenStream enumerates the sequence of tokens, either from
fields of a document or from query text.
Token - A Token is an occurrence of a term from the text of a field. It consists
of a term's text, the start and end offset of the term in the text of
the field, and a type string. The start and end offsets permit
applications to re-associate a token with its source text, e.g., to
display highlighted query terms in a document browser, or to show
matching text fragments in a KWIC (KeyWord In Context) display, etc.
The type is an interned string, assigned by a lexical analyzer (a.k.a.
tokenizer), naming the lexical or syntactic class that the token
belongs to. For example an end of sentence marker token might be
implemented with type "eos". The default token type is "word".
Basically a TokenStream is a way to provide access to a stream of Tokens, and a Token simply just holds some information just as some text representing a Term, and the Term's field as well as the offset of where this Token is located in the original text.
How does an Analyzer Create a TokenStream?
The TokenStream is an public abstract base class. There are two other two other abstract classes that inherit from the TokenStream class that take the TokenStream a little bit further. And they are the Tokenizer and the TokenFilter classes. As I mentioned earlier both of these classes are implementations of a TokenStream class, and also both of these are also abstract.
These Tokenizer and TokenFilter classes have different jobs in the the analysis of the text, These two classes were created to separate the responsibility of what an Analyzer does. The Tokenizer acts like the word breaker, it's main job is to process the TextReader and return how it breaks the words into Token objects. On the other hand is the TokenFilter class. When you create an implementation of a TokenFilter class, it will expect a inner TokenStream as a parameter of the constructor. It's more like having a TokenStream wrapped around another TokenStream is what I'm trying to get to. When you call to get the next token from a TokenFilter, it will call the input TokenStream to get the next Token from it, then it will evaluate the Token and it will perform different operations with the information. Some examples of what a TokenFilter can do is convert all the text to lowercase, or the TokenFilter can decide that the Token is not important and discard it so it does not ever get indexed or seen. The TokenFilter is more about filtering the content from a TokenStream.
When an Analyzer creates a TokenStream, they are usually just creating a single Tokenizer object to break the words and then using one or more TokenFilters to filter the results of the Tokenizer.
Implementations of a Tokenizer.
As i mentioned earlier the Tokenizer class is an abstract base class of a TokenStream. Lucene.Net provides a few implementations of a Tokenizer that it uses in some of the Analyzers. Here is a couple of them and a small description of each.
KeywordTokenizer - This Tokenizer will read the entire stream of text and return the whole things as a single Token.
CharTokenizer - This is an abstract base Tokenizer than is implemented by two other Tokenizers, this is a good starting point to create your own Tokenizer. It has a single method that you must implement and that is IsTokenChar(char c), and returns a Boolean. if it is a character that belongs to a Token. once you hit something that isn't a Token character the method would return false, and then it will create the Token depending upon where you split the Token characters.
WhitespaceTokenizer - This Tokenizer inherits from the CharTokenizer and it breaks the words just according to white space.
LetterTokenizer - This Tokenizer inherits from the CharTokenizer and it breaks the words according to just letters, the moment it hits a number of a symbol or white space it ignores these and only creates a Term with just the letters.
LowerCaseTokenizer - The LowerCaseTokenizer inheirts from the LetterTokenizer and just performs and extra step of converting the results returned to lowercase.
StandardTokenizer - This Tokenizer is a pretty good choice for most European languages. This is a grammer based Tokenizer that will reconize email addresses, host names, and acronyms.
Implementations of a TokenFilter.
As i mentioned earlier the TokenFilter class is an abstract base class of a TokenStream. Lucene.Net provides a few implementations of a TokenFilter that it uses in some of the Analyzers. Here is a couple of them and a small description of each.
LowerCaseFilter - the LowerCaseFilter will take the incoming Token<code>s and will convert all the letters to lower case. useful for case insensitive indexing and searching.
StopFilter - the StopFilter will filter out 'stop words'. Stop words are defined as common words that should be ignored, such as 'a' 'and' 'the' 'but' 'so' 'also' etc.., A constructor of the StopFilter requires you to pass in an string array that contains a list of the stop words you want to define.
LengthFilter - The LengthFilter is useful if you want to remove words that are too long or too short from being returned.
StandardFilter - The StandardFilter is used to normalize the results from the StandardTokenizer.
ISOLatin1AccentFilter - the ISOLatin1AccentFilter is a filter that replaces accented characters in the ISO Latin 1 character set
(ISO-8859-1) by their unaccented equivalent. The case will not be altered.
For instance, 'à' will be replaced by 'a'.
PorterStemFilter - the PorterStemFilter transforms the token stream as per the Porter stemming algorithm.
Note: the input to the stemming filter must already be in lower case,
so you will need to use LowerCaseFilter or LowerCaseTokenizer farther
down the Tokenizer chain in order for this to work properly! To use this filter with other analyzers, you'll want to write an
Analyzer class that sets up the TokenStream chain as you want it.
To use this with LowerCaseTokenizer.
Hierarchy Graph
Here is a cheap hierarchy graph constructed of some of the Hierarchy starting with a TokenStream class.
* TokenStream
* Tokenizer
* KeywordTokenizer
* CharTokenizer
* WhitespaceTokenizer
* LetterTokenizer
* LowerCaseTokenizer
* StandardTokenizer
* TokenFilter
* LowerCaseFilter
* StopFilter
* StandardFilter
* PorterStemFilter
* LengthFilter
* ISOLatin1AccentFilter
Points of Interest
I think this is a very interesting topic, because this greatly affects how your users will search and what kind of results they will be back. I wanted to create a custom analyzer with this article but i felt that this was more about how they worked, And it will give me an excuse to make another article again :)
I hope this was interesting to you and I hope I was as clear as can be, and again, if your not understanding what I'm trying to communicate just point it out to me, thanks!
History
1/2/2009 - Initial Released Article
I'm a proud father and a software developer. I'm fascinated by a few particular .Net projects such as Lucene.Net, NHibernate, Quartz.Net, and others. I love learning and studying code to learn how other people solve software problems.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




