Introduction
In part 2 of the code optimization tutorial we will have a look at optimization techniques which can be applied on algorithms that use threads.
I will choose the same problem as in the previous article, this time taking advantage of multiple processor cores:
For every number n between 1 and 1000000 apply the following function:
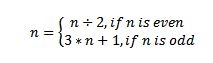
until the number becomes 1, counting the number of time we applied the function.
This algorithm will be executed for all the numbers between 1 and 1000000. No input number from the keyboard will be read and the program will print the result, followed by the execution time (in milliseconds) needed to compute the result.
Test machine will be a laptop with the following specs: AMD Athlon 2 P340 Dual Core 2.20 GHz, 4 GB of RAM, Windows 7 Ultimate x64.
Languages used for implementation: C# and C++ (Visual Studio 2010).
In this article the Debug versions of the programs are not taken into account anymore.
Prerequisites
Article: Code optimization tutorial - Part 1.
Knowledge about WinAPI is recommended, but not mandatory.
Implementation
We have NumCores processor cores.
I will use a queue to store the numbers to be processed. Also, for each available processor core, a worker thread is created. All worker threads operate(just reading) on this shared queue. Each worker thread extracts a number from the queue and computes the required value. The numbers are written in the queue by the main thread, which is the only thread that writes to the queue. The worker threads run until all numbers have been processed.
For the computation associated with each number, in C++ I will use the algorithm presented in the previous article and in C# I will use the algorithm proposed by anlarke:
for (iCurrentCycleCount = 1; iNumberToTest != 1; ++iCurrentCycleCount)
{
if ((iNumberToTest & 0x1) == 0x01)
{
iNumberToTest += (iNumberToTest >> 1) + 1;
++iCurrentCycleCount;
}
else
iNumberToTest >>= 1;
} And here are the results (main_v6.cpp/Program_v6.cs):
As it can be observed, the execution time for the C++
version is very big.
This time is due to:
1) The fact that I use just one queue
shared between NumCore + 1 threads
2) The large number of locks I perform to write/read
the data in/from the queue.
For the first one, to eliminate partially the concurrency
problem between the worker threads, I will use one queue for each worker thread
and the concurrency issue will remain between the main thread and each worker
thread. So, to minimize the time a thread has to wait for another thread to
release its lock, I will split the queue into NumCore queues.
Here are the results(main_v7.cpp/Program_v7.cs):
For
C++ I got a significant improvement in speed. I don’t know why the C# version
slowed down this much.
For
the second aspect regarding the numbers of lock operations, I will choose, instead
of writing 1 number in the queue at a time,
to write 250 numbers at a time(number determined by testing).
Here are the results(main_v8.cpp/Program_v8.cpp):
I got a significant timing improvement in both C++ and
C#.
The execution time in C++ is slower than C# , because for
the synchronization in C++ I use mutexes (implemented in kernel space) and in
C# I use the lock keyword which is
implemented using critical sections (implemented in user space).
I have provided a C++ version that uses critical sections
inside the file main_v8a.cpp. The time for this version is 484.95 ms.
There is one more optimization that can be done: in this
case, because the threads conform to the producer - consumer pattern and we
know exactly the data that will be processed by the program, we can eliminate
the locking of the queues entirely, by loading the data into the queues before
starting the threads.
Here are the results (main_v9.cpp/Program_v9.cpp):
The speed improvement for C++ is noticeable and also, for the C# version we have got an improvement.
Points of Interest
Conclusions of this article:
1. Try not to share data between threads.
2. Try to minimize the number of lock operations because they are
expensive, process your data in chunks, not one by one.
3. If you don’t need interprocess synchronization, use user space
synchronization objects.
4. If your threads behave according to the producer - consumer
pattern, and the data that the producer thread has to provide to the consumers
is known before starting the consumer threads, you can eliminate locking.
Next time, I will discuss about optimizing
a program using SSE, DirectCompute and OpenCL.
History
- 21.06.2012 - Initial release.
- 22.06.2012 - Uploaded code again.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




