Abstract
We present some techniques that may be used to perform computations on general trees implemented in a relational database as a self-joined table in the widely used child-parent format, and we prove the validity of this technique under very general hypothesis. Another, much better actually format.
Introduction
Relational databases are not making much progress lately in the path finding problem in a persisted tree. Vendor specific SQL extensions, such as the CONNECT BY clause in Oracle, are a further step in this area. But the casual developer still finds their performance unacceptable for most real life situations, and it's also not recommended to tight its application to a vendor specific database. It is acceptable to implement different versions of stored procedures or SQLs for different databases, but when all the application logic is based on tree facilities only provided by a specific vendor, it gets much harder to port the application to other database systems. And it's usually true that the clients have not bought the most expensive commercial database systems.
We propose some solutions to the path finding problem, that are not database specific while still giving better performance than some of the database-specific extensions supporting trees.
Changes to the child-parent format to keep the entire path for every node
This part is optional. One can skip this part to the Alternate Format section.
Database structure
The reader should note that the method presented in this section is efficient especially for read-only access to such persisted trees. The write operations complexity is roughly presented in this paper. Also, the alternate format is what you probably are looking for.
For performance reasons, one could try to add to every node the information representing the path to that node from the root of the tree. I don't actually know any applications that could benefit from this, and if I can't find such stuff in a short time, I'll remove this section.
We add a column named Path to the table containing the child to parent links. This column must not be too big, so we'll analyze it's space complexity first. The time needed to compute the Path column values is less important because we primarily discuss here read-only trees.
The Path column should be some kind of bit sequence. Some examples are RAW in Oracle or Binary in SQL Server. We define the Path value recursively (trees are to be processed recursively, isn't it ?):
Path(RootNode) = Null
For nodes other than the root,
Path(Node) = Path(Parent(Node)) + Index(Node, Parent(Node))
where + means concatenation of bit sequences, and Index is the child ordinal in the domain of the parent nodes children list.
Note that the Path will uniquely identify every node in the tree. An unique index on this column might be ok to use, if needed in case a single tree is stored in the table.
All the nodes at a given level will have the Index represented at the same bit size. Let the node count in a tree be denoted by N, let the levels be 0,1,..., L and the max(Index(i)) be Ci, where 0 <= i <= L – 1. If we want we can also define max(Index(CL)) = 0, because the nodes on the highest level have no children. It becomes clear that the bit size of the Index for nodes on level i is equal to ceil(log2(Ci)), where ceil is an integer value equal to the smallest integer greater than or equal to its numeric argument, and log2 is the base 2 logarithm of a specified number.
Having this Path format, we can easily select an entire subtree when given the subroot, searching for nodes where Path(Node).startsWith(Path(SubRoot)) and we also have at each node the information needed to identify the path to the root. But how long must be the Path column to contain this plenty of information?
If the tree is really static (read-only), that the Path size is calculated specifically for it. One can use this approach if he has strong guarantees that there is no need to change the tree structure, or that modifying a column length is an acceptable operation (especially at run-time). Another approach would be to first compute the maximum Path size for a given tree node count. Even if the first approach does not need knowledge about the maximum path size for trees of N nodes, it is still needed to mathematically prove that both approaches are appropriate for real life usage.
Path size bounds
For any given node count N, we find out the worst case for the required Path size, and also compute that maximum Path size value. If we allocate that maximum size for the Path column, then we are guaranteed that no matter how “strange” a tree with N nodes or less looks, it “fits” into our table.
The path size for any given tree TN with N nodes and L levels is equal to
PathSize(T<SUB>N</SUB>) = ceil(log<SUB>2</SUB>(C<SUB>0</SUB>)) + ... + ceil(log<SUB>2</SUB>(C<SUB>L - 1</SUB>))
Note that C0 + ... + CL - 1 <= N – 1, the equality holding when every node in the tree has at most one child with children on his own. We find an upper bound for PathSize(TN) in the domain denoted by the previous inequality.
PathSize(T<SUB>N</SUB>) <= L + log(C<SUB>0</SUB> * ... * C<SUB>L - 1</SUB>)
The arithmetic-geometric mean inequality tells us that
(C<SUB>0</SUB> * ... * C<SUB>L - 1</SUB>)<SUP>1 / L</SUP> <= (C<SUB>0</SUB> + ... + C<SUB>L - 1</SUB>) / L
We deduce that
PathSize(T<SUB>N</SUB>) <= L + L * log<SUB>2</SUB>((C<SUB>0</SUB> + ... + C<SUB>L - 1</SUB>) / L)
<= L + L * log<SUB>2</SUB>((N - 1) / L).
Let the function F : 1..N-1 ---> N be the right part of the upper inequality. We'll find the global maximum for this function on its definition domain. What we need is the derivative:
F'(L) = 1 + 1 * log<SUB>2</SUB>((N - 1) / L) +
L * (1 – N) / L<SUP>2</SUP> * 1 / ((N – 1) / L * ln(2)),
where ln means the natural (base E) logarithm of a specified number.
F'(L) = log<SUB>2</SUB>(2 * (N – 1) / L) – 1 / ln(2)
= (ln(2 * (N – 1) / L) – 1) / ln(2).
F' is a decreasing function, and it has a single root equal to L0 = 2(N – 1) / E, where E is Euler's number, approximately 2.71 (for those interested in high precision arithmetic, see link).
So the maximum value for F is
F(L<SUB>0</SUB>) = F(2(N – 1) / E)
= 2(N – 1) / E + 2(N – 1) / E * log<SUB>2</SUB>((N - 1) * E / 2 (N – 1))
= 2(N – 1) / E * (1 + log<SUB>2</SUB>(E / 2)) = 2(N – 1) / (E * ln(2)).
Update behavior
In order to optimize update behavior, a Path size greater than the actual needed value can be allocated, but it should always be less than or equal to the maximum Path size computed for the maximum number of nodes accepted by the application to reduce wasted space. The format of the Path field need not be exactly the one described previously. Space can be inserted between fields as necessary in order to allow growth of some levels. For example, if inserts are more likely to appear at some levels of the tree, than more free space should be allocated to those parts of the Path field. If a node is inserted into a level and the part of the parent's Path field cannot hold the new children count, than all the Path values must be changed to accommodate a new bit corresponding to the parent's level.
The most important thing to take care of is avoiding node inserts that cause some Paths not to fit anymore into the Path field. As proved before, this can be avoided computing the maximum path size according to the formula 2(N – 1) / (E * ln(2)). As long as the node count is less than or equal to N, this path size will accommodate any updates of the tree, be them inserts or removes.
If a node is removed or inserted, all the Path values of its subtree must be updated accordingly. So leaves can always be removed in O(1) time, and leaves can be added in O(1) time only if the Path part of the parent's level can accommodate an incremented value. Otherwise, we have an O(n) time complexity.
Numeric values
If N = 10,000 than the maximum Path size is less than 1.3 Ko, while for N = 1,000,000 we get the 130 Ko bound.
Oracle provides support for bit sequences in the UTL_RAW package, while SQL Server seems to have more limited functionality related to them.
In order to ask queries, for instance, of the form WHERE Path starts With '11011', one could cast the Path to a hex string, and check if the Path is lexicographically between D8 and DF, in case the database in use does not provide enough support for bit sequences manipulation.
Further study
First of all, some averages must be computed, especially for the Path size.
A few transformations from a general tree T to a binary tree B with the property that, whenever x is a child of y in T, x remains a descendent of y in B are evident. These are based on adding new, fake nodes, into the tree to make it binary in case a node has more than 2 children. Some more sophisticated transformations could try to keep the fake nodes grouped into complete binary subtrees.
One method would be to associate the 0 bit to left edges, and the 1 bit to right edges.
Another idea would be to overlay the binary tree on top of the Stern-Brocot tree, and use the fraction m/n as the Path column (actually, there could be 2 integer columns). If the binary tree has L levels, than m and n could get equal to FL, where F is the Fibonacci sequence. One advantage of this structure is that if one wants to find a rational number between other two (reduced) rational numbers, it only has to look “between” them.
If one wants to limit the values of m and n, the Farey series could be used instead. This one is actually a part of the Stern-Brocot tree. It could also be interesting to study how changes of the initial tree are reflected in the Stern-Brocot tree.
Alternate format
An alternate way to represent a tree in a relational database is to actually keep an integer positive index for each node. Let's call this column NodeIndex. If N is the node count of the tree, let's call the nodes 0, 1, ..., N – 1. The whole idea sustaining the format presented in this section is that the sequence 0, 1, ..., N – 1 must be the Depth-First Traversal of the tree. Well, this information is not sufficient to uniquely identify the rooted labeled tree amongst all the nn - 2 labeled trees of N nodes. To solve this inconvenience, we add a second column to the tree table, named RightChildIndex that is actually the index of the rightmost child of the current node. For the leaves, RightChildIndex is equal to NodeIndex.
Let's give an example:
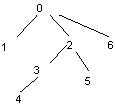
| NodeIndex | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|
| RightChildIndex | 6 | 1 | 5 | 4 | 4 | 5 | 6 |
Given a NodeIndex i one can easily perform the following operations described in Oracle SQL. All of these have been tested with the well-known Employee table.
For instance, given the node 2, the select asks for all the nodes with indexes between 2 and 5, inclusive.
If the root itself doesn't need to be returned, the inequality i <= T1.NodeIndex must be changed to strict inequality.
- Get the path from the root to the given node:
SELECT t1.*
FROM employee t1, employee t2
WHERE t1.nodeindex <= i
AND t1.rightchildindex >= t2.rightchildindex
AND t2.nodeindex = i;
For instance, given the node 3, where condition searches for nodes with NodeIndex <= 3 and RightChildIndex >= 4
- Get the immediate children of a give node:
SELECT t1.*
FROM employee t1, employee t2
WHERE t1.nodeindex > i
AND t1.nodeindex <= t2.rightchildindex
AND t2.nodeindex = i
AND 0 = (SELECT COUNT (1)
FROM employee q
WHERE nodeindx < q.nodeindex
AND q.nodeindex < t1.nodeindex
AND t1.rightchildindex <= q.rightchildindex
AND q.rightchildindex <= t2.rightchildindex);
One can improve the performance of this operation by keeping the tree in both this alternate format and the widely used child-parent format simultaneously.
- Insert a node as a child of
i:
UPDATE employee
SET employee.nodeindex = employee.nodeindex + 1
WHERE employee.nodeindex > parentnode;
UPDATE employee
SET employee.rightchildindex = employee.rightchildindex + 1
WHERE employee.rightchildindex >= parentnode;
INSERT INTO employee
(nodeindex, rightchildindex, NAME, comments)
VALUES (parentnode + 1, parentnode + 1, nodename, nodecomments);
- Delete the node with
NodeIndex i:
DELETE employee
WHERE employee.nodeindex = i;
UPDATE employee
SET employee.nodeindex = employee.nodeindex - 1
WHERE employee.nodeindex > i;
UPDATE employee
SET employee.rightchildindex = employee.rightchildindex - 1
WHERE employee.rightchildindex > i;
The foreign key RightChildIndex referring to NodeIndex has to be a deferred one if the delete operation is to be implemented this way. That means that it has to be only enforced at the end of the transaction, and not during it.
Further study
We could also want to store the Breadth-First Traversal of the tree, but I haven't found any useful applications yet.
Tree archives or composites
The need to “archive” tree structures arises in some applications, especially those provide traceability for some tree structures. If a tree version that existed at some point in time is not frequently accessed, then some shorter encoding for the tree can be used to store in the database. I recommend the Prüfer-Like Codes. With most of these codes, the structure of a tree with N nodes is encoded in N – 2 integers in linear time. Be aware that these encodings only store the tree structure, and not the information in the nodes. That information has to be kept separately anyway.
A complete C# implementation of the algorithms descried in An encoding scheme for labeled trees is attached to the article. I've also made a Java implementation of the algorithm.
A general class TreeNode seems to be missing from the .NET framework (the one in Windows forms doesn't help me much), so I created one with the minimal functionality required.
public class TreeNode {
public void Add(TreeNode child)...
public TreeNode Parent...
public int ChildCount...
public IList Children...
}
The TreeEncoder class has to be initialized with a tree in the adjacency lists representation. The single method of interest is:
public int[] encode()...
It actually codes the tree with n nodes into an array of integers of n – 2 length.
The TreeDecoder class knows to decode a tree from it's compact representation
public IList[] decode()...
public int diameter()...
public int radius()...
and to compute the diameter and radius of a tree directly from it's code, without first reconstructing the tree into memory.
Conclusions
A broad set of operations on trees can be efficiently implemented using only basic tree traversal algorithms. It would be interesting to further study how the known tree encodings can be efficiently applied in relational databases.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





 If you calculate the complexity of the insert/update algoritm, and then suggest a FEW THOUSAND records in the provided solution - you are cracking me up.
If you calculate the complexity of the insert/update algoritm, and then suggest a FEW THOUSAND records in the provided solution - you are cracking me up.
