Table of contents
This article proposes a new approach to profiling that favors interpretation over exhaustive and complicated results. At the expense of easy-to-use instrumentation routines, mainly represented in three keywords (activity, task, worker), you instrument and compile your C++ application against the "Collector DLL", then easily observe and interpret results using a preset of analysis-compare tools.
Update
For the readers of the initial version of the article (6th of November), this update (Nov. 13th) comes with an "extension" use-case in which I take last month's Grebnev's "Testing concurrent container" article code as a real-world case in which to apply Easy Profiler. A New Misc.zip package contains the missing CHM help file, and the PNG sources of the Ribbon command icons used in the Observer application. An "export and customization" sub-section was added along with a discussion about the color system issue in the "Limitations and Strategy" section.
This tool was developed amidst continuing frustration towards existing profiling solutions and the urgency brought about by personal/work projects that were/are in need of tremendous profiling. Standard, "powerful" profilers provide us with the automatic performance collection scheme that frees us from the "supposed" burden of having to manually insert code. Application sampling, measurement code injecting, etc. - in all cases, the performance of the target application is significantly affected, and we have to deal with huge profiling data pertaining to every function/class call, etc. Interpretation is too difficult. We can only detect singular phenomenon, but never "architectural-level defects". Superstatistics are impossible to aggregate. Time gained at collection-time is simply lost trying to deal with the quantitative and granular output data. The move was sequent to an instant observation that any improvement to these automatic profilers would either face too challenging aggregation-cases to be supported or too complicated user-assisted (aggregation/restriction) UI-processes to not fall with the same time-loss. Hence the resort to compile-time premise: Handful of instrumentation routines are available to you to easily describe your code situation, and a Preset of multiple analysis-compare tools is available to instantly apply to a group of features described by the instrumentation code and give their result in a qualitative chart.
Usage
The tool presented here comprises two components:
- The Collector: A "pure" DLL that exposes the instrumentation routines.
- The Observer: An MFC 9.0 application used to "observe" and analyze the XML files containing the performance measures as created by the Collector.
So as to start profiling your application, you only need to compile it with the Collector DLL, run it, then open the resulting XML file using the standalone Observer application.
Thus, you find both the header file declaring the IRs and the Collector .lib module for the compilation process. Add the header to your project, add the .lib, and deploy the DLL next to your project executable.
Of course, you get the source code of everything so you can make changes that meet your particular needs. Note that there is a readme.txt file to follow in the downloadable package. Not to forget a CHM help file you can resort to:

As implied, this DLL contains the implementation of the IRs. First, choose a region of code to profile, name it, and surround with the following two calls: surrounded code can be a simple call that however results in complex scenario.
startRegion(regionName, collectionType);
flushRegion(regionName, outputDir, outputType)
When flushRegion is perceived, all measurements taken will be written to a single file. The region name is a signature that helps the Observer compare between tests. The typical scenario implied is that you instrument your code, test interpret the results, decide on particular changes, preserve the instrumentation code, then do the test again, and then ask the Observer to perform compare tools upon the two "test instances" of the same region.
Region tests can be stored in one or separate files. Creation time will be set as the description value for the test. The Observer will help discover any tests and make them available to you whenever you'd like to perform an analysis/compare operation, because such operations do act on a group of features of the same region-test or on a matched group of features belonging to different tests of the same region:
To describe the code-architecture of the target region, there are three "features" available:
- Activity: Surround the sub-bloc with
startActivity(activityName) and stopActivity(activityName): This sub-bloc is supposed to execute only once during the region-execution lifetime. You can describe the point event inside an activity using insertCheckpoint(pointName, activityName). - Task: Surround it with
startTask(taskName) and stopTask(taskName): This sub-bloc is meant to execute multiple times (inside a loop), and concurrently. - Worker: Surround the code with
startWorker(workerName) and stopWorker(workerName): It is meant to model when a thread is starting to execute something and when it is sleeping.
How can you use this ?
OK. Suppose you have a particular slow portion of code that makes calls to three separate functions. This is how it works:
void SlowCode()
{
startRegion("my region", 'v')
startActivity("main")
func1();
insertCheckpoint("func1 finished", "main")
func2();
insertCheckpoint("func2 finished", "main")
func3();
stopActivity("main")
flushRegion("my region", "C:\tests", 's')
}
So here is a region named "my region" containing a feature instance of type activity and named "main". Your code may resort to tasks and workers in case of complex situations.
Examining the IR header file, you can discover macros wrapping direct calls to the IRs. This is so you can easily get rid of the impact of the instrumentation routines, by undefining a particular symbol and hence avoiding the need to delete references in the source code.
The result of a test run is an output XML file containing measurement values. Example:
This is the part of the tool responsible for opening the test data and allowing quick analysis/compare operations:
The idea is to open the test data, select an analysis/compare operation, along with its "operands" (features of the region), click the button, and have an instant chart in front of you.
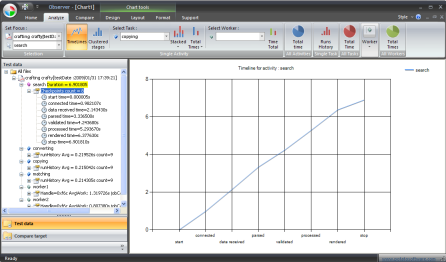
The left pane (Test data) contains a tree view of the raw data read from the XML files opened. The central view is a chart control. The contextual tabs on the top ribbon bar help customize the chart (like Excel does). The home tab is for opening and editing test-data.
The Analysis tab is there to select a region-test, particular features in it, and choose the operation button.
Examples (there are in total 14 analysis scenarios):
- You select a particular feature, then display a timeline view of its checkpoint.
- You select a task and display its "runs" history.
- You select a feature and display, in a pie chart, the contribution of each task to the execution of that feature.
Thus, the result is always a chart to visualize. The goal is to shorten the time to interpretation and decision. No need to export values and resort to a spreadsheet.
The compare ribbon tab and the compare target left panel both act together. To perform any compare operation naturally, you have to select two tests of the same region. Observer helps you discover all available signatures (region name) in all opened tests:
Thus, all you have to do is to select the region name, then select the group of tests to compare using the checked Tree control before choosing the group of features that are the operands of the desired operation.
In all charts, time is always in the Y-axis (whether it is about time values or time-duration value). The X axis and the data series differ according to the analysis/compare operation. Try to use your logic to decrypt the chart, otherwise put a message in the article forum.
Profiling your code, visualizing the performance of a certain code interaction, you are surely interested, afterwards, in customizing the chart figure, and communicating it to someone else.
The "chart tools" contextual Ribbon tab is where you can find the commands that control the "appearance" of the chart. They do not act like regular "contextual tabs" I must confess (regular = as described by the Fluent UI reference).
The Design tab helps you alter the "design" of the chart. For example, you can modify the chart type or choose the color palette. Other commands can provide other options (3D, rendering quality).
The layout tab controls the placement of the different elements composing the chart, i.e.: the chart title, legend, data labels, axes, and gridlines.
Finally, the Format tab is probably the most interesting commands group for you to customize the chart. If you have already used Excel, then the philosophy is the same. First, select the item to edit its format using the "select item" combobox at the "Current selection" Ribbon panel. The text of that element can be edited using the bottom "change text" editbox. This can be useful in case you do not like the automatic name of the title of a certain data series. If the element has a certain shape, then you can format that shape using the "shape fill" panel. If it has an outline, an Outline panel is there to format the color, style, and size. If it is a text, then a standard "Font" panel is there for you. Other options include element alignment, docking..
Exporting the chart is done through the "Save as" button in the main Ribbon button menu. Choose a target file path and select one among six different image formats.
Now to the use-cases. You have to help me here, because I don't want to copy and paste a long content I already authored at my website. I advise you to read it. The first link is even written in the form of a fictitious and funny story. I will limit myself to putting the important notes here.
This was a basic case. Instrumentation is both a segregation and aggregation process. In most cases, this means that you are the one who wrote the instrumented code or at least you know it. The developer knows in advance where to look for the phenomenon cause.
In the following resulting chart:
Jeff asked an imported question: "..This is really strange. If it is not because of the way how the data is being loaded, how is it that the other operation stages are processing fast the same flow of incoming data?"
It is not evident how to come out of such a question, if it not possible to repeatedly combine some measures, visualize them qualitatively... with the ease of a few clicks.
As you can see, the instrumentation routines are used to describe the code architecture of the server application. The region features (activities+tasks+workers) reflect the skeleton elements of the code. Thus, the analysis/compare tools are used to reveal interactions between the suspect elements of that architecture and consequently criticize the code behavior at its higher level.
In the above chart, a particular analysis tool is used to ask the question, how much does the task named "decoding" contribute to the overall execution of the thread named "worker1". Hence a simple interaction between a worker and a task.
Not only can this approach lead to resolve some performance bottlenecks, but it can also help validate some decisions before embarking into the hazards of an expensive code change.
Some notions can also be measured. Think of the interaction activity-works and how it can be used to assess the real gain from a parallel code.
Since this article publication, I felt something is missing. Even though I've provided the user with two use-cases, I have forced him to a particular code situation and even code that is either demo-ised (fictitious) or unknown. So nothing is better than taking a real use case that most of the readers can comprehend. It is for this reason that I've chosen an interesting article that appeared on last month's vote list, and I will feature the tool by instrumenting the code in it.
The article is: "Testing concurrent container"; you should not have missed reading it, but as I do not rule out this, you can trust the following paragraphs in learning what you are only required to learn about for the sake of our goal.
Download the code. You'll find a "main" file and other files containing different implementations of concurrent containers. A container is an object where we can store certain types of other element objects. STL's map object is a sample container, but it is not concurrent because you can not make simultaneous inserts without the possibility of some sort of problem that can affect the data or even the calling process. std::vector is the same. So a concurrent container is, simply, one that adds synchronization. However, thread contention and the resulting thread blocking can affect the performance of the read/write access operation. So a successful concurrent container is one that minimizes "blocking" without, of course, wronging the principle of serializing threads access to shared elements. Hence the article code is like a test benchmark of four methods:
- Intel TBB
- CS Table
- Spin Lock
- Lock Pool
The type of container object named g_map and consumed in later tests is controlled by macros for compile-time switching on the different implementation:
#ifdef TEST_CS_TABLE_CONTAINER
CST_map_t < labelong, test_container_element,LOCK_TYPE > g_map;
#elif
The macros declaration is found in stdafx.h:
#define TEST_TBB_CONCURRENT_CONTAINER
The container exposes the following "interface": insert/modify/read/delete. Three different types of test-threads that "derive" from the base parameterized Test_worker class will perform different types of operations:
Container_builder (will perform inserts and deletes after filling the container) Writer (will perform modify operations: it picks a random access, then retrieves and modifies the corresponding element if found) Reader (will perform read operations)
So all that the main function does is launch an instance of the Container_builder thread along with a set of Writers and Readers that will operate simultaneously until they perform the number of iterations they are told to perform. Measures are then taken for the average read/write operation; duration then, the test is done again with different container types until all is finished. The author has given us the following chart that was surely obtained by resorting to an external program (like a spreadsheet) and manually exporting the measures obtained from the many runs.
Easy Profiler is meant to intervene here, to alleviate the burden of recreating the "measurement code" (look at the test_iteration method, the Performance_counter_meter class, and the QueryPerformanceCounter behind it). There is manual export of "measures" to an external program where the interpretation has to happen. If the current implementation fails in different ways, I trust the approach is OK. So, let's see how things can be done.
Firs,t we take the steps needed to integrate the Collector module to the target code. In the "Deploy module" zip, you will find the routines.h, collector.lib, and collector.dll files. Add the parent folder to your project includes + the additional library paths, and #include routine.h in stdafx.h.
Surround main.cpp with the following two calls:
_startRegion("containers test",'v')
_flushRegion("containers test","C:/profTests/",'s')
A region is a way to limit the instrumentation to the only calls that fall with these two calls. The idea is to be able to restrict profiling to the only suspect portion, hence get rid of "noise" data that would be resulted by other portions that executes during the same test-run. The code here is small, no need to "supertarget" a region or to see the utility in effect.
Now you can run the application. A new XML file is created, but it contains no measures.
As previously said, the region name is like a signatures that will aid the Observer in comparison operations. The hypothesis is that the developer first instruments his code, visualizes and interprets the results, then provokes a code change that does not alter the instrumentation code, then starts to observe the difference.
In our situation, what pilots that code change is the different implementation of the concurrent container. After the instrumentation is in place, we run different tests by switching to a particular container implementation, then opens the resulting files and changes the description from the "default time date" to the name of the container method itself.
The description is very important afterwards for comparison operations. Comparison tools are available through the "compare Ribbon tab's commands". First, you need to be assured that all region-tests are open, then set the focus to the desired region signature:
The bottom operand combo box is automatically filled with "feature" names of the first identified region test. Also, the compare target left panel is filled with all region-tests that match the same specie fed region name.
The call to startRegion supplies the value 'v' (verbose) to the second parameter. This is reflected in the XML attribute highperformance=false at serialization. This is to disable the split-and-merge mechanism that can be activated in case of very performant code that otherwise generates gigabytes of data measures. Normally, that is the case here too; however, because thread contention is a probablistic phenomenon, I will keep on the statistical approach already used by Grebev but in another way (note that thread collision is probabilistic):
We modify the main function to first fill the container to start the builder thread, keep it constantly running without iteration count limit, then start 8 readers, wait for them until they complete, then start 4 writers and 4 readers, wait again till they complete, then start 8 writers and wait for them till they complete, and finally stop the container builder.
Along the way, the container builder is expected to provoke global scope locking, because insertion and deletion affect the container structure itself. That's all we should worry about the container during the initial 8 readers. But as we start 4 readers and 4 writers, we are additionally provoking element scope locking. The ability to handle a heterogeneous situation should be assessed by examining the difference with the case of 8 writers.
Here are how things are modified along with the instrumentation code:
int _tmain(int, _TCHAR*)
{
_startRegion("containers test",'v')
_startActivity("main")
Container_builder::setup_test_container();
Container_builder* pBuilder = new Container_builder();
HANDLE hBuilder = pBuilder->start(::rand());
_insertCheckPoint("container built","main")
HANDLE readerThreads[8];
for (int i = 0; i < 8; i++)
{
Reader* pReader = new Reader();
readerThreads[i] = pReader->start(::rand());
}
::WaitForMultipleObjects(sizeof(readerThreads)/sizeof(readerThreads[0]),
readerThreads, TRUE, INFINITE);
printf("8 readers\n");
_insertCheckPoint("8-readers","main")
HANDLE readerAndwriterThreads[8];
for (int i = 0; i < 4; i++)
{
Reader* pReader = new Reader();
readerAndwriterThreads[i] = pReader->start(::rand());
}
for (int i = 0; i < 4; i++)
{
Writer* pWriter = new Writer();
readerAndwriterThreads[4+i] = pWriter->start(::rand());
}
::WaitForMultipleObjects(sizeof(readerAndwriterThreads)/
sizeof(readerAndwriterThreads[0]), readerAndwriterThreads, TRUE, INFINITE);
printf("4 readers 4 writers\n");
_insertCheckPoint("4-readers 4-writers","main")
HANDLE writerThreads[8];
for (int i = 0; i < 8; i++)
{
Writer* pWriter = new Writer();
writerThreads[i] = pWriter->start(::rand());
}
::WaitForMultipleObjects(sizeof(writerThreads)/sizeof(writerThreads[0]),
writerThreads, TRUE, INFINITE);
printf("8 writers\n");
_insertCheckPoint("8-writers","main")
_stopActivity("main")
_flushRegion("containers test","C:/profTests/",'s')
return 0;
}
Now create the tests for the different container implementations. Each time, uncomment one of the 4 container macro symbols, compile, then run. If you are less lucky than I an, then you should be able to test all 4 implementations; however since I only have Windows XP and apparently one of the implementations is dependent on a new API function, the following results correspond to three implementations only.
To open all tests together, open the Observer, then press the "Test suite" command from the "Home" tab. Select the "C:/profTests" folder. Activate the "Compare tab" along with the "Compare target" panel. Check all items from the checked tree control, select the "containers test" region and the "main" feature from the focus comboboxes. Press the "Timeline" command from the single activity panel. Let's give our chart a good title. Activate the "Format" Tab, select the "Chart title" element, then write a text in the bottom editbox, and hit OK:
Here is our chart:
For this basic compare command (Activity Timeline comparison), the region-test descriptions were automatically sent as titles for the data series.
Let's select another easy command (comparing difference events) :
What can we deduce here? First, bravo to Intel's TBB. Besides that, there are many other conclusions; personally, I am much more intrigued by the fact that the other two implementations are giving results that contradict the intuitive expectation of delivering better results as we move from the 8 writers-case, to the 4readers+4writers case, to the 8 readers case. However, the goal here is attained, we leave discussing interpretation to the forum if you want: the idea is that if you choose to use Easy Profiler for profiling your code, then not only have you avoided to lose time re-inventing the "measurement code", but you are making it easy and quick to analyze/visualize/compare results, attain interpretation, and discover unexpected facts about your code performance. In this final scenario, we only used 2 out of (14+12) analysis/compare commands, but I challenge you if you can get such a resulting chart using an automatic profiler.
You want to modify the code? Here are some guidelines. First open the solution with Visual Studio C++ 2008.
The Observer project corresponds to the observer application. It depends on a .NET chart control (see the References and dependencies section) which is wrapped in the Chart Provider project. The CRLAdapter is a bridge between the unmanaged Observer project and the .NET Chart Provider project. Also, it depends on the Collector project. Thus, this latter has to be deployed on both the Observer directory and your instrumented application executable directory.
This DLL is heavily based on STL collections. The measures are, of course, maintained in RAM until they are written to disk. An XML-DOM parser is used to help with the serialization (read/write). The class CFeature is a base class for all three features: CActivity, CTask, and CWorker. CTest represents a "region" while CTestsFile is a set of tests stored in one file. Everything should not be difficult here. Time measurement relies on QueryPerformanceCounter with the reference time being the call to startRegion. A split and merge mechanism occurs in CTask and CWorker when the collectionType parameter of startRegion is set to the value of 'h'. This allows the profiling of "high performant" code that would otherwise generate Gigabytes of measures! That is the example when you want to study the behavior of a chess engine that performs millions of position calculations per second. Data compression will only result in a few analysis/compare operations that become unavailable (example: tasks execution history).
This MFC application relies on the public classes exported by the Collector DLL to do the serialization/calculation process. When you open a test file, region-tests are rendered to the left tree pane:
class CProfileTree : public CXHtmlTree
{
public : void renderFile(CTestsFile* pFile);}
pFile is already created by a static function declared in CTestsFile and contains all child region-tests and their features.
These data structures are then acted-upon by the "operation classes". As you choose a set of operand features and click an operation button, an operations class factory creates an operation class, passes the operand, and calls the virtual execute member.
class CAnalysisTool
{
public:
virtual void execute(CFeature* pTarget,CFeature* pExtraTarget=NULL)=0;
}
class CCompareTool
{
public:
virtual void execute(std::vector< CTest* > tests,
std::string targetName,std::string extraTargetName)=0;
}
If it is a compare operation, the tests vector is populated by items in the checked tree control. Of course, each operation has its own logic to calculate the result. Example:
void CCompareTaskContributionToActivity::execute
( std::vector<CTEST*> tests,std::string targetName,std::string extraTargetName )
{
std::vector< CTest* >::iterator myIt;
chartControl.resetSeries();
int i=0;
for (myIt=tests.begin();myIt!=tests.end();myIt++)
{
i++;
CTest* pTest=*myIt;
CActivity* pActivity=(CActivity*) pTest->getFeatureByName(targetName);
CTask* pTask=(CTask*) pTest->getFeatureByName(extraTargetName);
std::string activitySeries=pTest->getDescription()+
std::string(" ")+pActivity->getName();
std::string taskSeries=pTest->getDescription()+
std::string(" ")+pTask->getName();
chartControl.addSeries(activitySeries, CChartControl::StackedColumn);
chartControl.addSeries(taskSeries, CChartControl::StackedColumn);
CString strProperty;
strProperty.Format(_T("StackedGroupName=%d"),i);
chartControl.setCustomProperty(activitySeries,strProperty);
chartControl.setCustomProperty(taskSeries,strProperty);
CActivity::PointsVector pointVector=pActivity->getPoints();
CActivity::PointsVector::iterator myIt;
myIt=pointVector.begin();
if (myIt==pointVector.end())
return;
CActivity::CCheckPoint* pLastPoint=*myIt;
myIt++;
while (myIt != pointVector.end())
{
CActivity::CCheckPoint* pCurPoint=*myIt;
double taskContribution=pTask->measureTimeContribution
(pLastPoint->getTime(),
pCurPoint->getTime());
chartControl.addPoint(activitySeries,pCurPoint->getName(),
pCurPoint->getTime()-pLastPoint->
getTime()-taskContribution);
chartControl.addPoint(taskSeries,pCurPoint->getName(),
taskContribution);
pLastPoint=pCurPoint;
myIt++;
}
}
}
Chart visualization is done thanks to Microsoft Chart Controls for Microsoft .NET Framework (based on Dundas Chart). Consequently, the ugly part of the code is where I had to allow the integration of this .NET control into the unmanaged MFC application.
There are many defects and potential improvements. When I developed this in Q1 of 2009, it was also an occasion to create my first website. I used/continued to use it in two personal projects (server framework + chess engine), then I used it to help optimize a documents creation engine at work. All that time, there were few people interested as recorded by site statistics. Then, I published it in the labs section of the company where I work. Nothing changed. It seems that few people do horribly slow code today. :) (Or may be very few, deal with performance-critical projects.)
Seriously speaking, I hope that publishing this tool at this great place, and making it Open Source will change the situation. Alone, I cannot devote myself totally to it: I've already solved my problems with it and will continue to do so. Now multiple hands have to meet together to implement the desired changes and improvements:
-
Data Pre-calculation
Change all AnalysisTool and CompareTool derivatives so they pre-calculate all data before any rendering call. The benefit of this is that we can persist the data values and offer their exports in different format. Think also of the performance of the chart generation when it is only enabled after all data has been calculated. The intent to separate between the calculus and the rendering code is visible from this, unfortunately disregarded mechanism:
class CAnalysisTool
{
public:
CAnalysisTool(void);
~CAnalysisTool(void);
public:
virtual void execute(CFeature* pTarget,CFeature* pExtraTarget=NULL)=0;
virtual void render()=0;
-
Remote, Live Profiling
Imagine a situation when an analysis tool is selected in advance and that the target instrumented application is running in a remote host, and that the chart is being updated as long as the incoming flow of data is received from the remote Collector instance: the Observer would act like a "generic" dashboard! What is needed most is an asynchronous, streaming-like mechanism of the data values between the Collector and the Observer.
-
Color System
Some analysis/compare operations result in a very complex chart where the colors have a big impact on its readability. The hope is to add a mechanism to choose the color for each data series based on the rule that blue denotes activity, red is for tasks, and green is for worker. Even in certain easy "charts", it is better to follow this rule. For example, when selecting the "Total times" analysis command available under the "All Tasks" panel, we currently get a pie chart similar to:
This should be changed by choosing the "red" color for each of the data pies. That is possible if we take the RGB value of the red color, convert it to the YCrCb system -for example- then select 5 values only differing in the Y channel, and re-converting them back to the RGB color space.
Let's take another problem. The following chart was obtained using the analysis tool called "Stacked" under the "Single activity" panel after selecting the "lifetime" activity + the "routing text chat" task as operands:
Please resort to the CHM help file for the mathematical formula behind this. There is the same previous problem with the colors here: the "routing text chat" series need be in red color. However, the red must be transparent, to show the blue beneath it; the reason can be found in the formula itself.
As for the following chart (obtained after a compare command that shows the evolution of the interaction between a worker and a task):
The left rectangle should have been automatically filled with a green color. The third one too. As for the second and third, they should have been in red. However, the first two must have a same Y-channel value that differs from the last two rectangles.
Finally, here we have a huge problem:
You think you have a solution, how? We have two tests of the same region containing two workers of which total durations are displayed here for the two tests. Frankly, I could not solve it except if we can make use of the style hashing or fill gradient options, even though it is not clear how to guarantee that we can automatically and theoretically get different styles.
Bugs
Bugs are everywhere: for example, a misuse of IRs systematically results in an application crash :) (like making a call to insertCheckPoint with an activity name that has n0t been already supplied to a call to insertActivity).
Contributors are warmly welcome: the project place at Google is now ready.
This is the list to third party codes/controls:
This is the first release, let's call it 0.1 alpha. Since the application is complex, an SVN is needed. Thus for updates, please resort to Google Project Place.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






