Introduction
This project (can be run from here) can be a useful exercise for new learners of Web Forms and HTTP protocol.
The project aims to achieve the following goals:
First, it is a basic project on Web Forms development.
Second, it serves as an interesting example of an HTTP client that acts as a "special purpose" crawler.
Currently, I am teaching a course on Internet Protocols and Client-Server Programming at KFUPM, and I have developed this project
as a kick-start task to give my students a head start. Previously, most of the programming tasks for the course were done using Windows Forms,
which I think, were less appropriate (and less fashionable).
Background
Although the project is quite basic (one ASPX page with about 100 lines of program code), it does cover several fundamental concepts:
ASP.NET WebForms, server-side Web Controls, use of TCPCLient class (object) to build a basic HTTP
client, HTTP Requests and Reponses, managing the state for a web application using the Session object,
use of DataTable objects for organized storage and manipulation of data.
Description
The project is essentially an HTTP client that grabs HTTP server headers returned by various web servers on the Internet.
This gives information about the different web-server software in use and their rankings.
For educational purposes, the students were asked to complete a partial solution.
The suggested implementation is meant to help students master the fundamental techniques of web development (using ASP.NET Web Forms)
and set the stage for more interesting (and advanced) exercises subsequently.
Implementation
The Web Forms application developed for this project implements the following tasks:
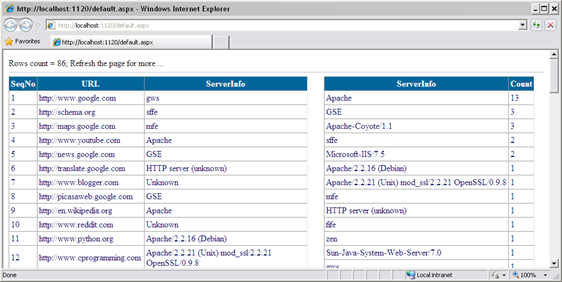
Task 1: Execute a search query on Google (or Infoseek) and grab the URLs from the search results.
These URLs are then shown in a GridView (this renders an HTML table).
Task 2: Access the servers found in step 1 using a simple HTTP HEAD request (i.e., "HEAD / HTTP/1.0"), examine the returned server headers,
and update the gridview to show server-header values.
Task 3: Show a second GridView with a summary info. (i.e., web servers and their counts).
The following table lists the various methods used by the project.
| Method | Description | Called from, related task |
string FetchURL(string url, string requestMethod) | Fetches data (headers and body) associated with a given URL. | Page_Load(), ModifyServerInfo()
Tasks 1 and 2 |
HashSet<string> ProcessData(string htmlData) | Returns a set of absolute URLs found in htmlData. | Page_Load()
Task 1 |
void ModifyServerInfo(DataTable dt, DataTable dtsum, int MaxRecords) | Issues "Head" requests and modify records in datatable dt. | Page_Load()
Task 2 |
void UpdateSummaryInfo(DataTable dtsum, string ServerInfo) | Updates count-field in table dtsum. The given ServerInfo value specifies the record to be updated. | ModifyServerInfo()
Task 3 |
void Page_Load(object sender, EventArgs e) | Application’s entry point. Creates two DataTable objects (dt,
dtsum),
calls other methods to add/modify table records, and binds GridView objects to tables. |
How the application works
A proper starting place for understanding the code is the Page_Load() method, since it is the application’s entry point, given below.
Random rand = new Random();
string[] searchWords = new string[] { "books","toys","medicine","math", "programming",
"sports", "news", "kids", "cars", "English","jokes", "travel" };
protected void Page_Load(object sender, EventArgs e)
{
DataTable dtsum = (DataTable) Session["summaryTable"];
DataTable dt = (DataTable) Session["urlTable"];
if (dt==null)
{ dt = new DataTable();
dt.Columns.Add("SeqNo", System.Type.GetType("System.Int16"));
dt.Columns.Add("URL", System.Type.GetType("System.String"));
dt.Columns.Add("ServerInfo", System.Type.GetType("System.String"));
Session["urlTable"] = dt;
DataColumn[] keys = new DataColumn[1];
keys[0] = dt.Columns[1];
dt.PrimaryKey = keys;
dtsum = new DataTable();
dtsum.Columns.Add("ServerInfo", System.Type.GetType("System.String"));
dtsum.Columns.Add("Count", System.Type.GetType("System.Int16"));
Session["summaryTable"] = dtsum;
}
string searchWord = searchWords[rand.Next(searchWords.Length)];
string SearchUrl = "http://www.google.com/search?q=" + searchWord;
string searchData = FetchURL(SearchUrl,"GET");
if (searchData.StartsWith("Error"))
{ Response.Write(searchData);
Response.End();
return;
}
HashSet<string> urlSet = ProcessData(searchData);
foreach (string s in urlSet)
{ DataRow row1 = dt.NewRow();
row1["SeqNo"] = dt.Rows.Count + 1;
row1["URL"] = s;
row1["ServerInfo"] = "Unknown";
try { dt.Rows.Add(row1); }
catch { };
}
Label1.Text="Rows count = " + dt.Rows.Count + "; Refresh the page for more ...";
int MaxRecords = 10;
ModifyServerInfo(dt, dtsum, MaxRecords);
GridView1.DataSource = dt;
GridView1.DataBind();
dtsum.DefaultView.Sort = "Count Desc";
GridView2.DataSource = dtsum;
GridView2.DataBind();
}
In Page_Load(), the project creates two DataTable objects:
dt (urlTable) and dtsum (summaryTable).
To prevent the loss of these tables between postbacks (page refreshes), they are saved into the page’s
Session object.
Every time the page is refreshed, more URLs are added to urlTable.
To avoid duplicate URLs, we have opted to have the "URL" field a primary key. Thus, adding a duplicate record will cause an exception.
This is why we enclose the "dt.Rows.Add(row1);" statement in a
try-catch block. When an exception occurs, we simply want to ignore the error and continue.
A try-catch with empty catch block achieves exactly that (this is like
On Error Resume Next in VB).
Note: For the dtsum (summaryTable), we need the
ServerInfo values to be unique but, for simplicity,
we did not set SeverInfo as a primary key. If you examine UpdateSummaryInfo() method, you will see that it only adds a record if the
ServerInfo value is not already found in the table.
However, this solution may not work under concurrent access by multiple users.
The rest of the code in Page_Load() executes the following steps (in order):
Execute a Google search query via a call to FetcURL().
Call ProcessData() to extract the absolute URLs found in the HTTP reply from step 1.
Add the URLs (with ServerInfo set to "unknown") to urlTable.
Call ModifyServerInfo() to contact URLs with "unknown" servers; Update
urlTable and summaryTable.
Bind GridView1 to urlTable and GridView2 to
summaryTable (sorted descending by Count).
Note: A GridView object is more versatile than a raw HTML table; it offers some useful features such
as sorting and paging (via AJAX calls to the server) which become handy as tables get large.
Another basic method that is repeatedly called is FetchURL(url, requestMethod).
The method is called with a Google query/"GET" for Task 1, and with a URL/"HEAD" for Task 2.
The method uses a TCPClient object (from .NET System.Net.Sockets namespace). The class constructor used takes a host and port number (set to 80).
The host is extracted from the URL-parameter passed to FetchURL().
string FetchURL(string url, string requestMethod)
{
int doubleSlahIndex = url.IndexOf("//");
if (doubleSlahIndex > 0)
{
doubleSlahIndex += 2;
url = url.Substring(doubleSlahIndex);
}
string host = url;
string path = "/";
int pathIndex = url.IndexOf('/');
if (pathIndex > 0)
{ host = url.Substring(0, pathIndex);
path = url.Substring(pathIndex);
}
int port = 80;
TcpClient client = new TcpClient(host, port);
NetworkStream stream = client.GetStream();
StreamReader reader = new StreamReader(stream);
StreamWriter writer = new StreamWriter(stream);
string command = "GET " + path + " HTTP/1.0\r\n" + "Accept: */*\r\n" + "Host:" + host + "\r\n";
string output = "";
try
{ writer.WriteLine(command);
writer.Flush();
output = reader.ReadToEnd();
}
catch (Exception e)
{ output = "Error:" + e.Message; }
return output;
}
The method ModifyServerInfo(dt, MaxRecords) implements Task 2, in accordance with the documentation given therein.
In this method, we issue the call FetchURL(Host, "HEAD"), where Host is set to
ServerInfo values retrieved from urlTable.
Limitations, Possible Enhancements
In its current form, the application has two major limitations:
First, the process of discovering (and logging) URLs and information about their servers takes place while the client (user) request is being handled.
Ideally, such a process should be run as a background process independent of users’ requests.
Second, the information gathered by the application is saved in the web server memory as Session objects and, therefore, it cannot be shared among different users.
Furthermore, the information is lost when the user closes his browser. Preferably, the information should be saved to permanent storage as database tables.
History
- 27th September, 2012: Version 1.0









 News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin