Introduction
The Fuzzy Word Experiment project is exactly what it says in the title in that it was conceived as an experiment to see if there was a way in which to deal with words in a fuzzy manner, seeing as words themselves can be somewhat of a fuzzy area themselves I thought that they might lend themselves quite well to being given the Fuzzy treatment.
Details
The first idea was to get a value for the word and then use this as it's fuzzy value pretty much in the same way that you would use a fuzzy number ( see earlier articles for Fuzzy Number explanation ) with the value being the Number of the word and a Minimum and a Maximum value being applied so that it would be possible to see if words matched.
double dValue = 0;
for( int i=0; i<strWord.Length; i++ )
{
dValue += strWord[ i ];
}
The code above is the section of code that assigns a value to the word, this is simply an addition of the ASCII values for the letters. At on point they were also multiplied by there position within the word but this did nothing to get around the problem of different words arriving at the same number, it helped slightly but it didn't fix it.
e.g. The word glass gives a reading of
Fuzzy Word = glass
Maximum = 548
Minimum = 528
Membership = 1
Compared membership = 0
Number = 538
ID = 0
Name =
The important bit in the readout is the Number variable which gives a reading of 538. When we compare this to the word "sheep" we hit a problem
Fuzzy Word = sheep
Maximum = 543
Minimum = 523
Membership = 1
Compared membership = 0
Number = 533
ID = 0
Name =
As you can see the number for the word "sheep" is 533 which means that no matter which way the comparison between the two words is done the values always fall within the minimum and maximum ranges of the other word giving them an instantly high likely hood that if just using numbers is involved then the two words are going to be considered almost identical by the code running the comparison
The second idea is based on the actual letters in the word and it goes something like this if there are a certain number of letters in the word that are in the correct place then there is a high likely hood that the person who typed the words is aiming at the same word and maybe made a typo. So count the number of letters in the word that match, using,
int nCount = 0;
for( int i=0; i<Word.Length; i++ )
{
if( i < Word.Length && i < comparison.Length )
{
if( Word[ i ] == comparison[ i ] )
{
nCount++;
}
}
}
Which gives the number of letters that are in the correct place. But this then leads to problems with the length of the words. Say you have two words one is a short word say four or five letters long and the other is a long word but the long word contains the short word. If the short word was the Fuzzy Word object then the code above would let the long word through. In order to help solve this problem the code deals with Maximum Incorrect Letters and Minimum Matching Letters. Unfortunately the concept of having a minimum number of matching letters doesn't quite hold up all on it's own. The problem is that some words are just plain short and if this value is set too high then short words are going to be automatically rejected. So for this reason this value has to be kept fairly low and in the code it defaults to 3.
The idea of having a maximum number of incorrect letters can help out though in the fact that as long as the word has a certain amount of letters correct then there are so many that can be wrong. Any more than that and the word is automatically rejected. Once again though the maximum number of incorrect letters cannot be made too high as it would then block out short words completely.
And this is where we come back to the number value for each word. At this point we have a word that has no more than a few incorrect letters but enough correct letters to get through so what do we do with them because we still need to give it some sort of Membership value that will express the word as a comparison with the word we are testing against. This is done through the code,
FuzzyWord temp = new FuzzyWord( comparison );
if( dValue >= this.Number - nValueDifference &&
dValue <= this.Number + nValueDifference )
temp.ComparedMembership = 1.12;
else if( dValue >= this.Number - ( nValueDifference * 2 ) &&
dValue <= this.Number + ( nValueDifference * 2 ) )
temp.ComparedMembership = 1.25;
else if( dValue >= this.Number - ( nValueDifference * 3 ) &&
dValue <= this.Number + ( nValueDifference * 3 ) )
temp.ComparedMembership = 1.37;
else if( dValue >= this.Number - ( nValueDifference * 4 ) &&
dValue <= this.Number + ( nValueDifference * 4 ) )
temp.ComparedMembership = 1.50;
else if( dValue >= this.Number - ( nValueDifference * 5 ) &&
dValue <= this.Number + ( nValueDifference * 5 ) )
temp.ComparedMembership = 1.63;
else if( dValue >= this.Number - ( nValueDifference * 6 ) &&
dValue <= this.Number + ( nValueDifference * 6 ) )
temp.ComparedMembership = 1.75;
else
temp.ComparedMembership = 1.87;
Which compares the value of the word to be compared against the number plus or minus a preset value called nValueDifference which is set to 10 by default. This then allows us to arrive at a conclusion based on the comparison which is then returned by the code to the calling program in the ComparedMemerbership member.
Of course this doesn't prevent words like "duck" and "suck" being considered almost identical, which is a good thing as they are almost identical but it does differentiate between them so that when compared to "duck", "suck" will not be returned with a compared membership of 1.0 which indicates a direct match.
Testing The Class
There are two applications provided with the sample code. The first is used to compare words directly to each other and see if there is a match and the second will process a text file search for words specified before hand.
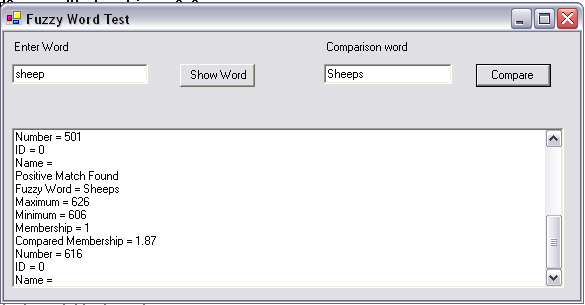
The Fuzzy Word Test Program ( The FuzzyWordExperiment project ) compares the two words entered. In this case the word "sheep" with "Sheeps" ( I know it should be spelt Sheep's ) and gives the compared membership value for the two words. Remember when comparing words it is the Compared membership value after a comparison as words always have a membership value of 1.0.
The Show Word button will show the values for the word in the left hand edit box and the Compare button will call the Fuzzy Word Compare function using the two provided words.

The second Fuzzy Word Test application takes a txt file and parses the text line by line for the words entered in the Words to find drop down list box. Words can be added to the box by typing them in and clicking the add button and removed by selecting them and clicking on the remove button. The two drop down list boxes for the tolerance levels set the levels for the upper and lower tolerances these range from 0.12 - 0.87 and 1.12 - 1.87.
The Find The Words button opens the text file and reads it line by line comparing each word in the line to the words listed in the words to find list. If a word is found in the line that is in the list then program outputs the find to the edit box and then proceeds on to the next line of text. It should be noted that we are not dealing with proper sentences yet only separate lines of text.
As you can see by looking at the image above in our search though the text file which in this case is the "Origin Of The Species" text file that is provided in the debug directory for the program so that you can play around with the sample code. Their is only one item that failed the tolerance level in the above image and that is the word dusky that has three letters that are included in the word duck and it fails because it has a tolerance level of 1.87 which is outside the set tolerance levels for this run of the program.
There are also more word specific aspects to the code that deal with some of the problems when encountering words. For example the class contains an array that holds punctuation characters so if you have the word duck followed by a comma then this will be selected as single word by the reading code but the comparison code will remove the comma. See the code for other punctuation characters that are included.
Also there is code added in order to allow for plurals of the words you are looking for but this has an optional parameter so if you want ducks to be treated as a completely separate word from duck then it will be.
Finally
For me at least this has been an interesting experiment that makes me wonder how far you can push the treatment of words before you have to start getting into a context situation, by which I mean before you have to start understanding what the words themselves mean. I have a number of thoughts on ways to take this but they are of the kind that may be far too stupid to work or far too hard to implement. I guess I'll just have to follow them through and see what happens.
History
Note
The last article in the series contains the latest code for the library. No attempt at backward compatibility will be attempted and I will change the library as I see fit.
Link To Next Article
This is currently the latest article.
References
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




