Introduction
I recently found myself in a situation where I needed to search through a group of regular expressions and find all matches of them in a given document. Of course, I could use tools like grep to get this done. But I actually wanted to use this in an application, and regular expressions represented certain objects which I later needed to access if there was a match and do further processing. Anyways, persuade yourself of the fact that grep and such tools were not applicable.
A naive approach would have been to iterate through all the regular expressions and run them through the text. The union of the results from all the regular expressions would be the result of the search. This is not really efficient as current implementations of regular expression engines which have backtracking (e.g., a(BC)\1 which matches aBCBC) don't scale well with the size of the regular expression (exponential). These include nearly all common programming languages (C#, VB.NET, Java, Python, etc.). I also noticed that I don't really need the backtracking features of these engines. I just wanted a very fast search of a group of regular expressions which could increase to thousands. I needed the normal regular expression features such as alternation(|), Kleen star(*), optional substring(?) and such operators which didn't require backtracking (no lookaheads and lookbehinds). Although this limited the ability of the system, it enabled the use of very efficient data structures for this task. I couldn't find any implementations on the internet so I set out to do it myself.
Background
In order to understand the operations involved in doing this, you need to brush up on some of your computer science concepts. I will try my best to present the ideas here as well so that the article would be rather self-sufficient. We'll start by introducing some formalisms that are used to represent strings. I have decided against using computer scientific notations to describe them as they may at times be intimidating to the uninitiated.
Finite State Machines (FSMs)
Finite State Machines are mathematical models aimed at representing systems where the behavior of the said system can be described by a series of states and transition between these states. As an example, think of the process of going through
customs. You start at an initial state where you declare if you have any items to declare. The document you filled may be thought of as an input to the first states. Depending on this input, you may either transition into a state representing the green line or the red line after which you may transition into different states there-after.
Another possibility is representing strings as FSAs. We are going to represent strings as FSMs or FSA (Finite State
Automata) for the purposes of our searcher. In the picture below, you can see an example of a string represented by an FSA. I have used Graphviz's tool to draw my FSMs.
As seen in the image, the states don't really represent anything useful or you could say they represent the indices in a string. The label as we'll see is not really important for our purposes for now. Notice that the transitions are the actual characters of the string. The reason we have used an FSA here is that let's say if you want to match a string (abcc) to the above FSA, you just start from the initial state and just follow along the transitions to see if you reach the "matching state" or not. The matching state here is the right most state.
FSA could have self loops; meaning you could end up in the same state with a transition. They could also have certain types of transitions known as epsilon transitions. These types of transitions allow transitioning to another state without receiving any input. They could also have more than one transitions with the same input. Let's say in our example of representing strings as FSAs, we could transition from a state to two different states with the input "a".
Non-deterministic Finite State Automaton (NFA)
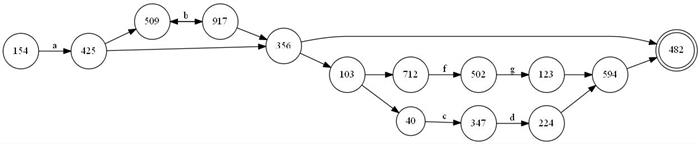
These are really the FSMs we described so far. They don't really have any restrictions on their transitions. Due to the fact that they can have more than one transition with the same input and they also have epsilon-transitions, they are called non deterministic. As an example, you cannot really deterministically decide which transition to take when matching the series of strings represented by an NFA. It is important to realize at this point that an NFA may be used to represent more than one string. Precisely speaking, NFA can represent a type of language categorized under the Chomsky hierarchy as regular languages. Any language represented by an NFA is regular and any regular language can be represented by an NFA. We'll get back to this fact later on.
Notice in the above image that the NFA has epsilon transitions (transitions without any label). The image represents the "ab*(cd|fg)?" regular expression.
Deterministic Finite Automaton (DFA)

DFAs are a type of FSAs that have certain restrictions on their transitions. Here are the limitations:
- You cannot have epsilon transitions.
- For each unique input, you may have one transition only. As an example in our
string FSA, we cannot have more than
one "a" transition from a given state.
The fact that you need one unique input for each transition means that you can always deterministically decide if a transition exists and where you would go if you take it.
DFAs also represent regular languages and any NFA can be converted into an equivalent DFA using the Subset Construction
Algorithm which we'll implement later on.
Methodology
We will start by parsing our regular expression and turning it into an NFA. This is straight-forward. Well kind of. The more complex part is resolving
the operator priorities and actually parse the regex correctly.
I have implemented this parsing process using the Dijkstra's Shunting
Yard Algorithm. In a nutshell, this algorithm uses two stacks to push the operators and operands. You basically start from the left and keep on adding operators
and operands to these two stacks. Whenever an operator is pushed into the stack that has a lower priority than the stack's top element, all the pushed operations
are carried out using the pushed operands in the other stack. After all these operations are processed, the result is pushed to the operands stack. This continues until the regex is exhausted. I'm not going to go through this process in more detail as there is already material on the internet for this purpose. As an example, you can start with this.
So far, we have been able to convert a regex to an NFA. From here, there are two methods for searching through a series of NFAs. One is to run the subset algorithm on each regex and then merge them together and the other is merging all together and then running the subset algorithm on the huge automata created. I think the former approach is more efficient as the subset algorithm is not efficient and by running it on smaller
automata and then merging them, we will save some time.
Regardless of the fact that we run the subset algorithm before or after the merging procedure, we still need to group all these parsed regexes together. We can do so by "OR"ing all the regular expressions together. I do this by adding an initial state and making epsilon transitions to the start of all the created NFAs. After this step, I create a DFA out of this huge NFA. Notice that even if we have made DFA out of each regex, the resulting
automata from the merge is an NFA.
The resulting NFA now represents all the regular expressions grouped in one nice model. Notice that we have now reduced the search to only matching words in this final NFA. Now we can run the subset algorithm to get rid of
redundancies in the NFA. Technically, the resulting DFA can be further reduced to reach a reduced DFA which is one with the least number of states possible. The algorithm to convert the DFA to a reduced DFA is efficient. The real problem lies in converting the huge NFA to the DFA (exponential in the number of states) but as you'd see in practice, that is not usually a problem.
I'd try to update this article with the DFA reduction algorithm soon.
If you need more information about this algorithm, you can visit this
Wikipedia page which describes the Aho-Corasick string matching search.
Using the Code
There are certain assumptions made in the code and the algorithm that you should be aware of. Firstly, the set of currently supported operators is as follows:
- Kleen Star(*) and +
- Alternation (|)
- Optional Operator(?)
- Parentheses
Of course, this list can easily be extended as long as the operator does not necessitate look behind, look ahead or backtracking. What you have to do if you already have a set of regular expressions in place is to just check if they have supported operators first. They should not have any of the unsupported operators. If you have any problems with adding operators, mention it and I'll do my best to add them.
Here is a tester program:
class Program
{
static void Main(string[] args)
{
FSM NFA = GetOredRegexes();
string syt = NFA.GetDotRepresentation() + "\n";
FSM DFA = NFAToDFA.ConvertNFAToDFA(NFA);
DrawWithGraphviz(NFA, "NFA");
DrawWithGraphviz(DFA, "DFA");
}
private static void DrawWithGraphviz(FSM FSA, string fileName)
{
ProcessStartInfo info = new ProcessStartInfo();
info.Arguments = string.Format(@"-Tjpg -o C:\GraphvizOutput\{0}.jpg", fileName);
info.FileName = @"c:\Program Files (x86)\Graphviz2.34\bin\dot.exe";
info.UseShellExecute = false;
info.RedirectStandardInput = true;
using (Process proc = Process.Start(info))
{
StreamWriter sw = proc.StandardInput;
string syt = FSA.GetDotRepresentation() + "\n";
sw.Write(syt);
}
}
private static FSM GetOredRegexes()
{
List<Regex> regexes = new List<Regex>();
regexes.Add(new Regex("ab*(cd|fg)?"));
regexes.Add(new Regex("ab(bas|umusa)"));
regexes.Add(new Regex("abc(de)*"));
regexes.Add(new Regex("ab(cd|de)gph*"));
regexes.Add(new Regex("a(cd)?dg"));
FSM oredNFA = new FSM();
regexes.ForEach(regex => oredNFA |= FSM.Parse(regex.ToString()));
return oredNFA;
}
}
Here is the output for the above piece of code:
NFA
Resulting DFA
As seen above, the number of states in the initial NFA was drastically reduced to make a DFA. The fact that there is only one transition in each state means that at any given time, when doing the matching, we only need to worry about the current location in the DFA. This is opposed to the NFA where multiple outputs with the same character are possible and we would have to carry around pointer on all different positions. All in all, the search is much faster, simpler and more elegant.
History
- Nov. 2 2013- Initial draft...
- Nov. 11 2013- Release 1.0
- Dec. 10 2013- Release 1.1 Fixed typo in text
- Jan 14 2014- Release 1.2 Fixed typo in text
- Feb 1 2014 - Release 1.3 Fixed bug for patterns like a*b
I'm a recent Msc Computer Science graduate with an interest in all things Machine Learning. I am in love with C# and having an affair with Python. My main interests in machine learning is NLP hence the Python affair. I enjoy classical music and for some reason am constantly fighting my body's call for exercise.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






