Introduction
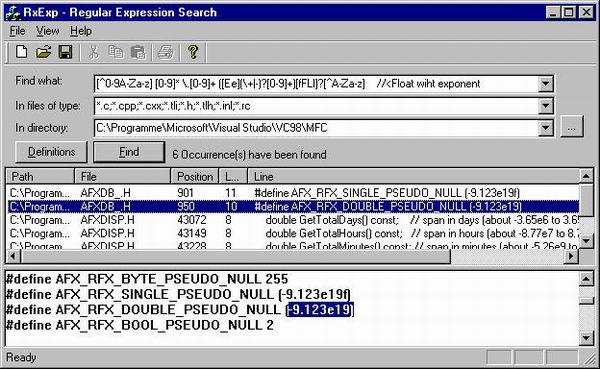
Regular expressions are a well recognized way for describing string patterns. The following regular expression defines a floating point number with a (possibly empty) integer part, a non empty fractional part and an optional exponent:
[0-9]* \.[0-9]+ ([Ee](\+|-)?[0-9]+)?
The rules for interpreting and constructing such regular expressions are explained below. A regular expression parser takes a regular expression and a source string as arguments and returns the source position of the first match. Regular expression parsers either interpret the search pattern at runtime or they compile the regular expression into an efficient internal form (known as deterministic finite automaton). The regular expression parser described here belongs to the second category. Besides being quite fast, it also supports dictionaries of regular expressions. With the definitions $Int= [0-9], $Frac= \.[0-9]+ and $Exp= ([Ee](\+|-)?[0-9]+), the above regular expression for a floating point number can be abbreviated to $Int* $Frac $Exp?.
Interface
I separated algorithmic from interface issues. The files RexAlgorithm.h and RexAlgorithm.cpp implement the regular expression parser using only standard C++ (relying on STL), whereas the file RexInterface.h and RexInterface.cpp contain the interfaces for the end user. Currently there is only one interface, implemented in the class REXI_Search. Interfaces for replace functionality and for programming language scanners are planned for future releases.
struct REXI_DefErr{
enum{eNoErr,eErrInName,eErrInRegExp} eErrCode;
string strErrMsg;
int nErrOffset;
};
class REXI_Search : public REXI_Base
{
public:
REXI_Search(char cEos='\0');
REXI_DefErr
AddRegDef (string strName,string strRegExp);
inline REXI_DefErr
SetRegexp (string strRegExp);
bool MatchHere (const char*& rpcszSrc, int& nMatchLen,bool& bEos);
bool Find (const char*& rpcszSrc, int& nMatchLen,bool& bEos);
private:
bool MatchHereImpl();
int m_nIdAnswer;
};
Example usage
int main(int argc, char* argv[])
{
const char szTestSrc[]= "3.1415 is the same as 31415e-4";
const int ncOk= REXI_DefErr::eNoErr;
REXI_Search rexs;
REXI_DefErr err;
err= rexs.AddRegDef("$Int","[0-9]+"); assert(err.eErrCode==ncOk);
err= rexs.AddRegDef("$Frac","\\.[0-9]+"); assert(err.eErrCode==ncOk);
err= rexs.AddRegDef("$Exp","([Ee](\\+|-)?[0-9]+)");
assert(err.eErrCode==ncOk);
err= rexs.SetRegexp("($Int? $Frac $Exp?|$Int \\. $Exp?|$Int $Exp)[fFlL]?");
assert(err.eErrCode==ncOk);
const char* pCur= szTestSrc;
int nMatchLen;
bool bEosFound= false;
cout << "Source text is: \"" << szTestSrc << "\"" << endl;
while(rexs.Find(pCur,nMatchLen,bEosFound)){
cout << "Floating point number found at position "
<< ((pCur-szTestSrc)-nMatchLen)
<< " having length " << nMatchLen << endl;
}
int i;
cin >> i;
return 0;
}
Performance issues
A call to the member function REXI_Search::SetRegexp(strRegExp)involves quite a lot of computing. The regular expression strRegExp is analyzed and after several steps transformed into a compiled form. Because of this preprocessing work, which is not needed in the case of an interpreting regular expression parser, this regular expression parser shows its efficiency only when you apply it to large input strings or if you are searching again and again for the same regular expression. A typical application which profits from the preprocessing needed by this parser is a utility which searches all files in a directory.
Limitations
Currently Unicode is not supported. There is no fundamental reason for this limitation and I think that a later release will correct this. I just did not yet find an efficient representation of a compiled regular expression which supports Unicode.
Constructing regular expressions
Regular expressions can be built from characters and special symbols. There are some similarities between regular expressions and arithmetic expressions. The most basic elements of arithmetic expressions are numbers and expressions enclosed in parens ( ). The most basic elements of regular expressions are characters, regular expressions enclosed in parens ( ) and character sets. On the next higher level, arithmetic expressions have '*' and '/' operators, whereas regular expressions have operators indicating the multiplicity of the preceding element.
Most basic elements of regular expressions
- Individual characters. e.g. "h" is a regular expression. In the string "this home" it matches the beginning of 'home'. For non printable characters, one has to use either the notation \xhh where h means a hexadecimal digit or one of the escape sequences \n \r \t \v known from "C". Because the characters * + ? . | [ ] ( ) - $ ^ have a special meaning in regular expressions, escape sequences must also be used to specify these characters literally: \* \+ \? \. \| \[ \] \( \) \- \$ \^ . Furthermore, use '\ ' to indicate a space, because this implementation skips spaces in order to support a more readable style.
- Character sets enclosed in square brackets [ ]. e.g. "[A-Za-z_$]" matches any alphabetic character, the underscore and the dollar sign (the dash (-) indicates a range), e.g. [A-Za-z$_] matches "B", "b", "_", "$" and so on. A ^ immediately following the [ of a character set means 'form the inverse character set'. e.g. "[^0-9A-Za-z]" matches non-alphanumeric characters.
- Expressions enclosed in round parens ( ). Any regular expression can be used on the lowest level by enclosing it in round brackets.
- the dot . It means 'match any character'.
- an identifier prefixed by a $. It refers to an already defined regular expression. e.g. "$Ident" stands for a user defined regular expression previously defined. Think of it as a regular expression enclosed in round parens, which has a name.
Operators indicating the multiplicity of the preceding element
Any of the above five basic regular expressions can be followed by one of the special characters * + ? /i
- * meaning repetition (possibly zero times); e.g. "[0-9]*" not only matches "8" but also "87576" and even the empty string "".
- + meaning at least one occurrence; e.g. "[0-9]+" matches "8", "9185278", but not the empty string.
- ? meaning at most one occurrence; e.g. "[$_A-Z]?" matches "_", "U", "$", .. and ""
- \i meaning ignore case
Catenation of regular expressions
The regular expressions described above can be catenated to form longer regular expressions. E.g. "[_A-Za-z][_A-Za-z0-9]*" is a regular expression which matches any identifier of the programming language "C", namely the first character must be alphabetic or an underscore and the following characters must be alphanumeric or an underscore. "[0-9]*\.[0-9]+" describes a floating point number with an arbitrary number of digits before the decimal point and at least one digit following the decimal point. (The decimal point must be preceded by a backslash, otherwise the dot would mean 'accept any character at this place'). "(Hallo (,how are you\?)?)\i" matches "Hallo" as well as "Hallo, how are you?" in a case insensitive way.
Alternative regular expressions
Finally - on the top level - regular expressions can be separated by the | character. The two regular expressions on the left and right side of the | are alternatives, meaning that either the left expression or the right expression should match the source text. E.g. "[0-9]+ | [A-Za-z_][A-Za-z_0-9]*" matches either an integer or a "C"-identifier.
A complex example
The programming language "C" defines a floating point constant in the following way: A floating point constant has the following parts: An integer part, a decimal point, a fraction, an exponential part beginning with e or E followed by an optional sign and digits and an optional type suffix formed by one the characters f, F, l, L. Either the integer part or the fractional part can be absent (but not both). Either the decimal point or the exponential part can be absent (but not both).
The corresponding regular expression is quite complex, but it can be simplified by using the following definitions:
$Int = "[0-9]+."
$Frac= "\.[0-9]+".
$Exp = "([Ee](\+|-)?[0-9]+)".
So we get the following expression for a floating point constant:
($Int? $Frac $Exp?|$Int \. $Exp?|$Int $Exp)[fFlL]?
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





