Introduction
The Microsoft Web Browser COM control adds browsing, document, viewing, and downloading capabilities to your applications. Parsing and rendering of HTML documents in the WebBrowser control is handled by the MSHTML component which is an Active Document Dynamic HTML (DHTML) Object Model hosting ActiveX Controls and script languages. The WebBrowser control merely acts as a container for the MSHTML component and implements navigations and related functions. MSHTML can be automated using IDispatch and IConnectionPointContainer-style automation interfaces. These interfaces enable a host to automate MSHTML through the object model.
Note
If you are not using the Visual Studio .NET IDE; use Windows Forms ActiveX Control Importer (Aximp.exe) to convert type definitions in a COM type library for an ActiveX control into a Windows Forms control. For instance: to generate the interop DLL's for the ActiveX browser component using the command line run aximp ..\system32\shdocvw.dll relative to your system32 path. Compilation of a form that uses the AxSHDocVw.AxWebBrowser class would be as follows: csc /r:SHDocVw.dll,AxSHDocVw.dll YourForm.cs.
Using the code
Simple Automation scenario:

In order to automate this task, first add a Microsoft Web Browser object to an empty C# Windows application. In the Visual Studio .NET IDE, this is done by using the "Customize Toolbox..." context menu (on the Toolbox), pick "Microsoft Web Browser" from the COM components list. This will add an "Explorer" control in the "General" section of the Toolbox.
private void Form1_Load(object sender, System.EventArgs e)
{
object loc = "<A href="http:
object null_obj_str = "";
System.Object null_obj = 0;
this.axWebBrowser1.Navigate2(ref loc , ref null_obj,
ref null_obj, ref null_obj_str, ref null_obj_str);
}
Next open the solution explorer and add a reference to the Microsoft HTML Object Library (MSHTML) from the COM components list and implement the following code.
using mshtml;
private int Task = 1;
private void axWebBrowser1_DocumentComplete(object sender,
AxSHDocVw.DWebBrowserEvents2_DocumentCompleteEvent e)
{
switch(Task)
{
case 1:
HTMLDocument myDoc = new HTMLDocumentClass();
myDoc = (HTMLDocument) axWebBrowser1.Document;
HTMLInputElement otxtSearchBox =
(HTMLInputElement) myDoc.all.item("q", 0);
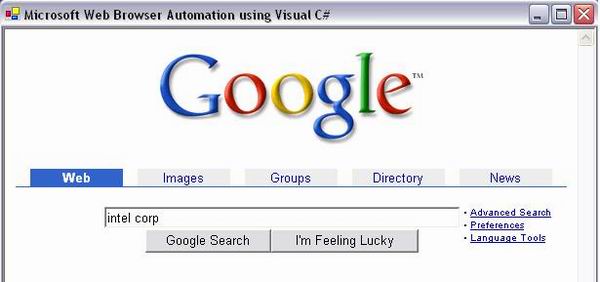
otxtSearchBox.value = "intel corp";
HTMLInputElement btnSearch =
(HTMLInputElement) myDoc.all.item("btnI", 0);
btnSearch.click();
Task++;
break;
case 2:
break;
}
}
References
MSDN
History
- Version 1.0 - November 16th 2003 - Original Submission
- Version 1.1 - November 17th 2003 - Modified
axWebBrowser event


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




