Introduction
This is my first article on this great site which helps me so much. My article is about the preprocessing steps for string matching. This field or string matching have a lot of applications specially in genetic research, searching within texts, and many other applications.
I tried so hard to find an algorithm that deals with this issue and can be built by C#, but I didn't find any code. So I decided to build my own code and put it up on this great site in the hands of great programmers like you. I hope my first step pleases you.
Background
Basic Definitions
Suppose that you have this string, California:
cal.. is a prefix (start of the string must begin with the first character) nia.. is a suffix (must have the end character of the string) lifo, orni,…. are substrings
Many string matching and analysis algorithms are able to efficiently skip comparisons by first spending "modest" time learning about the internal structure of either the pattern ( for example the word I search for), or the text (which I search in). This part of the overall algorithm is called the "Preprocessing stage".
Pre-processing
Given a string S and a position i > 1:
Zi(S) = length of the longest substring of S that starts at i and matches a prefix of S.
For example:
5678
S = aabcaabxaaz
Z<sub>5</sub>(s) =3 (aabc …..aabx)
Z<sub>6</sub>(s) =1 (aa …..ab)
Z<sub>7</sub>(s) = Z<sub>8</sub>(s) =0
For any position i > 1 where Zi > 0, the Z-box at i is defined as the interval starting at i and ending at position i + Zi – 1.
For every i > 1, ri is the right-most endpoint of the Z-boxes that begin at or before position i. Another way to state this: ri is the largest value of j+Zj-1 over all 1<j= i such that Zj >0.
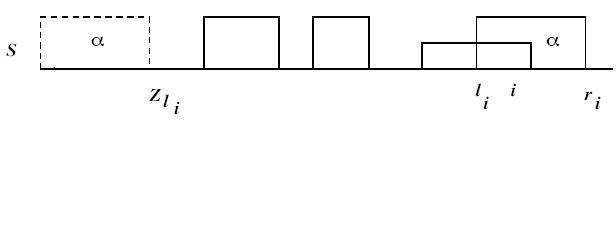
Z- Algorithm
Step 1: Find Z2 by explicitly comparing, the characters of S[2…|S|] and S[1…|S|] until a mismatch is found.
Step 2: If Z2 > 0, then r = r2 = Z2 + 1 and l = l2 is set to 2.
Step 3: Use r and l to compute next Z, r and l, i.e. Z3, r3 and l3.
If i > r, then i is outside of a Zbox, repeat step 1.
If i = r, then i is inside a Zbox.
If k is in a Zbox:
k is part of a previous prefix of S: alpha.
The character at k appears at the previous position k’.
The sub-string starting at k (beta) matches a previous beta.

If Zk > 0, then it also follows that:
Substring at k must match a prefix of S of length at least the minimum of Z<code>k and length beta.
If Zk’ < length beta, Zk=Zk’ and r and l remain unchanged.
If Zk’ = length beta….
If Zk’ = length beta….
Entire substring beta is a prefix of S and Zk may be equal to length beta.
Zk may be larger than beta, so compare characters from prefix to characters from S until a mismatch occurs.
Zk is then set depending upon where the first mismatch occurs and l and r reset.
These are the general steps of the Z algorithm.
Using the Code
I attached two *.zip files , the first "STRING_Matching" is the class which contains the function used, while the other "ZAlgorithm.zip" is the implementation or the test of the class STRING_Matching:
using STRING_Matching;
Exact_Matching S = new Exact_Matching();
string pattern = "abcdaaabchoabcd";
char[] Stest = pattern.ToCharArray();
char[] Stest1;
int[] M = S.Zblock(Stest);
for (int i = 0; i < M.Length; i++)
{
Console.WriteLine(M[i].ToString());
}
History
- 15th March, 2008: Initial post


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




