Introduction
I’ve been implementing numerical libraries in .NET and have come to some conclusions about iteration performance. My classes have to hold a large amount of data and be able to iterate through that data as quickly as possible. In order to compare various methods, I created a simple class called Data that encapsulates an array of doubles.
Method #1: Enumeration
Data implements
IEnumerable. It contains
GetEnumerator which returns its own
DataEnumerator, an inner class.
…
public DataEnumerator GetEnumerator()
{
return new DataEnumerator( this );
}
IEnumerator IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
}
…
public struct DataEnumerator : IEnumerator
{
private Data internal_;
private int index_;
public DataEnumerator( Data data )
{
internal_ = data;
index_ = 1;
}
public double Current
{
get
{
return internal_.Array[index_];
}
}
object IEnumerator.Current
{
get
{
return Current;
}
}
public bool MoveNext()
{
index_++;
if ( index_ >= internal_.Array.Length )
{
return false;
}
return true;
}
public void Reset()
{
index_ = -1;
}
}
}
…
Method #2: Indexing
I implemented an index operator on the class which simply calls the index operator on the array.
public double this[int position]
{
get
{
return array_[position];
}
}
Method #3: Indirect Array
I created a property to access the array.
public double[] Array
{
get
{
return array_;
}
}
When iterating, I called the Array property and then its index operator.
d = data.Array[j];
Method #4: Direct Array
I created a reference to the array.
double[] array = data.Array;
Then, I iterate through that reference.
d = array[j];
Method #5: Pointer Math
Finally, I tried improving performance by iterating through the array in Managed C++ using pointer manipulation.
static void iterate( Data& data )
{
double d;
double __pin* ptr = &( data.Array[0] );
for ( int i = 0; i < data.Array.Length; i++ )
{
d = *ptr;
++ptr;
}
}
I called it this way:
Pointer.iterate( data );
Conclusions
To test the different methods, I allocated 1,000,000 doubles into an array and indexed over all of them. I repeated this 1,000 times to minimize randomness. Here are the results...
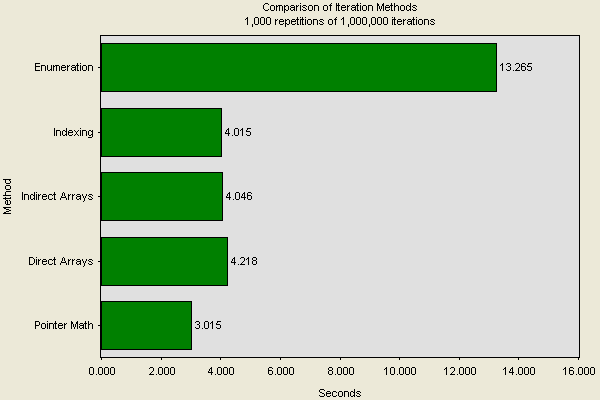
Enumeration is always slow. That’s not surprising as I’m using a general data structure to hold the doubles. The three operator/property methods differed very slightly. These are probably all optimized similarly. Using pointer math to traverse over the raw data was significantly faster. This is probably due to the fact that there’s no bounds checking. In summary, if you have large amounts of data and performance is critical, consider using managed C++.
Acknowledgements
Thanks to Mark Vulfson of
ProWorks for tips on using Flipper Graph Control. Also, to my colleagues Ken Baldwin and Steve Sneller at
CenterSpace Software.
Trevor has held demanding development positions for a variety of firms using C++, Java, .NET, and other technologies, including Rogue Wave Software, CleverSet, and ProWorks. He is coauthor of The Elements of Java Style , The Elements of C++ Style, and The Elements of C# Style, published by Cambridge University Press. He has also served on a course advisory board of the University of Washington. His teams have won the JavaWorld "GUI Product of the Year" and XML Magazine "Product of the Year" awards. Trevor holds a BSc in Computer Science from the University of British Columbia and a BA in Economics from the University of Western Ontario.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






 ]
]