Introduction
The main task of this article is to present an implementation of Formal Language Theory constructs in a real world application. In the case described below, it will be a mathematical parser (library), which will evaluate a given valid mathematical expression and return the corresponding result. In scripting languages, you'll find this algorithm already implemented (it is actually defined within the core of dynamic programming language behavior - "everything is evaluated on runtime"). Most frequently, it is defined as the eval method.
In the case of static programming languages, we should define an algorithm which will perform the semantic (according to symbol table) and syntactic (parsing) analysis of a given string. Mainly, there are two basic approaches in Formal Language Theory which perform this task: LL top-down parser, which parses the input from Left to right, and constructs a Leftmost derivation of the sentence; and LR parser that reads the input from Left to right and produces the Rightmost derivation. The parser which is going to be explained here is the LL parser, written in C#.
Background (Chomsky Hierarchy)
There are infinitely many legitimate mathematical expressions. In order to be able to identify invalid sentences from valid ones, we will need to define a precise set of rules which in turn will define a formal grammar (as in any natural language, in order to build correct sentences, we should learn its grammar). This grammar, if proved that it belongs to the class of LL grammars, will be able to generate all possible valid sequences and identify invalid ones. It is worth mentioning that it does not describe the meaning of these sentences, only the rules that can be applied on them. If you are looking for detailed explanations about LL grammars, please consult material related to Chomsky hierarchy and specifically, Type-2 grammars (context free grammars). Click here for a detailed review.
Polish Postfix Notation
After the parser (based on the formal grammar) will tell us if the input string concedes to defined rules, we'll face the problem of actually calculating the expression according to mathematical rules of priority. Following is a simple example:
4*3^(2) = 36 ('^' stands for power sign)
4*3^(2) != 122
People can easily count the value of the above written expression because they do know what the priority of each operation is. That's why we'll start counting from the end to the beginning, first raising 3 to the power of 2, and then multiplying with 4. However, machines cannot learn this; that's where Polish Postfix Notation (PPN or Reverse Polish Notation) comes in handy. It allows us to transform a given expression into an analogous one in which the operations will be performed sequentially from left to right. Imagine that the previous example is rewritten as follows:
(2)^3*4
In this case, the priority can be ignored because sequentially we'll obtain the correct result. That's how PPN is used. It is important to remark that we will be using the postfix notation because the main difficulty of using the infix notation is that we still may have brackets in it, meaning that the priority order problem is not solved. That's why, in an evaluator, it is more preferable to use postfix ones. Fortunately, the PPN string is built using a parsing binary tree which in turn is constructed while our parser checks whether the input expression is valid or not. After this check is done, we'll have an in-memory copy of this tree which will allow us to build the PPN sequence. Following is an example of a PPN expression:
4*3^(2) == 2 3 ^ 4 * (PPN)
After we build the PPN sequence, we also need an interpreter which will be able to perform the actual mathematical expression calculation. Interpreters of Reverse Polish notation are stack based. Operands are pushed into the stack until an operation sign is encountered, then the two last items are popped, the operation is performed, and the result is pushed back into the stack. We'll get to an example of an evaluator a little bit further. For more detailed explanations, please consult the Polish notation topic.
Binary Tree
Because the LL(1) grammar helps us to build a parsing tree (which is, of course, a binary tree), now we can traverse this one using a Left - Right - Root traversal and build the needed PPN expression. If you are not familiar with binary trees, please consult any available topic related to it.
Building the Grammar
In the mathematical parser which is going to be explained further, the set of tokens (terminals, symbols which cannot be broken in smaller units) is defined as follows:
VT = {+, -, *, /, ^, ( , ), a},
where ' ^ ' stands for power, and
'a' stand for any real constant.
The grammar actually defines the rules of transformation (derivation) of the input expression. Before starting to write these rules, we must consider the fact that derivations which have bigger priority (mathematically) must be placed in the deepest leaves of our derivation tree; thus, we must start to write our rules from less important tokens (from a mathematical point of view, the operations '+' and '-'; the biggest priority belongs to the unary plus and minus operations).
Grammar:
| # | Rule | Comment |
| 1 | E->E+T | Expression + Term |
| 2 | E->E-T | Expression - Term |
| 3 | E->T | Some expressions can be considered to be just terms |
| 4 | T->T*P | Term * Power |
| 5 | T->T/P | Term / Power |
| 6 | T->P | Some terms can be considered to be just powers |
| 7 | P->P^F | Power ^ Factor |
| 8 | P->F | Some powers can be considered to be just factors |
| 9 | F-> -F | This derivation stands for unary minus |
| 10 | F-> +F | This derivation stands for unary plus |
| 11 | F->a | Factor can be considered to be a constant |
| 12 | F->(E) | Factor can be considered to be an expression in parentheses |
The obvious problems with this grammar (those which make this grammar not belonging to the LL(1) class) are:
- We have more than '1' production (derivation) which starts with the same symbol (production 1 && 2, 4 && 5). This problem can be solved easily by applying the left factoring rule.
- Left recursion (production 1, 2, 4, 5, 7). Needs to be eliminated.
I've just pointed out those algorithms which we need to use in order for the last to belong to the LL(1) class. The actual transformation is beyond the scope of this article, so I'll just skip it (if you are still interested in it, feel free to mail me and I'll send you the actual proof). At the final stage (after applying all the required theoretical changes to the grammar), we will be able to construct the LL(1) Parsing Table (which will tell the computer precisely what derivation to apply on each specific input character). Also, it is important to mention that before constructing the LL(1) Parsing Table, we need to build the Director Symbol Set (using the First and Follow sets).
LL(1) Parsing Table
The actual table which was developed from the grammar can be seen in the above figure. If you are not familiar with its usage, consult any available material, or take a look at the provided example in the figure after this one.
- V - stands for adVance
- $$ - stands for Accept
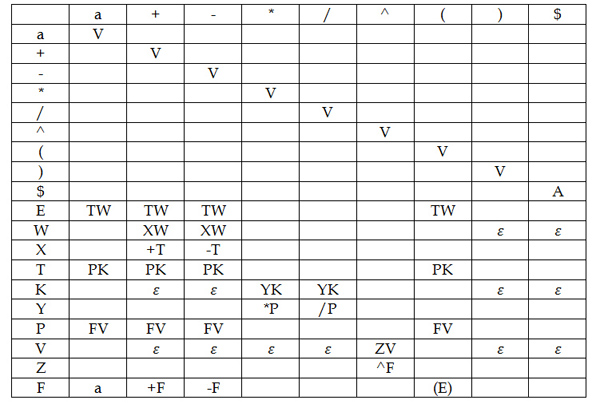
While using this predictive parsing table, we can:
- derive the binary tree, which will help us
- define the Polish Postfix Expression, which in turn will
- evaluate our mathematical expression.
Let's take an example to verify our LL(1) parsing table and build the parsing tree.
'a+a*a^-a'
The initial state of the stack machine is E$ (where $ stands for the end of stack), meaning that we are deriving the expression from the axiom E (E - expression). The initial character in the input stream is a (the first character for the input string). In order to somehow signalize to the parsing table that the input string ended, we will append the $ sign at the very end of our string (a+a*a^-a$). If the entire input string is valid from a grammar point of view, then at the very end, our mechanism will reach the final accept state ($ - in the stack machine, and $ in the entrance band). The derivation works as follows:
- Look at the intersection between the first character from the stack machine (E) and first character of the entrance band (a) in the Parsing Table. We can see that it is the TW cell. Push TW into the stack.
- Follow the LL(1) parsing table rules until the $$ state is reached.
- If an empty cell is encountered while parsing, this means that the input string is invalid.

Parsing Tree
Up until now, we've modeled a Syntax/Semantic Parser which is only able to control if the given expression is a valid mathematical one. In case the sequence is not valid, our LL(1) table will stop on an empty cell as I've already mentioned. Using the previous example, we can build the parsing tree, which in turn will construct the Polish Postfix Notation string. Using this string, we will perform the actual evaluation which will return the value of the math function.
The tree
If we traverse this tree using the LRR algorithm (Left - Right - Root), grabbing characters from leafs (nodes without children), we'll build the Polish Postfix Notation string. The string after traversal will contain the following sequence of characters:
'a a a 0 a - ^ * +'
Reverse Polish Notation Evaluator
Like I've explained previously, the Reverse Polish Expression evaluator is stack based. Operands are pushed into the stack until the computer finds an operator (+, -, *, /, ^). After that, the two previous values are popped, and the evaluation is done. The result is pushed back into the stack. Assume for the previous expression that a = 2.
2+2*2^-2 = 2.5
First of all, the computer should perform the operation of unary minus. After that, 2 is raised to the power of -2. The result is multiplied by 2, and finally is added to 2.
As you can see, the evaluation is done correctly. The LL(1) Parsing table works.
MathObj Project
In the archive which contains the actual implementation of the mathematical parser, we can find the MathParserDataStructures project. The following class diagram describes the main classes which will perform all the theoretical work described above:
The central class which will perform the real evaluation is the MathObj class. It gives the opportunity to its user to find the value of any given valid mathematical expression. MathParserBinaryTree is the class which will hold the in-memory structure of the Parsing Tree. The tree is built from MathParserTreeNode objects, which in turn have their own Nonterminal or Operation values. In order to visit nodes from the tree, I've used the Visitor pattern. The tree traversal is performed using the Left-Right-Root recursive algorithm.
Using the Code
The main operation of the MathObj class is the Evaluate method. It takes the parameters as follows:
mathInput:String - the input itself (E.g.: "x+y"). vars:char[] - an array of character variables used in the expression (E.g., {'x','y'}). varsValues:double[] - variable values (E.g., {2.5,2.6}).
The result of this calculation will be 5.1.
You can argue that a better classes design might be an architecture with the MathObj class defined as static. But I've decided differently, because most of the time, people would like to calculate a value of a function on an interval. In this case, the string input will remain the same (alongside with the char[] of variables in it), only the values of the variables will change. Because the biggest overhead of the theoretical algorithm states within the building of the parsing tree, I've chosen to build it only once (and persist its state in the memory). If the method is invoked a second time without a string change, the previously built Polish Postfix Notation will be used in order to calculate the value of the expression (this Persist State idea gives the algorithm a much faster evaluation speed).
public virtual double Evaluate(string mathInput, char[] vars, double[] varsValues)
{
if (String.IsNullOrEmpty(mathInput))
throw new ArgumentException("String mathInput is empty or null");
if (this._mathInput == mathInput)
_persistState = true;
else
{
this._mathInput = mathInput;
_persistState = false;
}
if (_varsAndValues.Count != 0)
_varsAndValues.Clear();
if (vars != null && varsValues != null)
{
if (vars.Length != varsValues.Length)
throw new ArgumentException(
"vars and varsValues arrays length are not equal");
for (int i = 0; i < vars.Length; i++)
this._varsAndValues.Add(vars[i], varsValues[i]);
}
double retVal;
try
{
if (!_persistState)
{
this.SemanticTransform();
this._polishPostfixExpression =
new Operation[this._sizeOfPolishPostfixExpression];
this.GeneratePolishPostfixExpression();
}
retVal = this.CalculateValue();
}
catch (MathParserException)
{
throw;
}
return retVal;
}
Please run the MathParser.v.3 sample application in order to view how MathObj can be used.
Output
The main output of the project available in the download section is the MathParser.dll library. Also, we can find a sample project which is very simple. It allows drawing the graph of a mathematical function. Please note that the function is dependent on only one variable x : f(x).
Conclusion
Even though there are plenty of other projects (even here on CodeProject) which advice this particular problem of static programming language as dynamic function evaluation, none of them speak about theoretical part of the story. I've decided to post my solution in order for the reader to understand the practical implementation of Formal Language Theory in this particular problem. This article makes a clear mapping from pure theoretical constructs to a real world example, and I've chosen to keep the code as closer as I could to the abstract terms which were used in the description part. We can argue that in terms of memory-cost, I should have used matrixes in order to design the Parsing tree, instead of a real Tree structure, but as I've already written, I've tried to build the algorithm as close to theory as possible. I've used plenty of theoretical terms which you might explore further and adjust/use them for your particular problem. Here, I'll just enumerate them so that you can Google/explore them further:
- Formal Language Theory
- Chomsky Hierarchy
- LL(1) Grammar
- Context-free Grammars
- Parser (Syntax/Semantic Analyzer)
- Polish Postfix Notation
- Left Factoring Rule
- Predictive Parsing Table
- Director Symbol Set
- First and Follow sets
- Binary Tree
- Binary Tree Traversal
- Left-Root-Right Traversal
History
- 18th January, 2010: Initial post
- 20th January, 2010: Updated source code
Interested in computer science, math, research, and everything that relates to innovation. Fan of agnostic programming, don't mind developing under any platform/framework if it explores interesting topics. In search of a better programming paradigm.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




