Introduction
This is the first article of a 3-part series about an open-source project that I have been developed in the past 9 months. The project output itself is a Java library for mapping traditional relational database to a domain model to create SQL-free query service. I will dedicate this first article to introduce the concept of ontology-based data access and then continue giving an overview about Semantika and its main components.
Later in part 2, I will go into more detail about the mapping modelling and some basic API introduction to start working with the library. And lastly, I will present you a short "hello-world" tutorial to connect all the dots about this project in part 3.
Background
The underlying theory behind this work comes from the extensive research in computational logic. There are many readings from the past and recent publications that you can search in the Internet regarding ontology-based data access. I will put some at the end of this article as a reading reference. In this article, I will present you a quick introduction about the concept, omitting the logic details and theories. However, I assume my readers have some background in Java programming, relational database and XML. Knowledge in semantic web technology such as OWL, RDF and SPARQL is favorable but not primarily necessary.
What is Ontology-based Data Access?
But first what is ontology? Ontology in information science (quote from Wikipedia.com): "a formal knowledge representation [specified] as a hierarchy of concepts within a domain, using a shared vocabulary to denote the types, properties and interrelationships of those concepts". For those who are familiar with object-oriented programming, ontology is well resembled like the UML class diagram. In fact both share the same purpose, that is, to model a domain of interest in conceptual perspective. However, ontology offers more feature for describing concepts in a formal way. And by formal it means every strings or symbols used in the description are associated to particular meanings (or semantics) and logic rules. In other word, ontology is similar to a dictionary, filled with words denoted by the labels of its classes and properties. Moreover, this "dictionary" can be shared and used by humans and machines to communicate about data.
To give you a better idea, let me give you an example in its application. The following diagram shows a simple ontology for Human Resources domain.
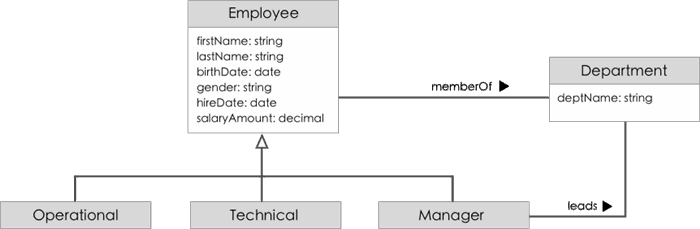
When it is applied, the family name of each employee is made available by referring to "lastName" label. Other different (yet similar) labels such as "familyName", "surname" or "cognome" will trigger an error when used. These labels (or so forth they are called domain vocabulary) gives a shared understanding about the topic in question, leaving ambiguity across different domains and languages. This is one key aspect about ontology. However, I have to mention there is still one missing point and essential about ontology, that is, ontology can carry knowledge. I will save this part for another time that seems fit to explain.
Using this basic idea about ontology, an ontology-based data access (OBDA in short) has a meaning as answering questions (or queries) over a data source using domain vocabulary listed in an ontology. Since an ontology serves as a high-level global schema, users are relieved from the detail structure of the underlying data source and its query mechanism. This abstraction provides transparency in data access needs. In the context of the system, the discussion about the kind of data sources will be limited to relational database. As you will encounter later, data query will no longer be using SQL expressions and prior knowledge about table names, column names and join expressions unnecessary.
Semantika DRM
Semantika DRM (Semantika in short) is a platform for domain-relational mapping and data access for Java application. It provides data query and retrieval facilities in SPARQL language. For those who are new to SPARQL (read: sparkle), it is a query language for RDF graph data. Don't panic if these terms sound unfamiliar to you, we are going to visit them using examples in part 3.
Semantika in its own is a simple API. However, much to be learned is the modelling part especially the mandatory resource which is the mapping model. In summary, developing Semantika application requires these three components:
- Running database,
- Model resources,
- Client Java code.
Running Database
This is obvious because Semantika is a data access platform for database. It adds a semantic layer on top of database tables to facilitate intuitive queries. Semantika uses JDBC adapters to connect to different database engines. Currently, the platform supports 3 database engines, i.e., MySQL, PostgreSQL and H2.
Model Resources
There are two kinds of model required by the system: domain model (ontology) and mapping model. Semantika supports reading ontology file in OWL/XML format. Below is the simplified example of Human Resources ontology.
<Ontology>
<Declaration>
<Class IRI="Department"/>
</Declaration>
<Declaration>
<Class IRI="Employee"/>
</Declaration>
<Declaration>
<Class IRI="Manager"/>
</Declaration>
<Declaration>
<Class IRI="Operational"/>
</Declaration>
<Declaration>
<Class IRI="Technical"/>
</Declaration>
<Declaration>
<ObjectProperty IRI="leads"/>
</Declaration>
<Declaration>
<ObjectProperty IRI="memberOf"/>
</Declaration>
<Declaration>
<DataProperty IRI="firstName"/>
</Declaration>
<Declaration>
<DataProperty IRI="lastName"/>
</Declaration>
<Declaration>
<DataProperty IRI="salaryAmount"/>
</Declaration>
<ObjectPropertyDomain>
<ObjectProperty IRI="leads"/>
<Class IRI="Manager"/>
</ObjectPropertyDomain>
<ObjectPropertyRange>
<ObjectProperty IRI="leads"/>
<Class IRI="Department"/>
</ObjectPropertyRange>
<ObjectPropertyRange>
<ObjectProperty IRI="memberOf"/>
<Class IRI="Department"/>
</ObjectPropertyRange>
</Ontology>
I recommend to use Protege as your ontology editor. It has a clear GUI for developing an ontology from scratch.
The next model is the mapping model. Semantika is equipped with a native mapping format in XML called Termal/XML. The document definition is straightforward and easy to edit using any regular text editor. Below is the example:
<program xmlns="http://www.obidea.com/ns/termal#"
xmlns:tml="http://www.obidea.com/ns/termal#"
xmlns:rr="http://www.w3.org/ns/r2rml#">
<prefix tml:name="" tml:ns="http://obidea.com/ex/ontology/empdb#" />
<uri-template tml:name="Department" tml:value="http://obidea.com/empdb/department/{1}" />
<uri-template tml:name="Employee" tml:value="http://obidea.com/empdb/employee/{1}" />
<mapping tml:id="TriplesMap1">
<logical-table rr:tableName="EMPLOYEES"/>
<subject-map rr:template="Employee(EMP_NO)"/>
<predicate-object-map rr:predicate="birthDate" rr:column="BIRTH_DATE"/>
<predicate-object-map rr:predicate="firstName" rr:column="FIRST_NAME"/>
<predicate-object-map rr:predicate="lastName" rr:column="LAST_NAME"/>
<predicate-object-map rr:predicate="gender" rr:column="GENDER"/>
<predicate-object-map rr:predicate="hireDate" rr:column="HIRE_DATE"/>
</mapping>
<mapping tml:id="TriplesMap2">
<logical-table rr:tableName="SALARIES"/>
<subject-map rr:template="Employee(EMP_NO)"/>
<predicate-object-map rr:predicate="salaryAmount" rr:column="SALARY"/>
</mapping>
<mapping tml:id="TriplesMap3">
<logical-table rr:tableName="DEPARTMENTS" />
<subject-map rr:class="Department" rr:template="Department(DEPT_NO)"/>
<predicate-object-map rr:predicate="deptName" rr:column="DEPT_NAME"/>
</mapping>
<mapping tml:id="TriplesMap4">
<logical-table rr:tableName="DEPT_EMP"/>
<subject-map rr:template="Employee(EMP_NO)"/>
<predicate-object-map rr:predicate="memberOf" rr:template="Department(DEPT_NO)"/>
</mapping>
<mapping tml:id="TriplesMap5">
<logical-table rr:tableName="DEPT_MANAGER"/>
<subject-map rr:class="Manager" rr:template="Employee(EMP_NO)"/>
<predicate-object-map rr:predicate="leads" rr:template="Department(DEPT_NO)"/>
</mapping>
</program>
Other supported format is R2RML/Turtle format. This is the standard document recommended by W3C for RDB2RDF mapping specification. However, I will use Termal/XML format in all the examples due to people's familiarity in XML.
Note that in Semantika you can opt out the domain model (or ontology) in the configuration and have the domain vocabulary specified directly in the mapping model.
Client Java Code
The client code is the calling code in which it is part of your Java application. The API is so simple that you only need to write a few lines of code for system setup and query execution. I will present you an example of client code in part 3.
Why is This Matter?
This is a valid question and deserves a persuasive answer. I will present you in three bullet points the reasons that motivate this development, as well as to show you some use cases that might match to your needs.
- Self-service data access. Data access can be a challenging task in data-intensive industries. For example, engineers without IT training need to access a large amount of data and corporate data storage for their work. The typical solution is to provide a set of pre-defined queries by the IT department in a form of internal application that can handle most common tasks. However as the tasks become more complex, the application clearly has a limitation and writing new queries by the engineers themselves is not an option. Furthermore, what might happen next is that the IT department will get overloaded by the engineer's requests and cause a bottleneck in industry.
A proper solution is to enable engineers (or end users) to have the data access by themselves. Semantika provides a domain-layering interface that hides data schema from end users and simplified it to the level abstraction of domain vocabulary thus making data query as an intuitive task.
- Engaging new technology with a non-intrusive solution. Recently the phrases like "Big Data" and "Semantic Web" have become a buzzword in IT world. Many solutions have been proposed for better data management and raising performance. However many of these solutions requires full data migration to the new platform which it can be expensive and full of risks.
Semantika offers a solution where it stands neutrally to the existing data infrastucture and doesn't touch the record data itself. No migration or data transformation is necessary to run the system. This feature makes Semantika as the best option to try these new technologies first hand before shifting entirely to them.
- Enrich incomplete information in database. This is one feature that distinguishes Semantika from any other semantic web solutions. If you recall in my early paragraph about ontology can carry knowledge then this is the right moment to explain. I will use a simple example use case. Suppose in the employee database contains data about people who has job title as Engineer, Assistant Engineer and Senior Engineer and the ontology provides a background knowledge that specifies those three titles are Technician workers then query such as "return all employees that are technicians" will return a non-empty result, despite the fact that the data schema does not include a relation or attribute explicitly reffering to technician workers. This new attribution can be fueled into your existing data thus adding more meaningful information to query.
Conclusion
Important things for you to remember after reading this article:
- There is a good Java library in Semantic Web area called Semantika.
- Ontology is useful for sharing keywords in your domain. Consider it as a written dictionary that people use to communicate about data.
- Ontology-based data access gives you an alternative solution for querying data over database intuitively.
- Semantika is non-intrusive and risk-free for your valuable data.
Further Reading
- Calvanese, Diego, et al. "Ontology-based Database Access." SEBD. 2007. [PDF]
- Poggi, Antonella, et al. "Linking data to ontologies." Journal on data semantics X. Springer Berlin Heidelberg, 2008. 133-173. [PDF]
- Rodrıguez-Muro, Mariano, and Diego Calvanese. "Dependencies: Making ontology based data access work in practice." Proc. of the 5th Alberto Mendelzon Int. Workshop on Foundations of Data Management (AMW 2011). Vol. 749. 2011. [PDF]
- A thesis by Hannes Molsen entitled "Ontology Based Data Access." [PDF]
History
23-06-2014:
24-06-2014:
I am a Software Engineer, specialized in Java application and API design. I have a working experience in knowledge-base representation, domain model and databases. My latest project in Semantika tries to offer a new solution for data querying over relational database using Semantic Web technology.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




