|
You should write this as a 2D table of delegates, indexed by firstSym and secondSym. No "else if" tests at all, just two simple multiplications plus an addition (fistSym * secondSym * sizeOfADelegate + baseAddress) to find the delegate to run. At C# level, you obviously see it as plain indexing, not as multiply and add.
Most likely, the table would be quite sparse. If the span of symbol values is large, making the table huge, you may want to use tricks to compress it. A delegate reqires quite a few bytes of storage, so if your table is large, but the number of elseif-bodies, actions, is moderate, your 2D table might contain not delegates, but byte or halfword delegate indexes into a dense delegate array.
Note that if the same delegate action is used many places in the table, with a direct delegate table you would repeat the space overhead many times. With an byte/halfword index table and a separate delegate array, you pay the delegate space overhead only once per action routine; each new reference to it requires only another byte or halfword (when your 2D table is sparse and you have packed it).
If your actions are brief, just a single statement or two, you might avoid all the delegate overhead (both in space for the delegate table and the run time overhead) by setting up the actions as a switch case. If you make the entries in your 2D table not as plain integers but an enum type with symbolic value names that describe the semantics of the actions, it might in fact be quite readable!
I created such a framework this Youle vacation, and was positively surprised by how compact and efficient the driver could be made, how compact the tables turned out, and the advantage of having a single copy of the action code used in several different cases. You fix a bug, or add an extension, in one place; you don't have to duplicate the fix in six different elseifs. The most important thing, though: Any empty square in the 2D table is a red flag: Here is a case you forgot to handle! Check it up!
In my framework, you edit the body of each action by itself, and you edit the 2D table by itself. Then a generator (optionally) packs the table, and creates either a delegate table or a switch statement, and a driver function (which is oblivious to the problem at hand; the only reason for generating it for every model is to strip off the lines not required because no action calls for that specific functionality, such as a third dimension of the table). One other reason to use a generator is that the 2D table is independent of programming language; the action bodies exist in multiple instances in C#, C++, C, Python or whatever language you have written a generator for (which is a fairly trivial matter). The first "language" alternative is a pseudocode alternative that can be used as a model for other languages. You edit the action body only; the generator takes care of creating function headers, adding any (language independent) comment block at the top of the function etc. The red tape of coding complex flows is drastically reduced - once you've got that 2D table in place!
As a convenience feature, I added a red flag alternative: Given an event (in your case: second symbol) in a given state (first symbol), the driver scans the state row of the packed table for events that have a defined action. If you have defined a red flag column to your table, it will be at the end of list, substituting for all the empty table cells that have been compressed away. So I can make a general catch-all error handler: Illegal event (/secondSymbol) xxx in state (/firstSymbol) yyy.
I am considering presenting this framework as a CP article once it is polished. I really would like to make it as a VS plugin, but I have not yet learned how to make VS plugins. (Hints to a good guide would be welcome!) As of now, I must generate the code outside VS (which is fast, but still...), and if you edit the code in VS you must import it back in for the next time you generate it. That is a little cumbersome, so I guess that to make it generally usable, I must provide a VS plugin for it.
|
|
|
|
|
one issue with this approach: It works for k=2, but not k=n.
The issue is the index.
The number of symbols in a viable prefix (k) is arbitrary but known at generation time
but my generated code needs to work for k=whatever regardless of the overarching machine/code size.
I can compact the table in a recursive descent parser by only extending k where necessary. in the functions where k=1 (most of them) none of this is necessary.
But i can't use an actual table to begin with.
To understand why you'd have to understand Parsley. It generates recursive descent composition parsers. Basically it creates a series of recursive descent parsers that share the same symbol table and lexer and can call each other.
Now, I could handle this using tables, sort of (tables have a hard time delegating to other tables when parsing) but i could do it.
But what I couldn't handle is virtual non-terminal productions, which allow someone to completely take over the parse.
The reason i can't use tables there is it increases the complexity of the code that exists in the grammar (the end user's code) to a point where it's not feasible. Tables aren't intelligible if they're cooked and machine generated, but this has to be.
I can only refer you to using Parsley in a real world scenario in hopes to illustrate the problem further. If you understand how to use Parsley you should understand why this approach probably won't work, unless i'm missing something.
Parse Anything with Parsley: A Different Approach[^]
When I was growin' up, I was the smartest kid I knew. Maybe that was just because I didn't know that many kids. All I know is now I feel the opposite.
|
|
|
|
|
Can't you scale the higher values of k in powers of 2 effectively giving you a bit pattern leading to a unique number and add the values rather than multiplying?
|
|
|
|
|
only if I'm willing to work with runs of hundreds or thousands of bits or more.
I'd need one bit for every symbol in the table, and that wouldn't necessarily let me solve all of k's space requirements. It would just let me compact some of the comparisons.
When I was growin' up, I was the smartest kid I knew. Maybe that was just because I didn't know that many kids. All I know is now I feel the opposite.
|
|
|
|
|
Yes, you are right that finite state machines are finite 
My way of doing it assumes that both the set of states/firstSymbol and events/secondSymbol are known when the tables are generated. For the third dimension, predicates for denying or allowing a transition, the set of predicate tests are predefined, but may test on state variables which extend the main state: They are predeclared, but their values may vary. In some cases, it could be possible to express some of these as even more indexed dimensions. In all the protocols I have seen, conditional transitions occur so rarely that the array would be extremely sparse, and the predicates are so simple that they can be tried in order much more efficiently than handling more dimensions. (For almost all cases, the defined predicates are not generated as individual functions but as a switch case.)
My source of inspiration is essentially X.225[^]. The state tables are found in Annex A. I certainly know that transforming an "unruly" set of switches / if-then-elses, maybe with action code spread all over the place (and which may block) into an orderly, well behaved FSM can be a major task. But a surprising large fraction of nested if-then-else sequences can be refactored into FSMs.
I never looked at Parsley, so you may very well be right that it cannot make use of FSM techniques, neither for the generating parser nor for the parser generated. Then again, very few of all the sw development collagues I have had over the years have had the slightest clue of how to do a table driven FSM, but have great "aha experiences" when I explain. So the major reason why I started developing this FSM framework is to have something that works, so I can show them: This is another and better way to do it! Maybe some cases will require extensions to the framework, but I am not going to believe in any "That approach is not a viable one" until I understand why it is not. It might be true. It might be a question of refactoring cost. It might be a lack of understanding of the FSM approach.
|
|
|
|
|
It's actually quite simple. The parser cannot be built using an FSM because it is recursive descent.
It cannot be a repurposed PDA because it already is a PDA, and the stack is the call stack.
The only way to change that is to fundamentally change parsley
When I was growin' up, I was the smartest kid I knew. Maybe that was just because I didn't know that many kids. All I know is now I feel the opposite.
|
|
|
|
|
If you implement, say, a protocol stack, you couldn't possibly do it as one single, monolithic FSM. There would be at least one FSM per protocol layer, generating events to the layers above and below, and receiving events from either.
You are of course right that transforming a recursive parser (or any solution that is fundamentally a recursive design) as a whole into a single monolithic FSM is next to impossible while maintaining its recursive nature. (Well, in principle you could manage a recursion stack as an explicitly managed list or array of stack frames, but I would hardly recommend that, except in very special cases.)
Yet, running the logic of each recursion as an FSM could be a good idea. When you dive into another recursion layer, you dive into a new FSM. A primitive example: You (hopefully) wouldn't parse a floating point literal as a deep recursion - probably there would be few other function calls than to obtain the next character. Translating that string literal into a binary float would be a perfect task for a tiny FSM.
Think of an FSM as a control structure related to a switch statement. In a recursive parser, you can see a token loop around a switch on the token value. You could just as well run an FSM and loop over feeding it token events. An FSM is really not much more than a 2- or 3-dim switch!
You rejections strongly resemble those I am used to receive It just illustrates that FSM is hardly at all taught as a programming technique nowadays. If no well known programming language had had a switch case statement, introducing it would have been met with similar rejection!
|
|
|
|
|

internal static ParseNode ParseIdentifier(ParserContext context) {
int line__ = context.Line;
int column__ = context.Column;
long position__ = context.Position;
if (((ExpressionParser.verbatimIdentifier == context.SymbolId)
&& ExpressionParser.WhereIdentifier(context.GetLookAhead(true)))) {
ParseNode[] children = new ParseNode[1];
if ((false
== (ExpressionParser.verbatimIdentifier == context.SymbolId))) {
context.Error("Expecting verbatimIdentifier at line {0}, column {1}, position {2}", context.Line, context.Column, context.Position);
}
children[0] = new ParseNode(ExpressionParser.verbatimIdentifier, "verbatimIdentifier", context.Value, context.Line, context.Column, context.Position);
context.Advance();
return new ParseNode(ExpressionParser.Identifier, "Identifier", children, line__, column__, position__);
}
if (((ExpressionParser.identifier2 == context.SymbolId)
&& ExpressionParser.WhereIdentifier(context.GetLookAhead(true)))) {
ParseNode[] children = new ParseNode[1];
if ((false
== (ExpressionParser.identifier2 == context.SymbolId))) {
context.Error("Expecting identifier at line {0}, column {1}, position {2}", context.Line, context.Column, context.Position);
}
children[0] = new ParseNode(ExpressionParser.identifier2, "identifier", context.Value, context.Line, context.Column, context.Position);
context.Advance();
return new ParseNode(ExpressionParser.Identifier, "Identifier", children, line__, column__, position__);
}
throw new SyntaxException("Expecting verbatimIdentifier or identifier", line__, column__, position__);
}
Sorry for posting so much code, but i wanted it to be true to what I'm generating.
Notice how the if statements are only one level deep. (except for the where constraint - WhereIdentifier but that's an aside right now - it's a separate conversation)
If i needed more than that, I'd certainly use an FSM inside this procedure. I hear you and in fact it's how I plan to do it. My in defense of gotos post was about using gotos as an FSM to do what you're talking about here. Using whiles to do it complicates the generation and explodes the output code size, requiring other compression techniques which make the code more, not less confusing. I prefer to make my state machines renderable to graphviz and then simply label each of the goto labels after the state in graphviz it represents. It's a map to the state machine. It makes it clear. That's my only contention in terms of how to go about it. I prefer the goto approach because i can make it followable to humans. I cannot do so with table compression techniques.
When I was growin' up, I was the smartest kid I knew. Maybe that was just because I didn't know that many kids. All I know is now I feel the opposite.
|
|
|
|
|
Plus you can have a label call Hell: meaning the line calling it is goto Hell, done that a few times, once it got in to production code!
|
|
|
|
|
For a while, I was programming CHILL, which has a first class "FOR EVER DO" to create infinte loop (which is certainly a common occurence in embedded systems - CHILL was develped for telephone switch programming).
So in a later job, when writing embedded code in C, I made a "#define ever (;;)" so that I could write "for ever" even in C. After maybe a year, one young fellow, working on some other module, had seen this in some of my code. Immediately he went through the entire code base, searching for any occurence of this "ever" macro definition and use, correcting it to the the proper way of writing it: "while (1)" (certainly not "while (true)"!), adding a nasty commit message about cleaning up attempts to make inappropriate jokes in the code. He brought it up in the daily standup as well, requesting that we stay away from such nonsense code.
I let him has his way, even though he hadn't been out of the U for a couple of years, and was hired in as an external consultant. And he wasn't in any way responsible for the modules I was developing. So, I have limited "for ever" when I want something to run forever to code I write in my spare time. At work we should be serious in our programming, writing "while (1)" as Real Programmers do!
|
|
|
|
|
I am an Embedded guy, I did Electronics at Uni,one the great comedies was we had a C course from the Computing Dept, hence GOTO is evil, get to Embedded Systems Development GOTO is OK. Get in to the real world the RTOS that is in most aircraft uses goto as a Jump to this location right now!. It is a little odd but makes sense, ensentially it is a Jump command from assembly try doing much without JMP...
|
|
|
|
|
In machine code, direct jumps are what you use to realize all sorts of structured flow control mechanisms. So there is no way to avoid using jumps when writing machine code / assembler. You still can use it in a disciplined way, though, and add a comment like "Leaving the digit loop" or something like that. You don't just jump from anywhere to anywhere!
For those "Jump there right now!" sounds very much like an exception that must be handled. The problem is: Have you really programmed that jump when that exceptional condition occurs? And what about the mess you are creating on the stack or in half-completed operations - are you prepared to clean up that?
Even the 8051 had programmed interrupts. I can't imagine that anyone use even more primitive controllers today. For those exceptional situations that must be handled now, I would think that a programmed interrupt would be a far better solution than a plain jump to "somwehere", loosing all current context. (A linked jump is not a "jump" as such, but a lightweight function call.)
True enough: When we ten years ago employed hardware graduates, they had learned c programming, and could very well explain the logic circuitry causing the program counter update when an interrupt signal arrived. But when I were referring to the interrupt handlers as a special case of parallel threads, executing side by side with your main thread, they gave me a blank stare. They had never been close to consider an interrupt handler as anything but a place to force the PC register to point to (and maybe set some 'privileged' flag). Hardware guys did not have processes and threads and that kind of stuff under their skin (they didn't even know how compilers created frames on the stack, just that the SP was moved by a call instruction).
To explain to those guys, ten years ago, that running the emergency situation on a separate thread, by a programmed interrupt, would be a lot better, was a tough task. Thankfully, today's graduates, even hardware guys, are familiar with threads and similar stuff. So today I would expect that they either understand to use exceptions, or that they understand the havoc created if a plain jump skips out of a stack frame, or even out of half-baked calculation or data structure update.
|
|
|
|
|
I had some "consultant" try that where I worked. The results were different. The lectures on coding style came to an abrupt halt.
"They have a consciousness, they have a life, they have a soul! Damn you! Let the rabbits wear glasses! Save our brothers! Can I get an amen?"
|
|
|
|
|
You shouldn't like or dislike using it; it's just one of the tools in the toolbox.
I wanna be a eunuchs developer! Pass me a bread knife!
|
|
|
|
|
I've been coding for way too long to not have feelings about it.
Ask a painter how they feel about their canvas - their paints?
There are likes and dislikes about.
Feelings are not evil.
When I was growin' up, I was the smartest kid I knew. Maybe that was just because I didn't know that many kids. All I know is now I feel the opposite.
|
|
|
|
|
Do you also have feelings about IF, FOR, ==, !=, etc?
The rabid anti-goto movement developed in schools, where teachers were sick of having to fix looping problems for inexperienced coders.
Of course, like any matter of style that's applied for schools, whether in computer languages or human languages (think Strunk & White, and cry), it's applied, per force, to people with only a little learning, many of who, instead of learning more to overcome their of-little-learning status, treat it as a decree from the gods, and espouse it loudly, every chance they get, in the hope that it will make them sound more learned than they are.
And, unfortunately, because they shout so loudly and mindlessly, lots of people hear them.
The only thing in all that that's worth having feelings about is the idiocy of people who would attack a style element simply because they don't know any better.
Goto is a tool, a way of doing something. It doesn't merit a millionth of the attention it gets.
And feelings? Pfht! I can understand people having feelings about languages, but not about something so fundamental that's in all of them.
I wanna be a eunuchs developer! Pass me a bread knife!
|
|
|
|
|
You're generating code, so it's not any worse than using a jump in assembly code. But if that code has to be altered afterwards, it could become a pain.
I've yet to use goto in C++ but have been tempted when wanting to exit an outer loop from within a switch, where break has been rudely repurposed.
|
|
|
|
|
honey the codewitch wrote: if(firstSym==lparen)
{
if(secondSym==rbracket) {
} else if(secondSym==intLiteral || secondSym==floatLiteral || secondSym==identifier) {
} else if(secondSym==...) {
...
} else ...
} else if(firstSym==lbracket) {
else if(firstSym==...) {
....
} else ...
...
}
As an alternative to this specific code, you could also use switch statements. The branch with multiple "||" logic would be multiple case labels.
I just present this as a choice, not necessarily a preferred choice.
I'm retired. There's a nap for that...
- Harvey
|
|
|
|
|
Well, CodeDOM doesn't do switch so my code generator won't render a switch. Even still it's not much different than the if scenario, except you can use goto case, which i guess makes it a bit like gotos. Not a game changer in any case, if you'll pardon the pun. 
When I was growin' up, I was the smartest kid I knew. Maybe that was just because I didn't know that many kids. All I know is now I feel the opposite.
|
|
|
|
|
Exactly because you have such a complex branching structure, you shouldn't use goto. I'm not sure I fully understand your problem, but it looks like it's in need of either refactoring, or code generation. (or both  ) )
I did use an UML tool for generating code for a state machine some 20 years ago, and it let me choose between using switch statements or inheritance. Our team went with switch, because inheritance seemed over the top, and we had limited resources on our embedded target machine. But if our target system had been a PC, nothing would have stopped us from using inheritance, i. e. one class for each state. Not sure if that would be a suitable approach in your case, just saying that code generators exist for such things, and indeed existed 20 years ago. (for C++)
P.S.: that said, if your code generator does use goto, and you will never have to manage that code manually, then it's ok to do just that. After all, the main reason agaist goto is it's bad behavior regarding maintenance, and that's a non-issue for 100% generated code.
GOTOs are a bit like wire coat hangers: they tend to breed in the darkness, such that where there once were few, eventually there are many, and the program's architecture collapses beneath them. (Fran Poretto)
|
|
|
|
|
The gotos are there for a reason and should be.
The code is generated.
It's either 20 thousands lines of gotos
or 70 thousand lines of what you're talking about.
I'll take the gotos
When I was growin' up, I was the smartest kid I knew. Maybe that was just because I didn't know that many kids. All I know is now I feel the opposite.
|
|
|
|
|
Well, as I said (amybe you haven't seen the P.S. at the time you wrote the answer): if it's generated, it's fine. 20K lines doesn't sound like you're going to maintain that code manually anyway 
GOTOs are a bit like wire coat hangers: they tend to breed in the darkness, such that where there once were few, eventually there are many, and the program's architecture collapses beneath them. (Fran Poretto)
|
|
|
|
|
The issue here is state machines.
There are three ways to implement them:
1. Table driven
2. Goto driven
3. Using code synthesis to achieve while's, fors and ifs like you'd want.
There are a number of problems with #3, aside from code complexity.
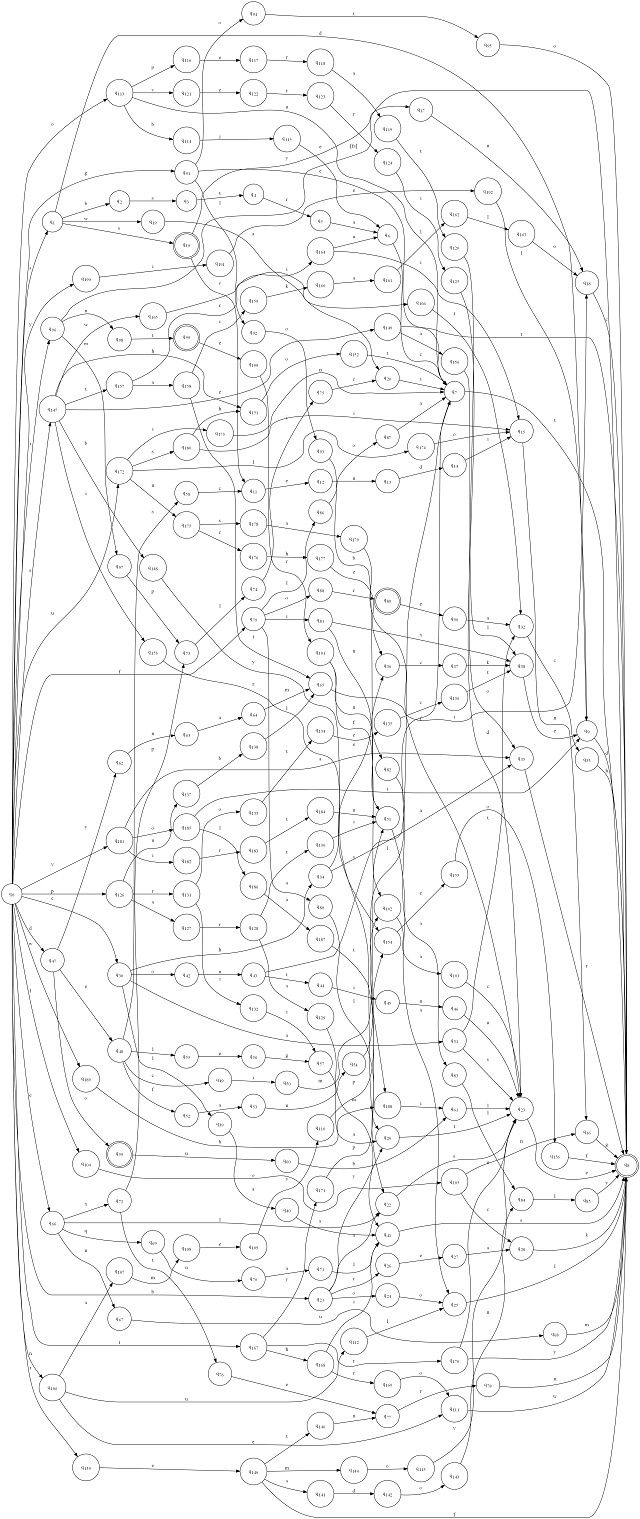
State machines necessarily operate like spaghetti code and must jump freely.
Otherwise paths can't converge and you end up with a lot more code. Consider the following image: C# Keywords DFA[^]
That may seem extreme but it's not. This simply matches C# keywords. This exact state machine could be used in microsoft's production C# lexer (part of the csc.exe compiler) to do exactly that. It certainly would be if it was generated from the same keyword list.
See all the convergent paths? These are impossible to get to without gotos. The equivalent machine without convergent paths is about 5 times! the size. So the code will be, and the nests will be so deep it will be unintelligible anyway.
Edit: I mean yes, you could use inheritance but at that point all you're doing is presenting a facade over "gotos" but it's using the vtbl for it instead of explicit jumps.
It's still nasty when you have 500 states (not uncommon in a lexer) and the code would get huge.
A state is 3-5 lines of code generally in a lex routine. adding a class to that mix at least doubles that i'd think.
And yeah i found it matters. VS chokes on 1MB files when it comes to reporting the position of errors (sometimes)
When I was growin' up, I was the smartest kid I knew. Maybe that was just because I didn't know that many kids. All I know is now I feel the opposite.
modified 6-Jan-20 13:10pm.
|
|
|
|
|
Normally I'd have to add a lot to these statements, but since you're generating code, I'll just say this:
Use whatever works for you. If VS can't handle the code your generator produces, then use another generator option, or a different generator. Discussing the pros and cons of the available methods is meaningless if your code doesn't compile.
That said, I'm not an expert on parsers, but I wonder whether it is the usual approach to implement one as a state machine. Wouldn't it be straightforward to just implement each rule of the grammar as a function that converts a string of tokens (recursively) into a syntax tree? IIRC, there's typically no need to maintain a global state, and therefore no need to construct a state engine. A state would only be needed in case of a context-dependend grammar/language. I may have missed it, but is that what you have to deal with - a context depended language?
GOTOs are a bit like wire coat hangers: they tend to breed in the darkness, such that where there once were few, eventually there are many, and the program's architecture collapses beneath them. (Fran Poretto)
|
|
|
|
|
For the lexer, a state machine is the typical approach.
The state machine technique for the parser is to implement LL(k) similar to how ANTLR implements LL(*)
The reason for this is, creating an LL(k) parser with your technique requires far too much code.
It's both more efficient and more compact to use a state machine rather than a giant parse table.
There's a research paper on doing it this way somewhere but i just googled for it and I can't dredge it up again.
When I was growin' up, I was the smartest kid I knew. Maybe that was just because I didn't know that many kids. All I know is now I feel the opposite.
|
|
|
|
|




 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 








{kind=link}