|
Image generation, text generation, "intelligent" chat bots and all the fun things that Large Language models give us has lead to an explosion of (often inappropriate) AI in applications.
Long running operations such as generative AI require a different approach to managing the response from an AI inference call so added support in CodeProject.AI Server to handle long process such as these.
Instead of 'send command and wait for response' we now offer 'send a command and poll for the status'. The long process (eg 'draw me a cute kitten, please') is sent to the server, which passes it to our new Text2Image module, which then returns the message "I'm on it!". After that you simply poll the server to see how things are going, until eventually you get the final, polished, result.
On a modern CUDA enabled NVIDIA card this could be a second or two. On my very old Intel powered macBook this can be over a minute.

Thee goal for us is not to provide the world with the most accurate or efficient AI tools, but to provide developers with a system that allows them to learn and explore, and ultimately motivate everyone to at least try AI and see how it all works. We try and keep our modules simple, freely useable, and available on the broadest set of hardware and OS we can manage.
It's up to you guys where you take this.
This module will be released under CodeProject.AI Server 2.5.5 this week.
cheers
Chris Maunder
|
|
|
|
|
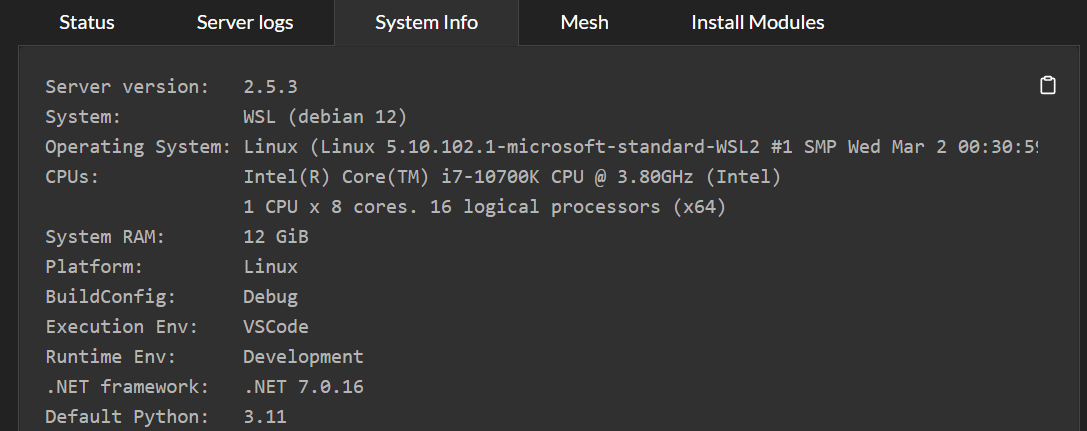
For CodeProject.AI Server on Linux we've focused solely on Ubuntu up until now simply to reduce the testing area. With Ubuntu in x64 and arm64, macOS in x64 and arm64, Windows x64 (with a smattering of arm64 support), and Jetson, Raspberry Pi and Orange Pi, we're up to 9 Operating system combos we have to support, not to mention the various flavours of CUDA.
So let's round it up and add Debian to make it 10.
All in all this was fairly painless apart from the disappointment of not being able to use deadsnakes for our Python install. The huge caveat being that this is all done under WSL, so oddness may ensue.
This will be publicly released in version 2.5.4.
cheers
Chris Maunder
modified 13-Feb-24 14:43pm.
|
|
|
|
|
We've been working on getting Jetson support for months. There's the easy way (create an arm64 Docker image and just go for it) and there's the other way: provide a native Linux installer that runs on the Jetson directly.
NVIDIA provide pre-built docker images that have all the hard work done for you. The only issue is that you have to pick the image that matches your hardware (though we haven't tested running, say, a L4T R32.6.1 image on a L4T R32.7.1 device). This all seems like hard work for the user so instead we'd prefer to have our docker images be generic enough that any Jetson should be able to run the image.
Doing it the hard way means we remove variables such network stacks, driver issues, and issues with docker itself, but it does mean we have to deal with a million tiny and not so tiny challenges, such as hunting for the exact packages and dependencies, worrying about library conflicts, and the setup involved in building many of the libraries we wish to use. It can be weeks of work to get a basic system running on a Jetson with the NVIDIA image.
Instead we used a pre-configured image from QEngineering that not only had an updated version of Ubuntu, it had Torch, Tensorflow, OpenCV and TensorRT, to name a few, already installed.
Coding on a Nano
Coding against the raw hardware allows us to debug a little easier. Except when "easier" involves a tiny 2GB of RAM and SD cards that keep dying due to overuse. However, Visual Studio Code provides such a simple remote development environment that working against a Jetson is just like working on a sturdy desktop. Just with more pauses. And crashes.
The Jetson Nano I'm using is quad core arm64 device running at 1.43GHz with 2GB RAM. It's a bit of a snail, but what it does have is a 128-core Maxwell CUDA enabled GPU. And this is where the fun begins
Result
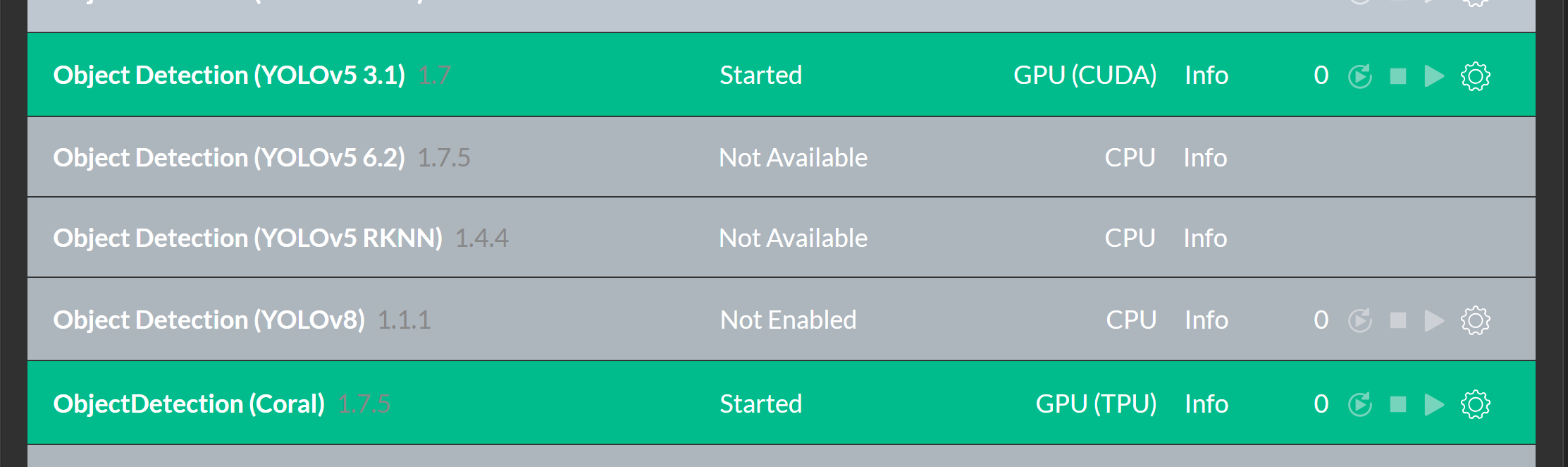
Some small (and large) tweaks to our install scripts for our Coral.AI and YOLOv5 (CUDA10) Object Detection modules and we were on our way:
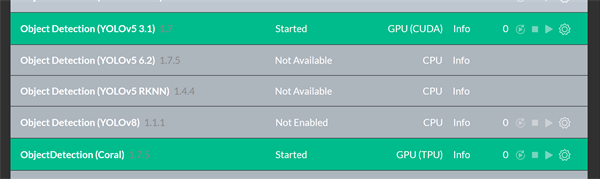
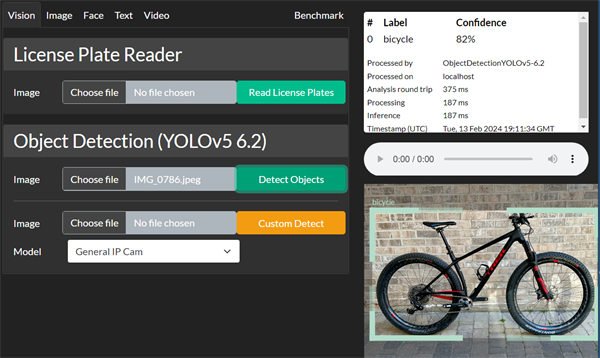
As you can see we have the CUDA GPU engaged for YOLO, and the Coral.AI USB detected and available for Coral.
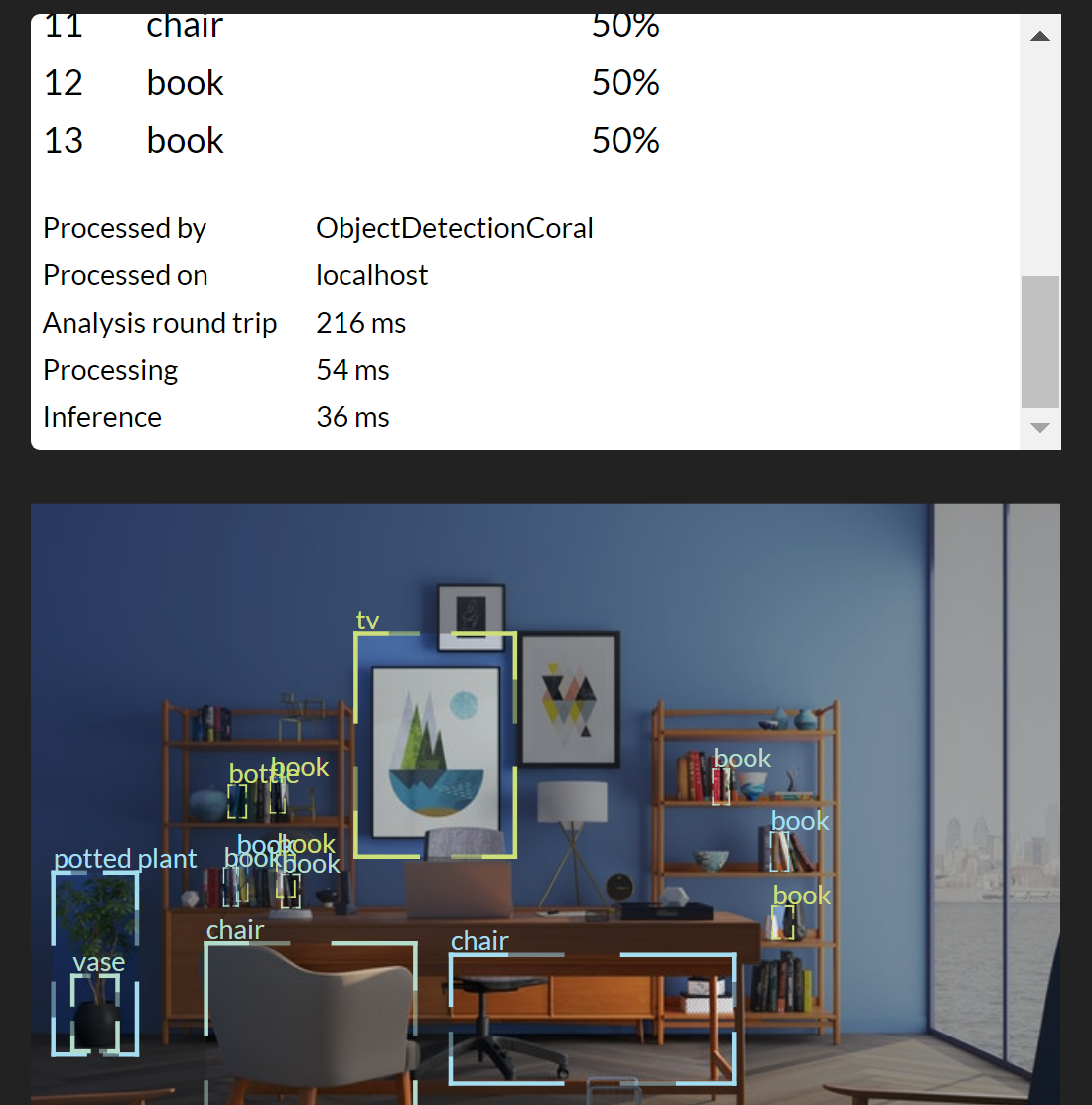
Using the Coral we see decent results:
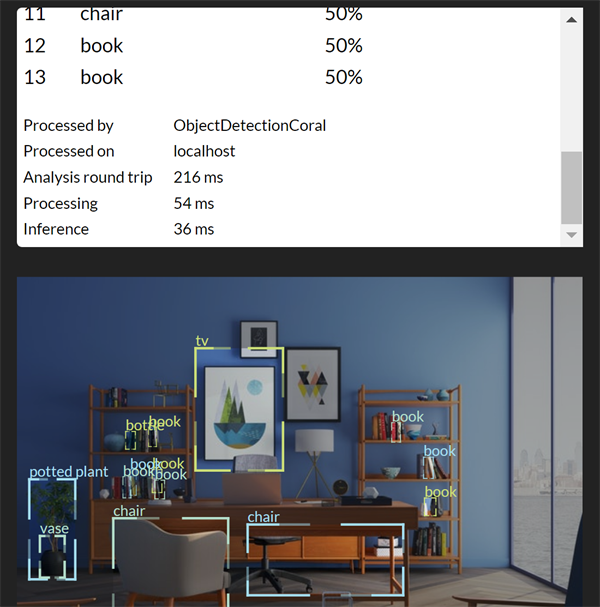
However, even without the Coral TPU we were still seeing inference timings under 100ms.
For YOLO using CUDA on the onboard GPU we could not actually generate results. A 2GB unit simply doesn't have the headroom needed to test what we have, so we'll have to revisit with smaller models. That combined with the challenges of running a server, a debugger, a full IDE and git, while trying to load models just doesn't leave room for actual AI inference when using YOLOv5 and PyTorch.
While we were disappointed we couldn't test YOLO directly on the Jetson, we at least now have a working framework that is limited purely by the hardware.
It's also interesting to note that the QEngineering Jetson image, while making life so much easier (and much of this actually possible in a reasonable amount of time) has a lot of baggage that is sucking up scarce RAM. The NVIDIA image is far leaner, and we were able to get in some solid dev time (rather than loud yelling and gnashing of teeth time). However, the challenges in trying to get the various packages and dependencies installed were beyond painful and became impractical.
The lesson here is that your hardware determines your stack, and that goes all the way down to the size of the models, as well as their architecture, you wish to run.
Next step: TensorRT.
cheers
Chris Maunder
|
|
|
|
|
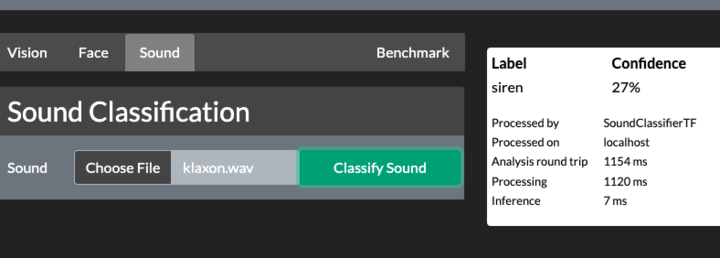
It's late December in Canada so what is one to do other than play around with stuff they simply don't understand. For me this was sound classification using AI.
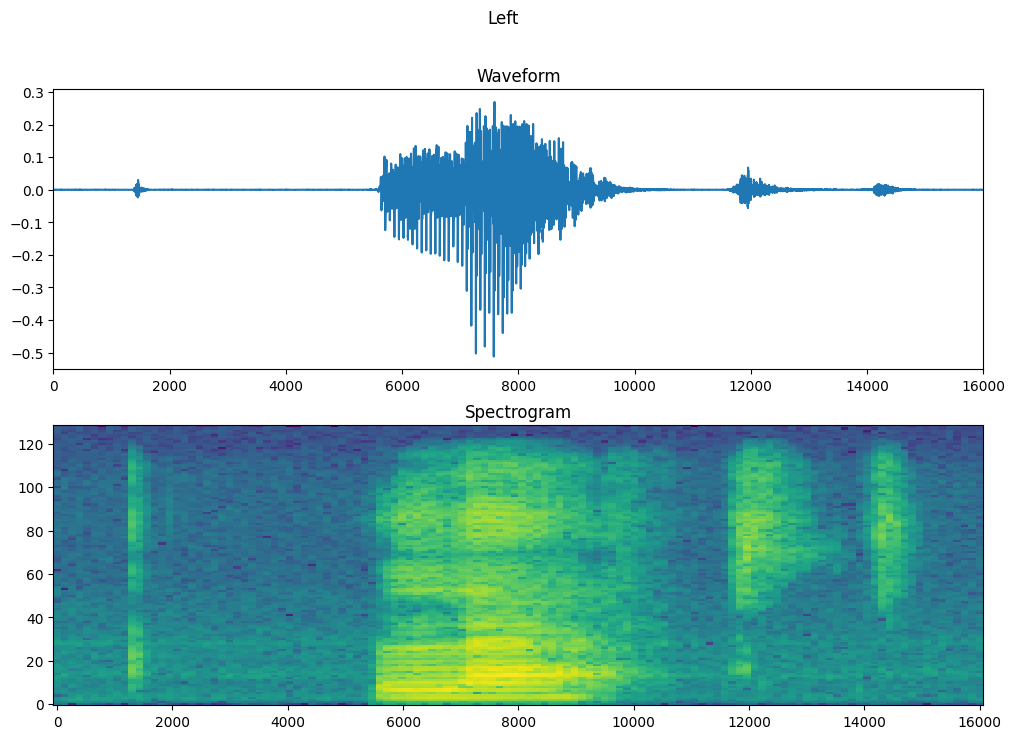
Sound classification in AI can be done in many ways, but the most common way I've seen it done is to convert the sound into an image and then use image classification techniques.
We've probably all seen a wave form and a spectrograph:
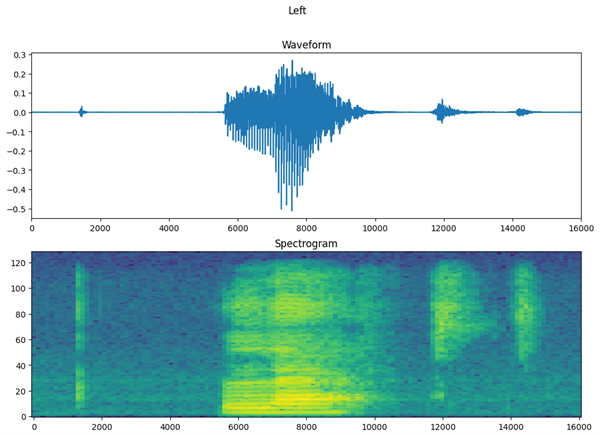
From TensorFlow.org
A WAV file is decomposed into its component frequencies using a Fast Fourier Transform, and then represented as a spectrogram: time along the x-axis, frequency on the y-axis, and intensity given by colour. It turns out that this generally provides enough information to classify a sound, in image form, just like any other image can be classified.
Sound is usually far noisier than an image, and when thinking of sound as an image, think of all the elements of a normal image, but with each element as being translucent. Everything can be "seen" through everything else, resulting in a murky image.
Even so, after learning all about how Tensorflow 1.X code does not work out of the box with Tensorflow 2.X, how macOS isn't actually supported by Tensorflow, and how the UrbanSounds8K model doesn't actually have 8,000 sound classes, but only a disappointing 10, we have a prototype sound classification module ready for our next release.
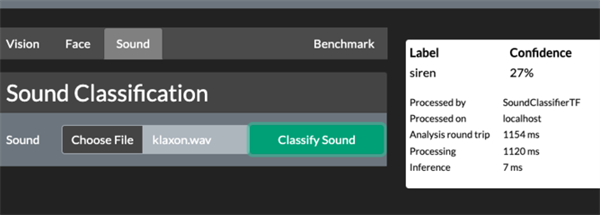
You'll probably notice that the inference time is amazing. The processing time...not so amazing. There's a lot of work to turn a WAV file into a spectrogram, unfortunately, but we're sure we can speed things up a little.
cheers
Chris Maunder
|
|
|
|
|
One of the core issues we face when handling AI related tasks is computing power. Generally the bigger the better, but you can get away with a lower calibre machine if you aren't stressing it too much. But what happens when an unexpected load hits and your tiny machine starts to creak and groan? What you really want is a system to allow you to offload AI tasks to other servers if you have other servers sitting around with capacity to take on work.
Here’s one I prepared earlier.

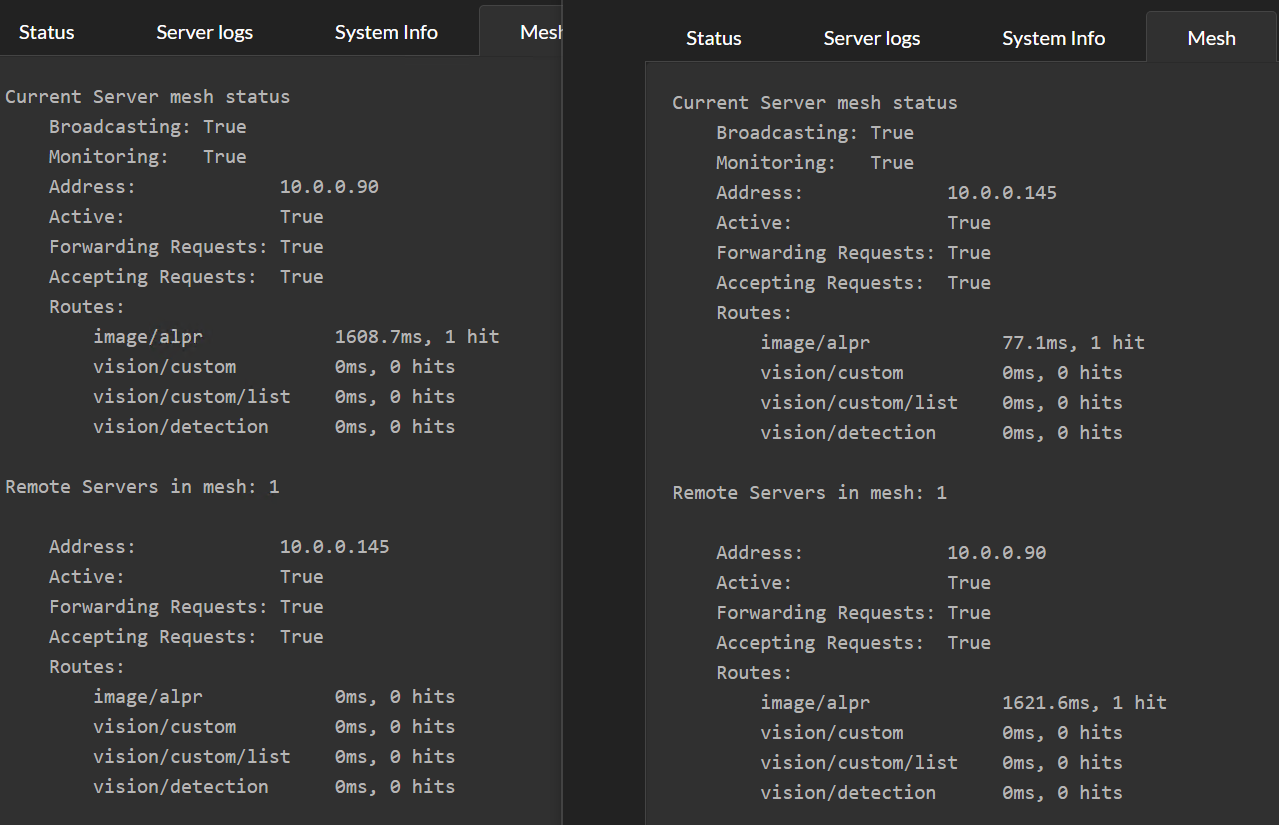
What you're seeing are two machines, each with CodeProject.AI Server installed, each with the new Mesh functionality enabled.
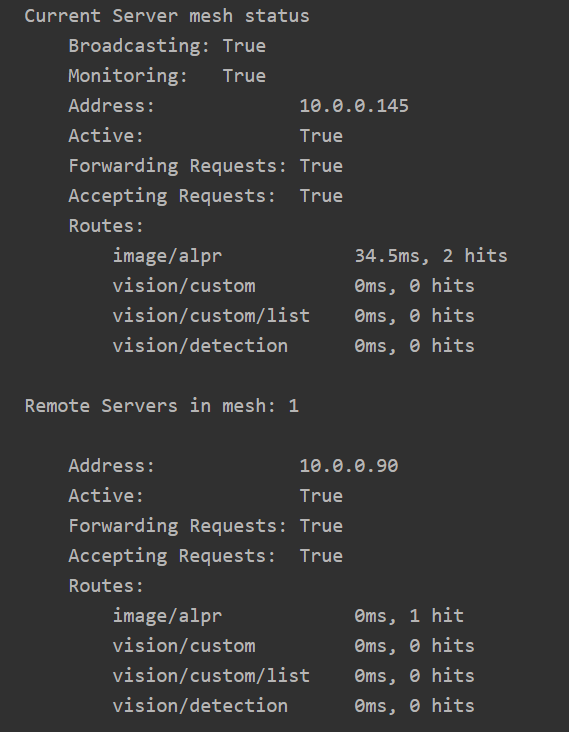
Each server will handle its own requests, but is also aware of other servers in the mesh and will send requests to other servers if it thinks another server can do better. To determine whether another server can do better, each server will simply try out the other servers and see how they go. From then on the server receiving a request will either process the request itself, or pass it to another server if another server can do it faster.
In the above image, server .145 processed two ALPR requests. The first it handled itself with a 77ms response. The second request it passed to the remote .90 server, which recorded a response time of 1621ms. The remote server will not get any further requests while it's response time is that high.
After a (configurable) period of time, the recorded response time of remote servers will "decay". Older request timings are discarded and the "effective" response time heads back to 0
Notice on .90, the response time for ALPR is now at 0.
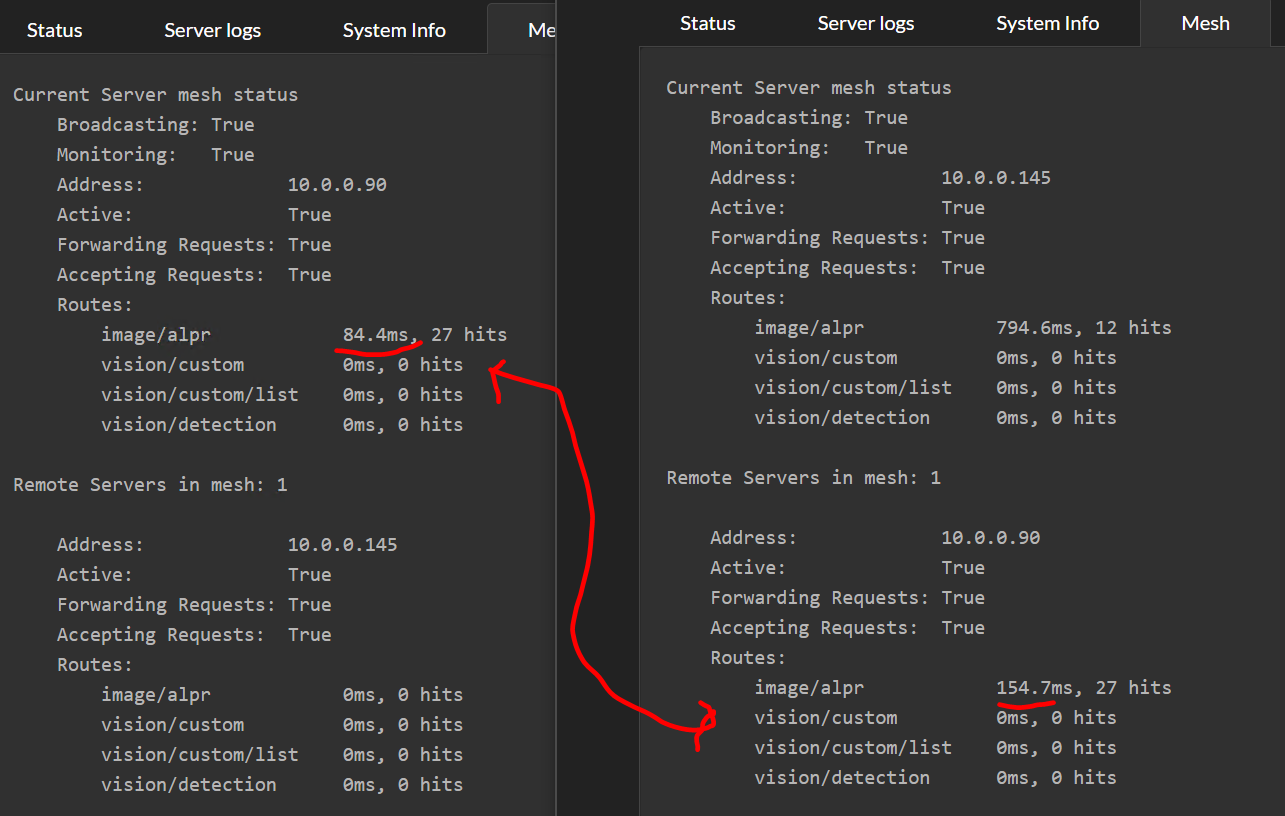
Now imagine it's Black Friday and the carpark security goes nuts at 6AM. The current server gets a deluge of requests and can't keep up. The effective response time of the current server increases 10X to be nearly 800ms, and so it starts offloading requests to the other server.
The other server has warmed up, and that 16 second inference is nowhere in sight. The remote server runs a decent GPU and its local response time, even under load, is around 80ms
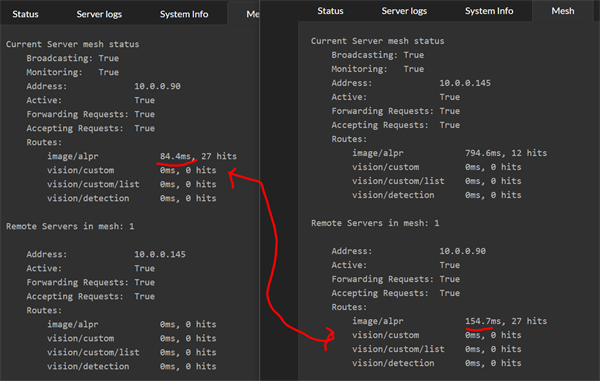
What we now see in the Mesh summary tab for the current server is the remote server processing the majority of the AI operations with an effective response time of 154ms. On the remote server, we see that it reports an effective response of 84ms, but remember that the remote server's timing doesn't include the network roundtrip or work involved in repackaging the initial AI request.
Mesh processing is purely optional and the dashboard makes it trivial to turn it on and off. There is zero configuration needed. All servers self-discover the mesh, register and unregister themselves from the mesh, and load balancing is built in. This feature will be available in the next 2.4.0 release.
We hope this makes life a little more...balanced.
cheers
Chris Maunder
|
|
|
|
|
After several false starts, some handy updates from the PaddleOCR team, and a custom built PaddlePaddle wheel from the guys at QEngineering, we have PaddlePaddle and PaddleOCR running natively on the Raspberry Pi.
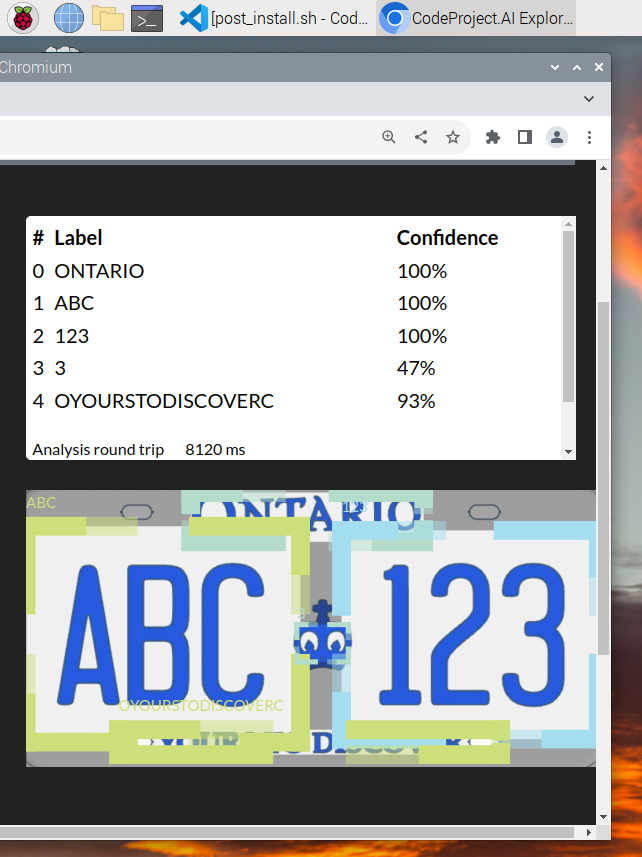
It's not fast, granted, but it works. The task now is simply to optimise. The entire exercise was more about providing greater flexibility for installing modules on systems such as the Raspberry and Orange Pi or the Jetson boards. By introducing system specific module settings and requirements files we can provide that extra level of fine tuning for systems that need a little more... persuasion.
This update will be released, with full code as always, in the next few hours.
cheers
Chris Maunder
|
|
|
|
|
With much expectation we released version 2.2.0 of CodeProject.AI Server. Everything looked great, we'd tested locally, tested Docker, tested our new Ubuntu and Debian installer, our new macOS Intel and Apple Silicon installers, and pounded the Windows version in the debugger till our fingers were raw.
Nothing could go wrong.
So, once we finally tracked down the bug that caused such a kerfuffle we couldn't work out why there was that bug.
In short, we changed the way a script worked. Instead of install scripts specifying the version of python they use 3 in different places, we now set the version once as a global, and the methods the install script call will just query the global variable. No, it's not technically pretty, but we want a simple coding experience for module install scripts, not prizes for best practices.
All good, all very easy, except the installed version was reverting to the previous behaviour. Instead of the utilities grabbing the global variable, they were looking for the passed-in values and failing when they didn't see anything passed in. We'd updated the utility scripts but they were behaving like the previous version.
How is it that we install one version of a script, but what we see on the other end is the script from a different time?
The answer was pretty simple: we forgot to add that script to our new installer. Which then raised the question: How does a script that was removed, and no longer on the system, manage to leap from whatever netherworld it was banished to and appear in this current reality?
That answer was simple too: WiX.
The entire reason we built a new installer was because we ran out of patience with WiX. Doing anything crazy and wild like specifying a new installation location was beyond painful. In moving to Inno Setup we also discovered that WiX was adding the wrong GUID in the wrong place (at least the wrong place as we and the docs seemed to think) and so uninstalling was...a problem.
So we have a new installer. An upgrade is often done by calling the previous installer's uninstall methods, then calling the new installers install methods. But what if the directions to find the previous uninstaller were placed incorrectly in the registry? Then you have an installer that can't uninstall, but instead installs on top of the previous installation.
So the combination of a missing file plus an install on top of a previous install means we end up with the previous version's file.
Now if only we can get a reliable .NET SDK install...
cheers
Chris Maunder
|
|
|
|
|
For those who have spare macs and mac minis lying around, we have a macOS installation package almost ready.
Server version: 2.1.12-Beta
Operating System: macOS (Darwin 22.5.0 Darwin Kernel Version 22.5.0: Mon Apr 24 20:53:44 PDT 2023; root:xnu-8796.121.2~5/RELEASE_ARM64_T8103)
CPUs: Apple M1 (Apple)
1 CPU x 8 cores. 8 logical processors (Arm64)
GPU: Apple Silicon (Apple)
System RAM: 16 GiB
Target: macOS-Arm64
BuildConfig: Release
Execution Env: Native
Runtime Env: Production
.NET framework: .NET 7.0.0
System GPU info:
GPU 3D Usage 0%
GPU RAM Usage 0
Video adapter info:
Apple M1:
Driver Version<br />
Video Processor Apple M1
Global Environment variables:
CPAI_APPROOTPATH = /Library/CodeProject.AI Server/2.1.12
CPAI_PORT = 32168
A huge caveat here is that this isn't a real ".app" app. It's a package installer that places the server binaries and resources into /Library/CodeProject.AI Server and provides a .command file for launching. Installation happens through the macOS installer, but uninstalling requires a single bash command. Install takes just a few seconds.
We're just cleaning up some modules that aren't as happy running natively on macOS as they are in the dev environment or in Docker. Just issues with paths and build/publish quirks, but nothing dramatic.
Separate x64 and arm64 .pkg files will be provided as part of our next minor update (2.2)
Update: Turns out Ubuntu installers are not that hard either:
Server version: 2.1.12-Beta
Operating System: Linux (Linux 5.15.90.1-microsoft-standard-WSL2 #1 SMP Fri Jan 27 02:56:13 UTC 2023)
CPUs: Intel(R) Core(TM) i7-10700K CPU @ 3.80GHz (Intel)
1 CPU x 8 cores. 16 logical processors (x64)
System RAM: 8 GiB
Target: Linux
BuildConfig: Release
Execution Env: Native
Runtime Env: Production
.NET framework: .NET 7.0.9
System GPU info:
GPU 3D Usage 0%
GPU RAM Usage 0
Video adapter info:
Global Environment variables:
CPAI_APPROOTPATH = /usr/bin/codeproject.ai-server-2.1.12
CPAI_PORT = 32168
cheers
Chris Maunder
modified 1-Sep-23 16:17pm.
|
|
|
|
|
The Coral TPU has always held the promise of cheap, fast AI inferencing but it's always felt like The Project That Was Left Behind. The documentation reference a version of Tensorflow Lite compiled specifically for the Coral, and then PyCoral libraries themselves, both of which stopped being supported for macOS at macOS version 11 for Intel chips, and 12 for Apple Silicon. Python 3.9 is the latest interpreter supported on both these platforms.
Serendipitously my iMac, which I use purely as a Bootcamp machine, still had macOS 11 installed so in re-running the setup scripts and tweaking things a little, Coral support on the Macs is a thing. If you haven't upgraded your OS.
On a Mac, this is more a theoretical and development curiosity for those working with CodeProject.AI Server, but 11ms inference is still a win.

Update
We've been testing CodeProject.AI server on Linux by using WSL in Windows. Generally this works very well, except in the case of USB devices. Previous efforts to get Coral working under WSL failed, but we've made the switch to testing Linux using Ubuntu 22.04 on bare metal, and we're pretty stoked to see the Coral working perfectly out of the gate.

cheers
Chris Maunder
modified 11-Aug-23 12:02pm.
|
|
|
|
|
It's working! It's working!!!!!! And much better response speeds than running on Windows! Averaging 148ms on Medium!!!
Thank you Chris. This is huge!
(Is there any way to enable the desk-melting version of the
libedgetpu1 ? Apparently it's not really possible to destroy the thing, it just gets hot. Someone ran it for months at maximum and nothing bad happened. Mine's not going to be analyzing at maximum capacity for months at a time, and I'm not touching it, so it should be fine.)
|
|
|
|
|
That's a great data point (and maybe the reason most AI work is done on Linux  ) )
To get it to install the oven-mitts version you could try
sudo apt-get remove libedgetpu1-std -y
sudo apt-get install libedgetpu1-max -y
cheers
Chris Maunder
|
|
|
|
|
It worked! Well, I had to use this for the second one since it requires the "yes" and the CPAI Docker sets the interactive mode to noninteractive, even in an interactive shell inside the container:
DEBIAN_FRONTEND=dialog sudo apt-get install libedgetpu1-max
I made a post on how I got this to work in Docker too. Working great! The Medium speeds went from 148ms to 112ms after doing this.
CodeProject.AI Server: AI the easy way.[^]
Is it possible to add an environmental variable to the Docker image to use the oven-mitt mode for Coral? I can always write a Dockerfile myself on top of yours and use that, but could be cool as an option.
|
|
|
|
|
After running perfectly for a day and a half, the Coral suddenly started giving the "The interpreter is in use" error. Blue Iris didn't indicate anything was wrong, just "Nothing was found", which is not good. After restarting the Docker container, the Coral went back to normal. (This error seems to be common, see here)
If there's no good way to fix this problem, maybe a health check can be implemented for the Docker image to restart the process or the entire container whenever the "The interpreter is in use" error is seen.
|
|
|
|
|
Chris, can you add a Docker environment variable that installs the libedgetpu1-max driver instead of the standard one? I've been using the max driver for a couple months and it works faster, without overheating.
|
|
|
|
|
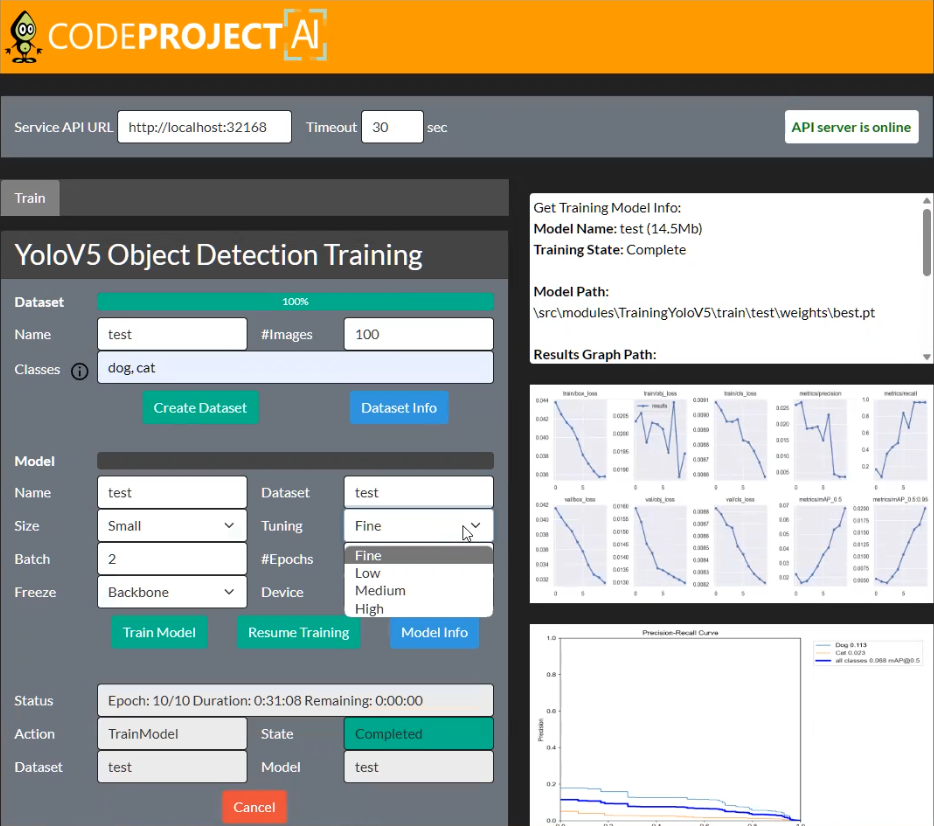
CodeProject.AI Server now allows you to train your own models!
Adding Object Detection to your apps is easy with CodeProject.AI Server, but you’ve been limited to the models you could find by hunting around and testing by trial and error. We’ve now added the ability to train your own YOLOv5 Object Detection models with just a couple of clicks.
All you do is choose the types of objects you wish to detect (from one of the 600 classes in Google's Open Images Dataset V7). Select how many images you want to use for training, select the model size, then click to build the dataset automatically, and then another click to train your model. Reuse the same dataset on subsequent model builds in case you want to create larger or smaller models, or fine tune the training parameters. It doesn’t get easier than that.
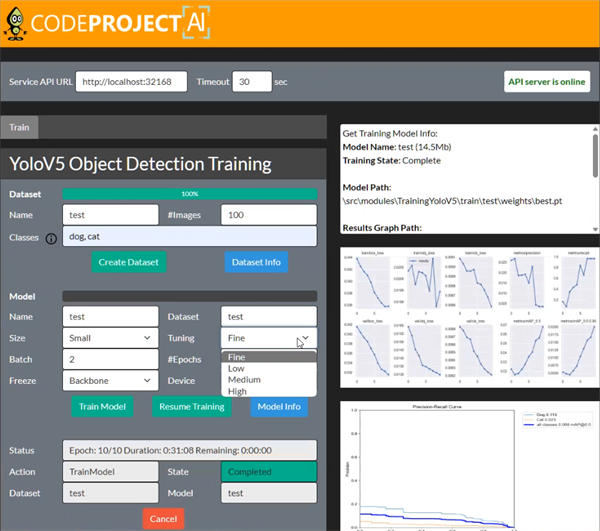
Open Images is a series of thousands of images Google has gathered that have each identifiable object in the image tagged with a bounding box and a label. For example, a mechanical fan.

Ideally this is for those who have a decent GPU because of the processing power required. You can train these models with a decent CPU setup, it will just take much, much longer. While you can train models off smaller sets of images, like 100, for greater accuracy in your detections you would want 1000 images or more.
You can get a comprehensive list of all the Open Images object classes here. For those who have searched in vain for a custom object detection model specifically for knives, trucks, swimming pools, falcons, flowerpots, and ostriches in a single model, your dream has come true.
CodeProject.AI Server's Object Detection Training has a number of applications outside of the opportunity to train a more custom model, it could also be used to train models to help ignore certain images from your camera feed that are always present and interfering with your detections.
So, whether you live in Derry and are interested in knowing if there’s a suspicious clown wandering around, or you really want to exclude that plant from your backyard detections, or you just really want to know how many lynxes are on your driveway, give CodeProject.AI Server's new Object Detection Training a try.
Thanks,
Sean Ewington
CodeProject
modified 4-Aug-23 11:49am.
|
|
|
|
|
CodeProject.AI Server 2.1.8 is now available!
With 2.1.8 we're hoping to get rid of hangs, have better resource usage, and some other general bug fixes.
If you were experiencing a hang on the CodeProject.AI Dashboard, or noticing some additional CPU, memory, or GPU usage, 2.1.8 should resolve those issues.
In addition, if you are a Blue Iris user and were experiencing error 500, please try the latest Blue Iris release, version 5.7.5.6, which should resolve the problem.
As always, please check our README if you are having issues, and if none of those are your issue, please leave a message on our CodeProject.AI Server forums.
Thanks,
Sean Ewington
CodeProject
|
|
|
|
|

CodeProject.AI Server is now available on the most popular version of Home Assistant, Home Assistant Operating System!
Technically CodeProject.AI Server has been available on Home Assistant since March as a custom repository, but that implementation and the article demonstrating the installation was on Home Assistant Container.
Home Assistant OS is by far the most popular installation choice of Home Assistant users, according to Home Assistant Analytics, with 68.2% of users opting to use Home Assistant OS.
Now we have an article that walks through, step by step, installing Home Assistant OS on a Raspberry Pi 4, setting up CodeProject.AI Server as a custom repository on Home Assistant OS, and demonstrating a practical use case where CodeProject.AI detects a person and HAOS sends a snapshot of the detected person and notification to Home Assistant Companion, the Home Assistant mobile app.
If you're looking for an artificial intelligence solution for Home Assistant, CodeProject.AI Server is constantly being updated, and we'll be releasing more articles demonstrating how to set up various detection scenarios and automations in Home Assistant.
Thanks,
Sean Ewington
CodeProject
modified 1-May-23 15:10pm.
|
|
|
|
|
CodeProject.AI Server 2.1 is released[^]! The big thing in 2.1 is module control. When you first launch CodeProject.AI Server 2.1, Object Detection (Python and .NET), as well as Face Processing, are automatically installed (rather than the installer installing them), but these modules can now be uninstalled. Every other module can installed, re-installed, uninstalled, or updated from the Modules tab.

We've also added a module for Object Detection on a Raspberry Pi using Coral and a module to Cartoonise images (for fun).
There are a heap of other improvements like better logging, half-precision support checks on CUDA cards, bug fixes, and we’ve made it so that modules are versioned so that our module registry will now only show modules that fit your current server version.
Thanks to everyone for all the support and usage of CodeProject.AI Server so far. We're dedicated to making further improvements so please feel free to give your feedback on our CodeProject.AI Discussions[^] forum. And please give 2.1 a try[^]!
Thanks,
Sean Ewington
CodeProject
modified 21-Apr-23 13:27pm.
|
|
|
|
|
Inspired by this I decided see how hard it would be to add a cartooniser to CodeProject.AI Server
 
Pretty easy!
Module is due out today.
cheers
Chris Maunder
|
|
|
|
|
I was wondering if I could use images of real people and cartoonize it and then I am allowed to post such pictures without getting in trouble in case those people want to file complaints about me using their pictures or something similar at my diseño web (spanish) site.
Thanks on advance
|
|
|
|
|
Home Assistant is an IoT home automation tool with a lot of possibilities because it can integrate with various devices and services. With Home Assistant and the right devices you can have things like: a dashboard with all your cameras visible (from your phone, too), an auto-lock for the front door after it’s been closed for three minutes, an alarm system that arms when all the registered users are away, and the ultimate (for some reason) a garage door that automatically closes if it’s been open for a period of time.
There are a lot of potential applications of CodeProject.AI Server and Home Assistant. I’m currently finishing an article that using CodeProject.AI and Home Assistant, detects when a person is in a camera frame, starts recording, and takes a snapshot and sends it to your phone.
For now though, check out the CodeProject.AI-HomeAssist repository[^]. Read up on how to use it, what it can do. Or, you can go straight to the guide that shows, step by step, How to Setup CodeProject.AI Server with Home Assistant Container[^].
Thanks,
Sean Ewington
CodeProject
|
|
|
|
|
|
When shutting down CodeProject.AI Server we kept seeing processes remain alive. One of the issues was that if you terminate a Python process from a virtual environment you need to be aware that there are actually two processes running. Here's our solution: Terminating Python Processes Started from a Virtual Environment.
Thanks,
Sean Ewington
CodeProject
|
|
|
|
|
One of the great perks of CodeProject.AI Server 2.0 is that it now allows analysis modules to be downloaded and installed at runtime.
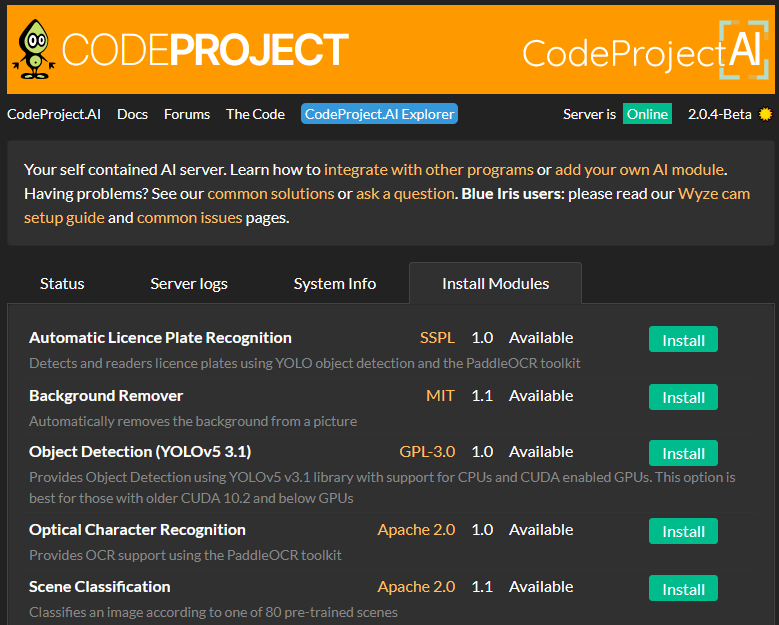
In previous versions, we would include a number of modules, which, if we're honest, made the install quite large. Now that we're expanding the modules we offer (Automated License Plater Reader, Optical Character Recognition, Coral support), it made sense to make this more customizable. As of 2.0, the only modules CodeProject.AI Server installs by default are Object Detection, and Face Processing.
In fact there are actually two Object Detection modules. One is a .NET implementation that uses DirectML to take advantage of a large number of GPUs, including embedded GPUs on Intel chips. The other is a classic Python implementation that targets CPU or NVidia GPUs. Each module performs differently on difference systems, so the inclusion of both allows you to easily test which one suits you best.

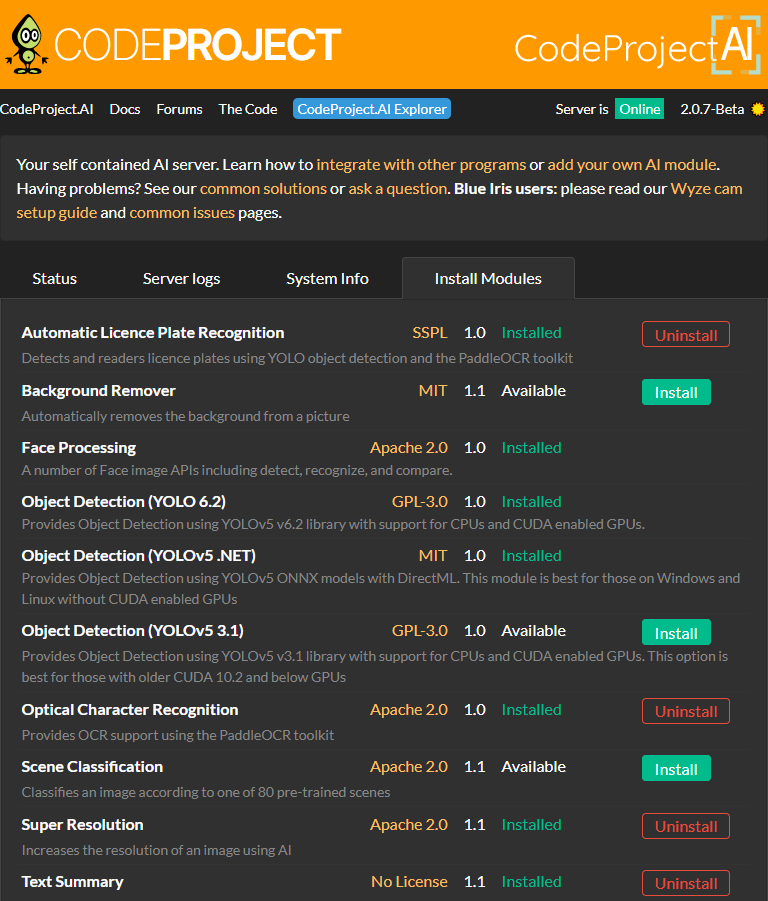
To install a module you want, simply go to the Install Modules tab, and click the Install button. That's it! The module automatically pulls and installs for you.
If you no longer want a module installed, simply click Uninstall, and the module will be removed.
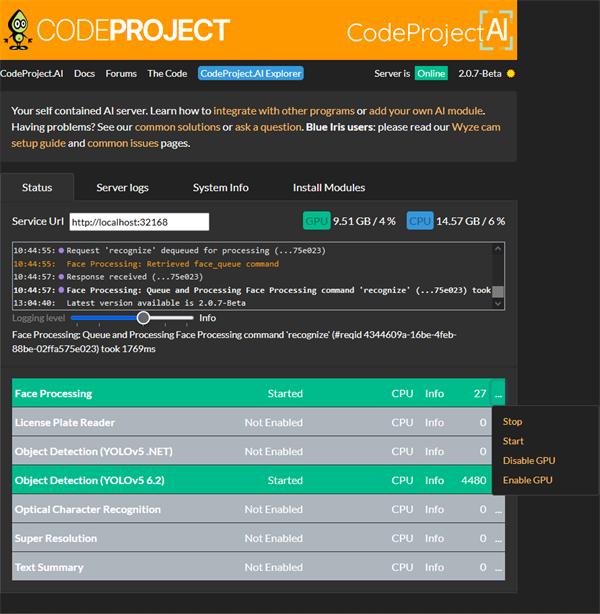
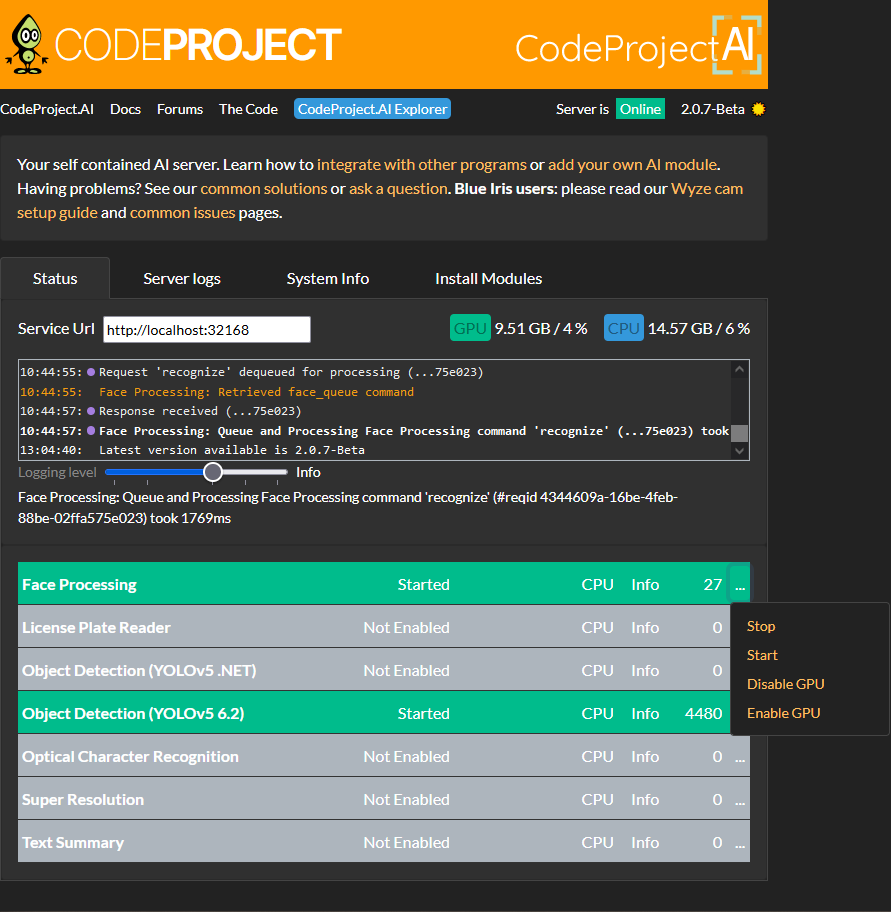
As always, you can still toggle which modules you want active from the Status tab. Simply click on the ... dropdown in the desired module and hit Start or Stop.
In addition, if a module needs an updated, simply go to the Install Modules tab, and click the Update button.
Our goal is to make AI as accessible and easy to use as possible. If you've struggled to play around with AI in the past, give version 2.07 a try.
Thanks,
Sean Ewington
CodeProject
|
|
|
|
|
CodeProject.AI Server 2.0.5 is officially released! This version has a plethora of additions and we're hoping will be a greater foundation for AI functionality moving forward.
The biggest part of CodeProject.AI Server 2.0.5 is the runtime ability to install / uninstall modules.
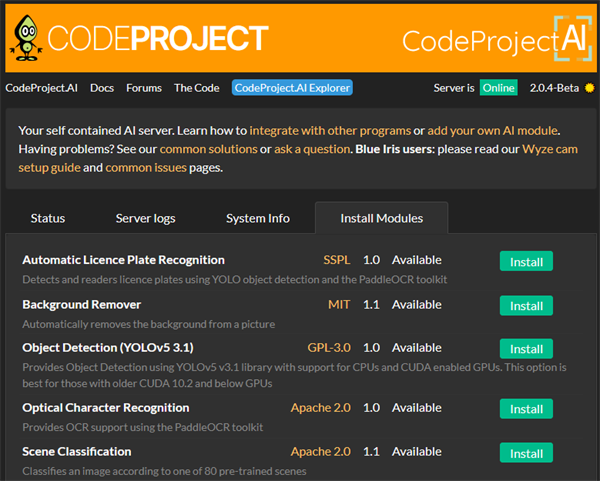
We have a new Module Repository which allows us to add, update and remove modules separately from the main server installation is more compact, it also provides more options for module use. For example, version 2.0.5 now includes a module (Object Detection YOLOv5 3.1), based on an older version of PyTorch, which is ideal for those with older CUDA 10.2 and below GPUs.
In addition, CodeProject.AI Server now includes an Automatic License Plate Recognition (ALPR) module for detecting and reading license plates and an Optical Character Recognition module.
We have also improved our .NET based Object Detection module with increases in detection speeds by up to 20%. This modules uses ML.NET, which provides support for a wide range of non-CUDA GPU cards, including embedded Intel GPUs.
If you're interested in learning, or getting involved in AI, download CodeProject.AI Server version 2.05 today.
Thanks,
Sean Ewington
CodeProject
|
|
|
|
|


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin