Introduction
With Office 2007, Microsoft decided to change default application formats from old, proprietary, closed formats (DOC, XLS, PPT) to new, open, and standardized XML formats (DOCX, XLSX, and PPTX). The new formats share some similarities with the old Office XML formats (WordML, SpreadsheetML) and some similarities with the competing OpenOffice.org OpenDocument formats, but there are many differences. Since the new formats will be default in Office 2007 and Microsoft Office is the most predominant office suite, these formats are destined to be popular and you will probably have to deal with them sooner or later.
This article will explain the basics of the Open XML file format, and specifically the XLSX format, the new format for Excel 2007. Presented is a demo application which writes / reads tabular data to / from XLSX files. The application is written in C# using Visual Studio 2005. The created XLSX files can be opened using Excel 2007.
Microsoft Open XML format
Every Open XML file is essentially a ZIP archive containing many other files. Office-specific data is stored in multiple XML files inside that archive. This is in direct contrast with the old WordML and SpreadsheetML formats which were single, non-compressed XML files. Although more complex, the new approach offers a few benefits:
- You don’t need to process the entire file in order to extract specific data.
- Images and multimedia are now encoded in native format, not as text streams.
- Files are smaller as a result of compression and native multimedia storage.
In Microsoft’s terminology, an Open XML ZIP file is called a package. Files inside that package are called parts. It is important to know that every part has a defined content type and there are no default type presumptions based on the file extension. The content type can describe anything; application XML, user XML, images, sounds, video, or any other binary objects. Every part must be connected to some other part using a relationship. Inside package are special XML files with a “.rels” extension which defines relationship between parts. There is also a start part (sometimes called “root”, which is a bit misleading because the graph containing all parts doesn’t have to be a tree structure), so the entire structure looks like in picture 1.
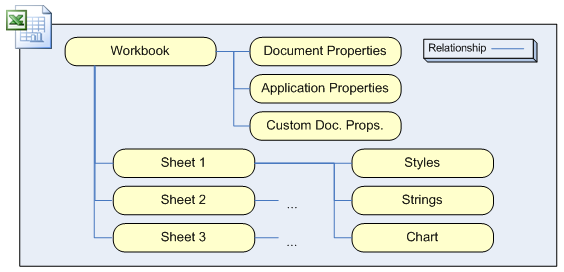
Picture 1: Parts and relations inside an XLSX file.
To cut a long story short, in order to read the data from an Open XML file, you need to:
- Open package as a ZIP archive – any standard ZIP library will do.
- Find parts that contain data you want to read – you can navigate through a relationship graph (more complex), or you can presume that certain parts have a defined name and path (Microsoft can change that in the future).
- Read parts you are interested in – using the standard XML library (if they are XML), or some other method (if they are images, sounds, or some other type).
On the other side, if you want to create a new Open XML file, you need to:
- Create/get all necessary parts – by using some standard XML library (if they are XML), by copying them, or by using some other method.
- Create all relationships – create “.rels” files.
- Create content types – create a “[Content_Types].xml” file.
- Package everything into a ZIP file with appropriate extension (DOCX, XLSX or PPTX) – any standard ZIP library will do.
The whole story about packages, parts, content types, and relations is the same for all Open XML documents (regardless of the originating application), and Microsoft refers to it as Open Packaging Conventions.
Excel 2007 Open XML specifics
Excel 2007 extends on the basis of Open Packaging Conventions by adding its own application-specific XML types. Reference schemas for all XML files used in Office can be downloaded from MSDN, but note that some things are still open to change until the final Excel 2007 release.
We just want to write / read worksheet data, so we need to look in the folder “\xl\worksheets” inside the XLSX file, where all the worksheets are located. For every worksheet, there is a separate XML file; “sheet1.xml”, “sheet2.xml”, and so on. When you open such a file, you will notice that all of the sheet data is inside the <sheetData> element. For every row, there is a <row> element; for every cell, there is a <c> element. Finally, the value of the cell is stored in a <v> element.
However, real world XML is never simple as schoolbook XML. You will notice that numbers get encoded as numbers inside the <v> element:
<c r="A1">
<v>100</v>
</c>
However, a string value (like “John”) also gets encoded as number:
<c r="B1" t="s">
<v>0</v>
</c>
That is because MS Excel uses an internal table of unique strings (for performance reasons). Zero is an index of that string in an internal table of strings, and attribute t="s" tells us that the underlying type is a string, not a number. So where is the table of unique strings located? It is in the “\xl\sharedStrings.xml” XML file, and contains all strings used in the entire workbook, not just the specific worksheet.
This approach is used for many other things; cell styles, borders, charts, number formats, etc. In fact, that becomes the major programming problem when working with XLSX files – updating and maintaining various tables of some unique Excel objects. In this article, we will just write / read data values, but if you require some complex formatting, you should probably be better using some commercial component which does all the tedious work for you.
Implementation
Our demo is a Windows Forms application (see picture 2), written in C#, using Visual Studio 2005. Since there is no support for ZIP files in .NET Framework 2.0 (only for the ZIP algorithm), our demo uses an open-source ZIP library called SharpZipLib. For demonstration purposes, we will extract the entire ZIP files to a TEMP folder, so we can examine the contents of that folder and files while debugging the demo application. In a real world application, you may want to avoid extracting to the temporary folder and just read to / write from the ZIP file directly.
For XML processing, the choice is simple. For reading XML files, we use the XmlTextReader class, and for writing, we use the XmlTextWriter class. Both come with the .NET Framework, but you can also use any other XML processing library.

Picture 2: Demo application in action.
Data reading
We want to read a simple “In.xlsx” file (in the “Input” folder) and copy its contents to the DataTable. That file contains a list of people with their first and last names (text values) and their IDs (number values). When the “Read input .xlsx file” button in clicked, the following code is executed:
private void buttonReadInput_Click(object sender, EventArgs e)
{
string fileName = this.textBoxInput.Text;
ExcelRW.DeleteDirectoryContents(ExcelRWForm.tempDir);
ExcelRW.UnzipFile(fileName, ExcelRWForm.tempDir);
FileStream fs = new FileStream(ExcelRWForm.tempDir +
@"\xl\sharedStrings.xml",
FileMode.Open, FileAccess.Read);
ArrayList stringTable = ExcelRW.ReadStringTable(fs);
fs = new FileStream(ExcelRWForm.tempDir +
@"\xl\worksheets\sheet1.xml",
FileMode.Open, FileAccess.Read);
ExcelRW.ReadWorksheet(fs, stringTable, this.data);
}
Nothing unusual happens here. The XLSX file is unzipped to the TEMP folder and then the necessary XML parts (now files) are processed. The file “sharedStrings.xml” contains a global table of unique strings while the file “sheet1.xml” contains data for the first sheet. Helper methods are pretty straightforward XML reading code -- you can download the demo application code to examine them in more detail.
If everything is OK, after the button click, all data will show up in the DataGridView.
Data writing
Now, we want to write data from a DataTable to the “Out.xlsx” file in the “Output” folder. You can change some data, or add some new rows in the DataGridView. When the “Write output .xlsx file” button is clicked, the following code is executed:
private void buttonWriteOutput_Click(object sender, EventArgs e)
{
string fileName = this.textBoxOutput.Text;
ExcelRW.DeleteDirectoryContents(ExcelRWForm.tempDir);
ExcelRW.UnzipFile(ExcelRWForm.templateFile, ExcelRWForm.tempDir);
Hashtable lookupTable;
ArrayList stringTable =
ExcelRW.CreateStringTables(this.data, out lookupTable);
FileStream fs = new FileStream(ExcelRWForm.tempDir +
@"\xl\sharedStrings.xml", FileMode.Create);
ExcelRW.WriteStringTable(fs, stringTable);
fs = new FileStream(ExcelRWForm.tempDir +
@"\xl\worksheets\sheet1.xml", FileMode.Create);
ExcelRW.WriteWorksheet(fs, this.data, lookupTable);
ExcelRW.ZipDirectory(ExcelRWForm.tempDir, fileName);
if (this.checkBoxOpenFile.Checked)
System.Diagnostics.Process.Start(fileName);
}
This time, the code is a bit more complicated. In order not to generate all necessary parts needed for the XLSX file, we decide to use a template file. We extract the template file to the temporary folder, and then just change the XML parts containing the shared string table and worksheet data. All other parts, relationships, and content types stay the same -- so we don’t need to generate any of that. Note that, we use two string tables; a lookup Hashtable for fast searching, and an ordinary ArrayList where items are sorted by their index. We could pull it out only with the ArrayList, but then we would need to search the entire ArrayList every time we add a new string (to check if it is already there). The CreateStringTables() helper method builds both string tables, the WriteStringTable() helper method writes the string table XML, and the WriteWorksheet() helper method writes the worksheet data XML.
Again, download the demo application code to examine the helper methods in more detail.
Download links
You can download the latest version of the demo application (together with the C# source code) from here. The current version works with the RTM version of Microsoft Excel 2007.
Alternative ways
As always in programming, there is more than one method to achieve the same thing.
You could use Office automation to start an instance of Excel 2007 (or any other Office application) and then use interop calls to create a document and save it. However, using automation has some drawbacks I have already written about (see this link).
The next version of the .NET Framework (codename WinFX) will have support for Open Packaging Conventions (package handling and navigating the relationships), but it seems there will be no support for accessing application specific data, so you will still need to process XML parts manually.
As another option, you could use some third party component which will come with support for the Open XML format. This will probably cost you some money, but has the advantage that usually more than one format (for example, XLS, XLSX, CSV) are supported within the same API, so your application will be able to target different file formats using the same code.





