Introduction
.NET! C#! If you haven't been inundated with the marketing of Microsoft's new initiatives, you've been living in your cube without a web connection for quite a while. Like a lot of developers, I had installed the .NET SDK and the Beta 1 of Visual Studio .NET and played with it. However, since its release was so far out in the future and I had deadlines to meet, I soon went back to working with the things my customers needed now.
But the press coverage continued. One evening our Vice President of New Technologies noticed me carrying out a book on COM+ on the way out, and asked something like 'COM+? Why aren't you studying .NET and C#?'
Ok, I knew what management was thinking about, it couldn't hurt to give this thing another look...
Being the masochist that I am, I generally learn a new language or technology by jumping in over my head and figuring it out when I've got motivation, like a looming deadline. Since I'm not likely to see any customers asking for .NET work prior to it's release, I needed to come up with something on my own.
I recently started a project on SourceForge, the HSQL Database Engine which is continuing the development of a Java SQL engine project that had been dropped by the original developer. From what I saw and read, C# was a lot like Java, so why not port it? There would be enough changes required to force me to learn the language and environment.
This is the story of that little adventure.
Porting issues
There are enough differences between Java and C# to give you a bit of a headache when porting anything significant. I believe that Microsoft's Java User Migration Path (JUMP) will be a success at converting 80-90% of Java code, but the rest of it is going to be sticky. Doing it manually was a somewhat painful process.
Syntax differences are minor at best. The compiler thankfully complained about these and stopped, so I spent a little over a day making these changes, without being distracted by the next step.
Then came the majority of the porting effort. If my memory serves me right, the first time there were no syntax problems the complier reported over 3000 library/API errors. Almost all of these were due to differences between the Java API and the .NET API.
Rather than go into all of them, I'll elaborate on a few.
In Java, the StringBuffer class is used for building a string to eliminate the overhead of creating multiple String objects when building a complex string. .NET has an equivalent class, StringBuilder. The methods are almost identical, with the exception of the first character of the methods are uppercase, so StringBuffer.append becomes StringBuilder.Append.
The number of keys in a Java Hashtable class object is accessed through the size() method, where the same information for .NET Hashtable class is available through it's Count property.
These kinds of differences are pervasive throughout the .NET API. Most of the JAVA API objects are represented, but have slight differences that could be resolved by a smart parser that understood both languages. Without something like JUMP, or at least a comparative guide available, I had to do a lot of reading to find the classes I needed.
The bad part: C# and .NET do not support the loading of a class at runtime based on it's name. This forced me to drop support for triggers from the C# version of the database engine, as this was central to their design. Additionally, many of the SQL operators were implemented using this technique in the Java version, so the C# version currently does not support as many SQL options as the Java version. If someone was motivated, they could probably add support for them in the C# version in a couple of days.
Update
Thanks to Rossen Blagoev, who pointed out that it is possible to load a class by name in C#, using the Activator class.
Activator.CreateInstance(Type.GetType("MyClass"));
I'll have to play with it, but I think the Activator and MethodInfo classes will be required to do what I need to, and I think for C# the parser will have to be changed slightly, since it needs to know the Assembly if the class to be loaded is not in the executing assembly.
Here is the Java version of a Result object's constructor
Result(byte b[]) throws SQLException {
ByteArrayInputStream bin = new ByteArrayInputStream(b);
DataInputStream in = new DataInputStream(bin);
try {
iMode = in.readInt();
if (iMode == ERROR) {
throw Trace.getError(in.readUTF());
} else if (iMode == UPDATECOUNT) {
iUpdateCount = in.readInt();
} else if (iMode == DATA) {
int l = in.readInt();
prepareData(l);
iColumnCount = l;
for (int i = 0; i < l; i++) {
iType[i] = in.readInt();
sLabel[i] = in.readUTF();
sTable[i] = in.readUTF();
sName[i] = in.readUTF();
}
while (in.available() != 0) {
add(Column.readData(in, l));
}
}
} catch (IOException e) {
Trace.error(Trace.TRANSFER_CORRUPTED);
}
}
And the C# version
public Result(byte[] b)
{
MemoryStream bin = new MemoryStream(b);
BinaryReader din = new BinaryReader(bin);
try
{
iMode = din.ReadInt32();
if (iMode == ERROR)
{
throw Trace.getError(din.ReadString());
}
else if (iMode == UPDATECOUNT)
{
iUpdateCount = din.ReadInt32();
}
else if (iMode == DATA)
{
int l = din.ReadInt32();
prepareData(l);
iColumnCount = l;
for (int i = 0; i < l; i++)
{
iType[i] = din.ReadInt32();
sLabel[i] = din.ReadString();
sTable[i] = din.ReadString();
sName[i] = din.ReadString();
}
while (din.PeekChar() != -1)
{
add(Column.readData(din, l));
}
}
}
catch (Exception e)
{
Trace.error(Trace.TRANSFER_CORRUPTED);
}
}
As you can see, the two look pretty similar. C# requires a constructor to be declared as public, where as Java simply assumes public visibility, and C# does not use throws. .NET's MemoryStream class is pretty much a direct replacement for ByteArrayInputStream, and BinaryReader is the .NET equivalent to DataInputStream. The ReadXXX methods differ slightly, but the logic and syntax are pretty much identical.
SQL Engine architecture
Each database connection uses a different Channel object. The Channel has a link to a User object and a list of Transaction objects. (a Transaction object is a single row insert or delete in a table)
The result from a database operation is a Result object. (this *may* contain Record objects if the query was a successful select operation)
The query results are a linked list of Record objects, for which the root object is contained in the Result object.
How a statement is processed
The Database creates a Tokenizer that breaks the statement into tokens. If it's a INSERT, UPDATE, DELETE or SELECT, a Parser is created (all other statements are processed by the Database class directly) The Parser creates a Select object if it's a SELECT. This Select contains one or more TableFilter objects (a conditional cursor over a table), Expression objects and possibly another Select (if it's a UNION)
How the data is stored
The Index is an AVL tree. Each Index contains a root Node that is 'null' if the table is empty. Each node may have a parent node and a left and/or right child. Each node is linked to a Row object (the Row contains the data.) The data is contained in an array of objects.
Transaction handling
The Channel keeps track of the uncommitted transactions. Each Transaction object contains a reference to the 'old' data. Statements that may fail (for example UPDATES) start a nested transaction, but more nesting is not built in. Also, since SharpHSQL was not designed as a multi-user database, other Channel's can read the uncommitted transaction objects, i.e. a two-phase commit protocol is not used. A rollback is done by un-doing (re-inserting or deleting) the changes in reverse order. This also means that we have implemented UPDATES as a combination of DELETE and INSERT operations, which is why updates are slower than inserts.
More specific information about the internal architecture of the engine can be found at the HSQL Database Engine project page on SourceForge.
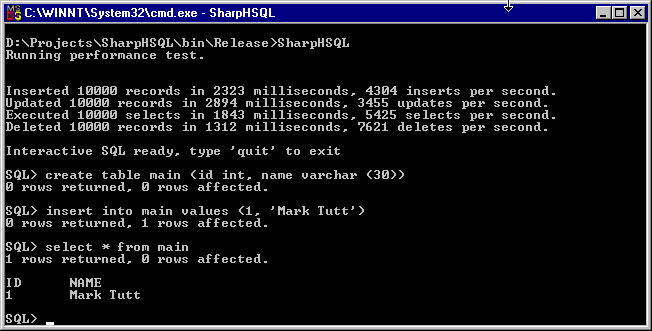
How to use the SharpHSQL classes
The SharpHSQL class in the sample project contains basic examples of executing queries and accessing their results. It implements a simple command line SQL engine that you can type queries into and display the results.
Example
Database db = new Database(".");
Channel myChannel = db.connect("sa","");
All queries return a Result object
Result rs;
string query = "";
while (!query.ToLower().Equals("quit"))
{
Console.Write("SQL> ");
query = Console.ReadLine();
if (!query.ToLower().Equals("quit"))
{
rs = db.execute(query,myChannel);
if (rs.sError != null)
{
Console.WriteLine(rs.sError);
}
else
{
Console.Write(rs.getSize() + " rows returned, " +
rs.iUpdateCount + " rows affected.\n\n");
if (rs.rRoot != null)
{
Record r = rs.rRoot;
int column_count = rs.getColumnCount();
for (int x = 0; x < column_count;x++)
{
Console.Write(rs.sLabel[x]);
Console.Write("\t");
}
Console.Write("\n");
while (r != null)
{
for (int x = 0; x < column_count;x++)
{
Console.Write(r.data[x]);
Console.Write("\t");
}
Console.Write("\n");
r = r.next;
}
Console.Write("\n");
}
}
}
}
I would have liked to develop ADO.NET driver classes for SharpHSQL, but a combination of sparse documentation and lack of time did not permit this. Perhaps in the future, if there is interest...
Performance
Regarding the performance section, my intention is only to demostrate the relative performance of the two versions of the application, and attempt to ascertain where the difference lies by way of comparison. I do not intend for the article to be viewed as a benchmark of .NET, obviously there is much more to .NET than is demonstrated by this application. If it is percieved as such, I apologize, and will remove the performance section if requested.
After having gotten the disk based databases working with the C# version, I decided to spend a little time benchmarking the two. What I found surpised me! My earlier observations were not a valid comparison, as the Java version of the SelfTest application was printing out a running status rather than just the summary totals, as well as doing a few other things that the C# version did not.

The chart above details the timing results from executing the performance test option in the C# version. I wrote an exact replica of the test for the Java version. For disk based databases, C# was slightly faster in all tests. The real surprise was in the in-memory database test. An in-memory database does not log transactions to disk, therefore there is no recovery, however the removal of the disk IO makes for significantly faster access times.
I then profiled both applications, the Java version using TrueTime from NuMega, and the C# version using the beta version of AQtime.NET from AutomatedQA. I won't post the full details here, but will instead briefly discussed the areas that surprised me.
Java version Top 10 Functions| Function Name | Hit Count | % Time |
|---|
Tokenizer.getToken() | 550060 | 12.55 |
Column.compare(java.lang.Object, java.lang.Object, int) | 1437073 | 5.93 |
Index.insert(org.hsqldb.Node) | 40000 | 5.35 |
Parser.read() | 240005 | 4.46 |
Index.compareRow(java.lang.Object[], java.lang.Object[]) | 945900 | 2.7 |
Index.findFirst(java.lang.Object, int) | 30000 | 2.65 |
Node.getData() | 1467073 | 2.46 |
Index.delete(java.lang.Object[], boolean) | 40000 | 2.31 |
Index.search(java.lang.Object[]) | 40000 | 2.17 |
Parser.parseSelect() | 10001 | 1.93 |
For the Java version of the database engine, the largest percentage of time was spent in the Tokenizer.getToken and the Column.compare methods. The Tokenizer did not surprise me, however the Column.compare did. If you look at both versions of the method, you'll see that they are virtually identical. Based on the test parameters, I believe that Java's String.compareTo(String) method is the bottleneck, as the comparison is needed when the engine is building the index on the name column in the test table. It appears that Java's string handling suffers in comparison to that of C#, since several of the top percentage functions in the Java profile are string related.
C# version Top 10 Functions| Function Name | Hit Count | % Time |
|---|
Index.insert(Node) | 40000 | 10.14 |
Node.getData() | 1464842 | 5.19 |
Index.delete(object[], bool) | 40000 | 4.4 |
Index.findFirst(object, int) | 30000 | 4.25 |
Index.search(object[]) | 40000 | 4.15 |
Index.compareRow(object[], object[]) | 943669 | 3.45 |
Parser.read() | 240002 | 3.31 |
Trace.check(bool, int) | 846630 | 3 |
Index.from(Node) | 395765 | 2.73 |
Index.child(Node, bool) | 590043 | 2.11 |
The C# version showed what I expected, the majority of the time being spent in the indexing functions. However, I'm at a loss as to why it was significantly slower than the Java version in the in-memory database test. My assumption is that it is due to some extra debugging information in the pre-release .NET libraries, or possbily a lack of optimizations by the beta version of the C# compiler. There is also the possibility of some profiling differences, since the applications were profiled with two different tools.
Caveats
Since I am not using these classes for anything other than an exercise, no effort has been made to ensure that this is a bulletproof application. In particular, the disk based database functions have seen little testing. I honestly got bogged down trying to implement the ConfigManager class to read and write the equivalents of the Java versions database properties files. I found the classes and the documentation to be quite confusing, and gave up and commented this coded out for now. Consequently, there is work to be done before you can use this option effectively. If I figure out how to implement it, I'll upload a new version.
UPDATE
I implemented the database properties files using XmlTextReader and XmlTextWriter classes, and reworked the remaining classes where required to get disk based databases working. I've uploaded the new files, with modifications to allow for command line selection of the database type. See SharpHSQL.cs for the command line options.
Conclusion
C-Sharp and .NET are an intriguing combination. Overall C# seems to be an excellent design for a new language, offering elegance and simplicity over C++, while avoiding the overhead of Java and learning from Java's hindsight. The idea that you will be able to develop truly high-performance applications with C# and .NET does not seem that far-fetched.
As you would expect of a database engine, this project makes heavy use of some of the C# and .NET data manipulation classes. Reviewing the Java and C# versions of the ported classes should prove helpful to anyone planning on porting a Java application. The process of porting was time consuming, but not overly difficult.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 








