Introduction
Cluster is a widely used term meaning independent computers combined into a unified system through software and networking. At the most fundamental level, when two or more computers are used together to solve a problem, it is considered a cluster. Clusters are typically used for High Availability (HA) for greater reliability or High Performance Computing (HPC) to provide greater computational power than a single computer can provide.
As high-performance computing (HPC) clusters grow in size, they become increasingly complex and time-consuming to manage. Tasks such as deployment, maintenance, and monitoring of these clusters can be effectively managed using an automated cluster computing solution.
Why a Cluster
Cluster parallel processing offers several important advantages:
- Each of the machines in a cluster can be a complete system, usable for a wide range of other computing applications. This leads many people to suggest that cluster parallel computing can simply claim all the "wasted cycles" of workstations sitting idle on people's desks. It is not really so easy to salvage those cycles, and it will probably slow your co-worker's screen saver, but it can be done.
- The current explosion in networked systems means that most of the hardware for building a cluster is being sold in high volume, with correspondingly low "commodity" prices as the result. Further savings come from the fact that only one video card, monitor, and keyboard are needed for each cluster (although you will have to swap these to each machine to perform the initial installation of Linux; once running, a typical Linux PC does not need a "console"). In comparison, SMP* and attached processors are much smaller markets, tending towards somewhat higher price per unit performance.
- Cluster computing can scale to very large systems. While it is currently hard to find a Linux-compatible SMP with many more than four processors, most commonly available network hardware easily builds a cluster with up to 16 machines. With a little work, hundreds or even thousands of machines can be networked. In fact, the entire Internet can be viewed as one truly huge cluster.
- The fact that replacing a "bad machine" within a cluster is trivial compared to fixing a partly faulty SMP yields much higher availability for carefully designed cluster configurations. This becomes important not only for particular applications that cannot tolerate significant service interruptions, but also for general use of systems containing enough processors so that single-machine failures are fairly common. (For example, even though the average time to failure of a PC might be two years, in a cluster with 32 machines, the probability that at least one will fail within 6 months is quite high.)
OK, so clusters are free or cheap and can be very large and highly available... why doesn't everyone use a cluster? Well, there are problems too:
- With a few exceptions, network hardware is not designed for parallel processing. Typically latency is very high and bandwidth relatively low compared to SMP and attached processors. For example, SMP latency is generally no more than a few microseconds, but is commonly hundreds or thousands of microseconds for a cluster. SMP communication bandwidth is often more than 100 MBytes/second, whereas even the fastest ATM network connections are more than five times slower.
- There is very little software support for treating a cluster as a single system.
Thus, the basic story is that clusters offer great potential, but that potential may be very difficult to achieve for most applications. The good news is that there is quite a lot of software support that will help you achieve good performance for programs that are well suited to this environment, and there are also networks designed specifically to widen the range of programs that can achieve good performance.
*SMP: Multiple processors were once the exclusive domain of mainframes and high-end servers. Today, they are common in all kinds of systems, including high-end PCs and workstations. The most common architecture used in these devices is symmetrical multiprocessing (SMP). The term "symmetrical" is both important and misleading. Multiple processors are, by definition, symmetrical if any of them can execute any given function.
Cluster Computing vs. Grid Computing
Cluster Computing Characteristics
- Tightly coupled computers.
- Single system image.
- Centralized job management and scheduling system.
Cluster computing is used for high performance computing and high availability computing.
Grid Computing Characteristics
- Loosely coupled.
- Distributed JM & scheduling.
- No SSI.
Grid computing is the superset of distributive computing. It's both used for high throughput computing as well as high performance computing depending on the underlying installation setup.
Concurrent with this evolution, more capable instrumentation, more powerful processors, and higher fidelity computer models serve to continually increase the data throughput required of these clusters. This trend applies pressure to the storage systems used to support these I/O-hungry applications, and has prompted a wave of new storage solutions based on the same scale-out approach as cluster computing.
Anatomy of Production of High Throughput Computing Applications
Most of these high throughput applications can be classified as one of two processing scenarios: Data Reduction, or Data Generation. In the former, large input datasets-often taken from some scientific instrument-are processed to identify patterns and/or produce aggregated descriptions of the input. This is the most common scenario for seismic processing, as well as similarly structured analysis applications such as micro array data processing, or remote sensing. In the latter scenario, small input datasets (parameters) are used to drive simulations that generate large output datasets-often time sequenced-that can be further analyzed or visualized. Examples here include crash analysis, combustion models, weather prediction, and computer graphics rendering applications used to generate special effects and full-feature animated films.
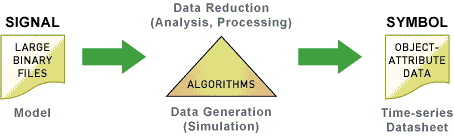
Figure 1
Divide and Conquer
To address these problems, today's cluster computing approaches utilize what is commonly called a scale-out or shared nothing approach to parallel computing. In the scale-out model, applications are developed using a divide-and-conquer approach-the problem is decomposed into hundreds, thousands or even millions of tasks, each of which is executed independently (or nearly independently). The most common decomposition approach exploits a problem's inherent data parallelism-breaking the problem into pieces by identifying the data subsets, or partitions, that comprise the individual tasks, then distributing those tasks and the corresponding data partitions to the compute nodes for processing.
These scale-out approaches typically employ single or dual processor compute nodes in a 1U configuration that facilitates rack-based implementations. Hundreds, or even thousands of these nodes are connected to one another with high-speed, low latency proprietary interconnects such as Myricom's Myrinet®, Infiniband, or commodity Gigabit Ethernet switches. Each compute node may process one or more application data partitions, depending on node configuration and the application's computation, memory, and I/O requirements. These partitioned applications are often developed using the Message Passing Interface (MPI) program development and execution environment.
The scale-out environment allows accomplished programmers to exploit a common set of libraries to control overall program execution and to support the processor-to-processor communication required of distributed high-performance computing applications. Scale-out approaches provide effective solutions for many problems addressed by high-performance computing. These two data-intensive scenarios are depicted in figure 1.
It's All About Data Management
However, scalability and performance come at a cost-namely the additional complexity required to break a problem into pieces (data partitions), exchange or replicate information across the pieces when necessary, then put the partial result sets back together into the final answer. This data parallel approach requires the creation and management of data partitions and replicas that are used by the compute nodes. Management of these partitions and replicas poses a number of operational challenges, especially in large cluster and grid computing environments shared amongst a number of projects or organizations, and in environments where core datasets change regularly. This is typically one of the most time consuming and complex development problems facing organizations adopting cluster computing.
Scalable shared data storage, equally accessible by all nodes in the cluster, is an obvious vehicle to provide the requisite data storage and access services to compute cluster clients. In addition to providing high bandwidth aggregate data access to the cluster nodes, such systems can provide non-volatile storage for computing checkpoints and can serve as a results gateway for making cluster results immediately available to downstream analysis and visualization tools for an emerging approach known as computational steering.
Yet until recently, these storage systems-implemented using traditional SAN and NAS architectures-have only been able to support modest-sized clusters, typically no more than 32 or 64 nodes.
Shared Storage Architectures
Storage Area Networks (SANs) and Network Attached Storage (NAS) are the predominant storage architectures of the day. SANs extend the block-based, direct attached storage model across a high-performance dedicated switching fabric to provide device sharing capabilities and allow for more flexible utilization of storage resources. LUN and volume management software supports the partitioning and allocation of drives and storage arrays across a number of file or application servers (historically, RDBMS systems). SATA-based SAN storage and further commoditization of FC switching and HBAs have fueled recent growth in the SAN market-and more widespread adoption in high performance computing applications.
Network Attached Storage (NAS) systems utilize commodity computing and networking components to provide manageable storage directly to users through their standard client interconnection infrastructure (100Mbit or 1 GB Ethernet) using shared file access protocols (NFS and CIFS). This class of storage includes both NAS appliances and systems constructed from DAS and SAN components that export their file systems over NFS and CIFS. NAS devices deliver large numbers of file "transactions" (ops) to a large client population (hundreds or thousands of users) but can be limited in implementation by what has been characterized as the filer bottleneck. Figure 2 depicts traditional DAS, SAN, and NAS storage architectures.

Figure 2
Each of these traditional approaches has its limitations in high performance computing scenarios. SAN architectures improve on the DAS model by providing a pooled resource model for physical storage that can be allocated and re-allocated to servers as required. But data is not shared between servers and the number of servers is typically limited to 32 or 64. NAS architectures afford file sharing to thousands of clients, but run into performance limitations as the number of clients increases.
While these storage architectures have served the enterprise computing market well over the years, cluster computing represents a new class of storage system interaction-one requiring high concurrency (thousands of compute nodes) and high aggregate I/O. This model pushes the limits of traditional storage systems.
Enter Scale - Out Storage
So, why not just "scale-out" the storage architecture in the same way as the compute cluster-i.e. with multiple file servers that support the large cluster? In fact, many organizations have indeed tried this. However, bringing additional fileservers into the environment greatly complicates storage management. New volumes and mount points are introduced into the application suite and developers are taxed with designing new strategies for balancing both capacity and bandwidth across the multiple servers or NAS heads. Additionally, such an approach typically requires periodic reassessment and rebalancing of the storage resources-often accompanied by system down time. In short, these approaches "don't scale"-particularly from a manageability perspective.
Now, on the horizon, are a number of clustered storage systems capable of supporting multiple petabytes of capacity and tens of gigabytes per second aggregate throughput-all in a single global namespace with dynamic load balancing and data redistribution. These systems extend current SAN and NAS architectures, and are being offered by Panasas (ActiveScale), Cluster File Systems (Lustre), RedHat (Sistina GFS), IBM (GPFS), SGI (CxFS), Network Appliance (SpinServer), Isilon (IQ), Ibrix (Fusion), TerraScale (Terragrid), ADIC (StorNext), Exanet (ExaStore), and PolyServe (Matrix).
These solutions use the same divide-and-conquer approach as scale-out computing architectures-spreading data across the storage cluster, enhancing data and metadata operation throughput by distributing load, and providing a single point of management and single namespace for a large, high performance file system.
Clustered storage systems provide:
- Scalable performance, in both bandwidth and IOPS.
- Uniform shared data access for compute cluster nodes.
- Effective resource utilization, including automatic load and capacity balancing.
- Multi-protocol interoperability to support a range of production needs, including in-place post-processing and visualization.
The commoditization of computing and networking technology has advanced the penetration of cluster computing into mainstream enterprise computing applications. The next wave of technology commoditization-scalable networked storage architectures - promises to accelerate this trend, fueling the development of new applications and approaches that leverage the increased performance, scalability, and manageability afforded by these systems.
Conclusion
With the advent of cluster computing technology and the availability of low cost cluster solutions, more research computing applications are being deployed in a cluster environment rather than on a single shared-memory system. High-performance cluster computing is more than just having a large number of computers connected with high-bandwidth low-latency interconnects. To achieve the intended speed-up and performance, the application itself has to be well parallelized for the distributed-memory environment.
Points of Interest
My final year thesis project is on the "Development of Grid Resource Allocation and Management (GRAM) for High Performance Computing" which is totally related to Grid Computing. Before writing this article I studied Grid Computing and Cluster Computing in depth and understood the differences between them. After studying, I planned to write an article on "What is cluster computing, what are its benefits, limitations and scope. And how does Cluster Computing differentiate with Grid Computing".
Lubna Luxmi Chowdhry,.
Final Year Student,
Computer System Engineering,
Mehran Univ. Of Engineering & Technology,
Jamshoro,
Hyderabad.
Pakistan.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





