Introduction
This library has its origin in some study project I am currently
working on. All source code is covered by the LGPL - this means
you can freely use the code in any project (commercial or non-commercial).
How it works
The tokenizer uses a hierarchical map structure to store the tokens, and should be as fast as the paragon
lexx (at
least n*O(lexx) :-). The analyzer does not have the restriction of being a LALR(1) analyzer (if used correctly), has some
caching capabilities and allows resolution of literal tokens. It also supports a precedence prioritized rule set.
All projects make heavy use of the STL. Because the STL implementation shipped
with MSVC6 is not the best option, you should download the STL Port 4.5.1 implementation
freely available at www.stlport.org. I have now managed
to get rid most of the C4786 warnings (hint: switch /FI).
How to setup the analyzer/tokenizer
A typical rule definition for a simple expression evaluator looks like this:
std::tstringstream init(
"[seperators]\n"
"200:+\n" "201:-\n"
"202:*\n" "203:/\n"
"204:^\n" "205:;\n"
"206:(\n" "207:)\n"
"' Whitespace tokens:\n"
"0: \n" "0:\t\n"
"0:\\n\n" "0:\\r\n"
"[rules]\n"
"300:numbers\n"
"[grammar]\n"
"401:{.expr}=100:{.expr}{$+}{.expr}\n"
"402:{.expr}=100:{.expr}{$-}{.expr}\n"
"403:{.expr}=99:{.expr}{$*}{.expr}\n"
"404:{.expr}=99:{.expr}{$/}{.expr}\n"
"405:{.expr}=98:{.expr}{$^}{.expr}\n"
"406:{.expr}=0:{$(}{.expr}{$)}\n"
"400:{.expr}=0:{!number}\n"
"500:{.line}=0:{.expr}{$;}\n");
This initializes the tokenizer to recognize the separators '+', '-', '*', '/', '^', ';', '(', ')' and
to skip the usual white space characters, and initializes the analyzer to recognize
the math rules '+,*,-,/,^' and declares that '*' has a higher priority than '+', for example.
The interface class
Usually you have to deal only with one class, cxtPackage. This class
exports all methods needed to access the library. Some of them are:
vSetInputStream() - sets the input stream :)vSetDelimeterIDs() - can be used to set the end-of-statement tokens, in C++ this could be ';'nReadUntilDelimeter() - parses the input stream until the next delimiting token is found or the
end of the input stream is reachedpapbCheckForRule() - analyzes the token stream for a given rule and returns a parse tree (if successful)vRebalance() - rearranges the parse tree according to the precedence priority rules
Those are the most important ones. For more details please see the sample project or
check the page http://www.subground.cc/devel
which will have some minimal documentation on the classes available for download soon.
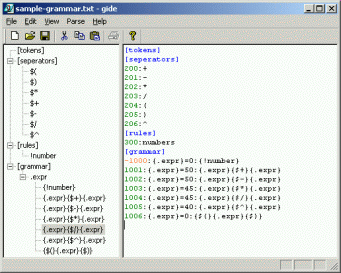
New: The grammar IDE
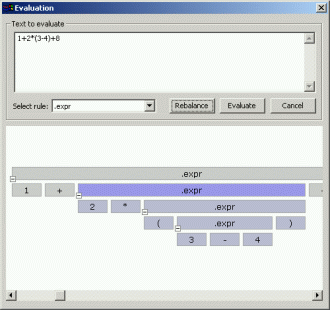
The new grammar IDE included in the complete download provides a environment to develop and test analyzer
rulesets. It has some syntax-highlighting features, shows errors by marking the lines in the editor and has an
integrated test environment to live-check the results of the ruleset. I have no documentation yet and the IDE is
still early beta and it has some cosmetic bugs (for example, it is possible to insert via clipboard RTF-formatted
text into the editor :-), but most of it is already usable.
The sample projects
There are two sample projects included in the complete download. One is an almost-empty sample application
you can easily use to explore the library, and the other project, simpleCalc, shows how to use the library
to build a simple expression evaluator in 200 lines. A step-by-step explanation
on how the sample works is here.
How to use it in own projects
Make sure to insert the projects cxTokenizer, cxAnalyzer and
cxtPackage in the workspace of your project. Adjust the dependencies of
your project to depend on cxtPackage (which itself depends on cxAnalyzer,
which in turn depends on cxTokenizer).
If your project doesn't use the MFC, you have to include the file common.cpp
which is located in the base directory of the project files in your project.
If you have problems or questions, feel free to mail them to alexander-berthold@web.de.
For the most recent updates, see also http://www.subground.cc/devel
Updates
- 2002-01-02
C++ (w/o templates and pre-processor) grammar is now included. See also here. - 2001-12-29
Fixed small bug in analyzer. IDE download now includes a not yet complete C grammar. - 2001-12-27
Updated Homepage-URL to ad-free host. - 2001-12-26
Uploaded new release including the grammarIDE and some enhancements in the analyzer.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 










 ?
?