Introduction
In Part One of this series, we threw out about 90% of ADO.NET because, as object-oriented programmers, we didn’t need it. For us, ADO.NET is a thin data transport layer, rather than a full-service data management solution. The article showed how to perform basic CRUD operations using ADO.NET to get information to and from a business model.
I deliberately kept the code in Part One as simple as possible, so the reader could focus on how ADO.NET is used. But that code was hardly object-oriented. Or, more precisely, it had very little architecture about it. In this article, we will revisit the ADO.NET CRUD operations. Only this time, we will use an application with far better architecture.
Once that is done, we will move on to data binding with objects. In some circles, the .NET framework has gotten a bum rap as “good for database front-ends, but not much else”, because so much of it is built around data-driven programming. Datasets are easy, so it is said, and objects are hard. While that may have been true under .NET 1.x, it’s not true any more.
Visual Studio 2005 includes new ‘Data Source’ functionality that allows objects to be data bound as easily as data sets. The feature works on just about any object or collection, but it works particularly well on objects and collections that implement certain key interfaces.
The demo app attached to this article includes base classes that implement those interfaces. If you derive your data binding objects and collections from these classes, you will get not only basic data binding, but data bound sorting and searching, as well.
The Demo Program
A demo program is attached to this article. The program uses a SQL Server database, which is included in the ‘Database Files’ folder. Attach these files to SQL Server 2005 or SQL Express 2005, using SQL Server Management Studio (or Management Studio Express, which can be downloaded for free from MSDN).
A word about the code: To keep things simple, the demo app doesn’t do several things that one should always do in production code. For example, it doesn’t wrap database calls in try-catch blocks, and it doesn’t escape the single-quotes in the inline SQL queries that it creates. Obviously, the developer should do all these things, and others, in code intended for production.
The demo program maintains a simple list of authors and the books they have written. Its main window shows a master-detail list of authors and books, on two grids:
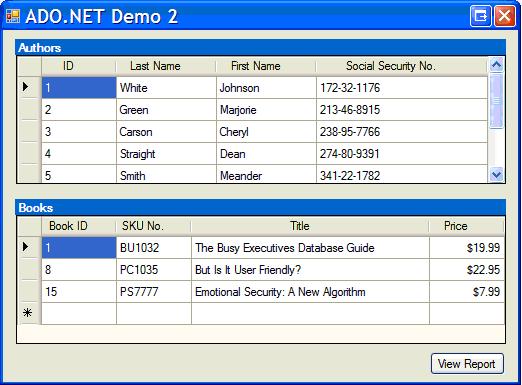
Items may be added or changed using normal data-grid editing operations. Items may be deleted by selecting one on a grid, right-clicking it, and choosing ‘Delete’ from the context menu.
Master-detail views are probably the most frequently used views for reviewing and updating objects in a containment hierarchy. Coding a master-detail view is tedious and time consuming, and prone to errors. Until Visual Studio 2005, there was no easy way to use design-time data binding to ease this chore.
Now, with object data binding, you can set up a complete master-detail view, like the one above, in about ten minutes. You can create reports almost as quickly. The ‘View Report’ button in the lower right corner opens a Report window that shows the master-detail report with the same information. We’ll take a look at that window later.
Architecture – The Pieces of the Puzzle
The sample application is built around the Model-View-Controller (MVC) design pattern, with a data access layer based on the Data Access Objects (DAO) pattern. The overall approach is similar to what Dr. Joe Hummel has been teaching in his current MSDN webcast series. [Hummel]
The goal of the MVC design pattern is to isolate an application’s business model from its user interface. UIs are notoriously unstable, and they have a nasty habit of interfering with business models. Dependencies get tangled up, so that when we change the UI, it breaks our model.
MVC starts with the assumption that the business model is the most stable part of an application. For those who maybe new to OOP, a business model is expected to be the most stable part of an application’s code. The model is probably the first part of our application to be rendered in code. And once it’s done, we need to protect it from changes in other parts of the application. The only reason to change the business model should be to more accurately reflect the underlying business process. In other words, we should never need to ‘reopen’ our business model because of changes to the user interface.
MVC isolates the model from the user interface by placing a ‘controller’ between the UI and the business model. All requests from the UI to the model are filtered through the controller. And in some versions of MVC, all responses from the business model go through the controller, as well. Other versions allow the UI to respond directly to events fired by the business model. We’ll be using the latter version in the demo app.
Another source of application instability is the database back-end. An application may use SQL Server today, but Oracle next year. We may use inline SQL queries to develop the application, but change to stored procedures when the app goes into production. Any of these changes will break the business model if data access is encapsulated in our business objects.
Object-oriented designers often encapsulate data access operations in business objects on the grounds that objects should be self-sufficient—an object should know how to load and save its data. But the ‘Single Responsibility Principle’ states that “A class should have only one reason to change.” [Martin] If we encapsulate data access in our business objects, they have two reasons to change:
- A change in the business model; or
- A change in data access methods.
In order to respect the Single Responsibility Principle, we need to break encapsulation.
The DAO pattern is widely used in the Java world to address these issues. The pattern looks something like this:

The business object delegates its data access operations to a companion data access object, which delegates its CRUD operations to a data provider object. The data access object encapsulates the higher level database calls, such as SQL queries or stored procedure calls, while the data provider object performs the actual database operations. The data provider object is built on a .NET data provider and is tightly coupled to it.
The data provider object contains most of the ADO.NET code that we use. For example, in a ‘get’ operation, the data provider will create and populate a data set, which it will return to the DAO object. The DAO’s job is to transfer the data from the data set to its companion business object.
The MVC and DAO patterns do a good job of isolating a business model from instability in the presentation and data tiers of an application. But MVC has some limitations of its own. Since most communications between application tiers are routed through the Controller, it has the potential to become a bottleneck. To avoid this problem, most MVC designs create a separate controller for each form in the UI. However, if multiple forms need to make the same request of the business model, the code to dispatch that request will need to be added to both controllers. That sort of code duplication is what some writers call a ‘code smell’, as in “that code smells pretty bad” [Beck and Fowler].
The Command pattern, one of the original ‘Gang of Four’ patterns, addresses these issues. Each request the UI can make is encapsulated in a separate Command object. These objects are processed by the Controller—which is reduced to a lightweight command processor that can handle the entire application.
Likewise, each Command object is a very simple and lightweight object. And if two different forms need to pass the same request, they simply instantiate the Command for that message and pass the command to the Controller. This approach eliminates code duplication—if we have to change the command, we have only one place to go. Our code smells much better.
In addition to cleaning up a design, the Command pattern makes it very easy to implement unlimited Undo. We won’t implement this feature in the demo app, but if you would like to see how it works, you will find my article on the subject here.
Architecture—Putting It All Together
As I mentioned above, the demo app manages an Authors list. The list is a two-level containment hierarchy, similar to the Projects list we looked at in Part One. An Authors collection sits at the top of the hierarchy, and each Author in the collection has a Books collection.
Let’s take a look at how all this stuff works in code. Processing a request from the UI resembles a journey through our application’s architecture, more than the simple execution of an algorithm. We start in FormMain, our app’s UI. A quick examination of the code reveals nothing but event handlers, and each is just a couple of lines long. That’s in keeping with the UI’s role in a .NET app: to manage the display, and dispatch user input to the Controller. The UI should never do any processing itself.
Set a breakpoint at the top of the FormMain_Load() handler in FormMain, and start the application in Debug mode. Step into each call in the handler to follow the “Load author list” request across the various objects that participate in filling the request. Note that each object only handles the part of the request that is appropriate to the layer of the application to which it belongs.
The form-load handler starts the process of loading the list by creating a command object to perform the request and passing that object to the Controller:
CommandGetAuthors getAuthors = new CommandGetAuthors();
m_Authors = (AuthorList)m_AppController.ExecuteCommand(getAuthors);
The Controller invokes the command object’s Execute() method, which contains the code to perform the command:
public override object Execute()
{
AuthorList authors = new AuthorList();
return authors;
}
The command object instantiates a new AuthorList object, which passes control to the object’s constructor. Note that we have moved from the presentation tier into the business model. The AuthorList constructor instantiates a companion DAO object, passes a reference to itself to that object, and instructs the DAO object to load the author list from the application database:
public AuthorList()
{
AuthorListDAO dao = new AuthorListDAO();
dao.LoadAuthorList(this);
}
The AuthorList object passes control to its companion DAO object, which takes us from the business tier into the data access tier of the application, where we finally find some code we can sink our teeth into:
public void LoadAuthorList(AuthorList authorList)
{
StringBuilder sqlQuery = new StringBuilder();
sqlQuery.Append("Select AuthorID, LastName," +
" FirstName, SSNumber From Authors; ");
sqlQuery.Append("Select BookID, SkuNumber," +
" AuthorID, Title, Price From Books");
DataSet dataSet =
DataProvider.GetDataSet(sqlQuery.ToString());
DataTable authorsTable = dataSet.Tables[0];
DataTable booksTable = dataSet.Tables[1];
DataColumn parentColumn = authorsTable.Columns["AuthorID"];
DataColumn childColumn = booksTable.Columns["AuthorID"];
DataRelation authorsToBooks = new
DataRelation("AuthorsToBooks", parentColumn, childColumn);
dataSet.Relations.Add(authorsToBooks);
AuthorItem nextAuthor = null;
BookItem nextBook = null;
foreach (DataRow parentRow in authorsTable.Rows)
{
bool dontCreateDatabaseRecord = false;
nextAuthor = new AuthorItem(dontCreateDatabaseRecord);
nextAuthor.ID = Convert.ToInt32(parentRow["AuthorID"]);
nextAuthor.FirstName = parentRow["FirstName"].ToString();
nextAuthor.LastName = parentRow["LastName"].ToString();
nextAuthor.LastName = parentRow["LastName"].ToString();
nextAuthor.SSNumber = parentRow["SSNumber"].ToString();
DataRow[] childRows = parentRow.GetChildRows(authorsToBooks);
foreach (DataRow childRow in childRows)
{
nextBook = new BookItem();
nextBook.ID = Convert.ToInt32(childRow["BookID"]);
nextBook.SkuNumber = childRow["SkuNumber"].ToString();
nextBook.Title = childRow["Title"].ToString();
nextBook.Price = Convert.ToDecimal(childRow["Price"]);
nextAuthor.Books.Add(nextBook);
}
authorList.Add(nextAuthor);
}
dataSet.Dispose();
}
The code should be pretty self-explanatory, if you read the Part One of this series. The LoadAuthorList() method iterates the records in the Authors table of the database and creates an author record for each author it finds. As it does so, it creates a BookItem for each book written by the author and adds it to the AuthorItem’s Books collection property.
Note that the DAO object directly sets the properties of the AuthorList object that instantiated and called it. So, the DAO object needs to know the structure of its companion; it is tightly coupled to its business object. But the business object is more loosely coupled to its DAO object. If something changed about the data access procedure, I can change it without reopening the business object. By breaking encapsulation to delegate data access, we have isolated the business model from changes in the data access model.
Now, even though the DAO object is a pretty hefty chunk of code, you may have noticed that it never created a data set or a data adapter. It simply passed an SQL query to a DataProvider object, which returned a data set to the DAO object. In other words, the DAO object delegated the actual data access operations to a DataProvider class, which is built on top of a .NET native data provider. That approach centralizes our data access code and eliminates duplication. Our code smells better for it.
Delegating to a DataProvider object also isolates our DAO objects from low-level changes to our database. If we change our database from SQL Server to Oracle, we don’t have to reopen our business objects. And since we are using rather generic inline SQL queries in our DAO objects, we may be able to get away without having to reopen our DAO objects, either. With any luck at all, we will be able to make the change simply by modifying three methods in the DataProvider class. Hey, even I can get that done in an hour or so!
Joe Hummel argues that this benefit provides a strong justification for using inline queries instead of stored procedures. I think he may have a point. Joe does caution that inline queries need to be properly escaped to protect against SQL injection attacks, and he acknowledges that stored procedures do have a performance advantage over inline queries. For more information, see session 6 of his current webcast series.
The two-level data access approach, using inline queries or stored procedures, is particularly useful for frameworks that you might use in projects for different clients. Consider a client with three install sites: Site A uses SQL Server, Site B uses Oracle, and the database administrator at Site C says I will add stored procedures to the site’s SQL Server over his or her dead body. I can use stored procedures with SQL Server and Oracle data provider objects for the first two sites, and inline queries with a SQL Server data provider for Site C. And I don’t have to touch the business model or the UI to get any of this done.
We won’t reproduce the DataProvider code here, since its code is more or less the same as the code in Part One of this series. Suffice it to say that the DAO object uses the data set returned by the DataProvider to populate its companion business object. Then it returns control to the business object, which returns control to the command object, which returns control to the UI. In other words, we drill down through our application layers, then be bubble back up to the UI.
The creation, updating, and deletion operations work the same way—we create a command object, pass it to the Controller, and the Controller processes the command. In most cases, the command makes a request of a business object, which delegates the request to a DAO object.
In the demo app, CRUD operations are triggered by events that originate in the DataGridView controls on the main form. We will discuss these events, and how to data-bind business objects to them, under ‘Data Binding’ below.
Architecture—What’s the Point?
That’s a lot of objects to go through just to get an Authors list. Wouldn’t it be a lot simpler to just pass the data set? In a simple case like the demo app, of course, it would. Object-oriented design imposes a certain amount of overhead, which should be considered before designing a project. OOP is probably overkill in very simple applications.
But consider a client company that uses a General Ledger with three or four levels of subledgers extending from a number of different accounts. Those of you who write financial and accounting applications know that’s not an unusual case. I wouldn’t want to try to keep that business process straight using data sets. As my wife said in Part One, “They’re fine when they work, but you can’t build a Swiss watch with them.”
When something changes in my project, the changes should be localized to one layer. That means changes to one layer won’t affect any other layer. I could move this application to the web, and I wouldn’t have to do much, if anything, to the business or data layers. Likewise, I could change databases, and I wouldn’t have to do much, if anything to the UI and business layers. And the business layer is isolated from all changes except those involving the business model. Of course, if the business model changes significantly, all bets are off. But that’s the layer least likely to change.
Databinding in the UI Layer
And so, at long last, we get the Authors list back to the UI. What do we do with it then? In the old days of .NET 1.x, a lot of us used to dump the list back into a data set, which we would bind to a grid for display and update. That’s just crazy. Or, we would use a third-party grid with a decent unbound mode, and we would hand-wire that to the list. That’s painful, at best.
Visual Studio 2005 provides a new ‘Data Source’ functionality to .NET. It’s not a control—a BindingSource control is used to do the actual data binding. And it’s not a class, either. It’s an XML interface (a file with a .datasource extension) that lets .NET treat a business object like an ADO.NET row object, and a business collection like an ADO.NET data table. In other words, business objects and collections become first class citizens in the .NET data binding world.
What that means is that, for the most part, we can forget about writing data binding code. We don’t need it. About 90% of the work involved in displaying a business model can now be done at design time. And that means that instead of grinding out code, we get to mess about in a Designer. I don’t know about you, but I know which I’d rather do.
Since the work is done in design mode, let’s walk through the steps involved, rather than reprinting code. First, lay out your form. For the demo app, we need a master-detail display, so we use two DataGridView controls on a form.
Next, create data sources for your business objects. I used ‘Add New Data Source’ from the Data menu, although you can do the same thing from the Data Sources dockable window. Select ‘Show Data Sources’ from the Data menu to open it. I created data sources for the AuthorList and BookList objects.
Next, bind the business objects to the DataGridView controls. I dragged the AuthorList data source object onto the Authors grid, and the BookList data source object onto the Books grid. As each object is dropped on its grid, the appropriate columns appear on the grid. Note that as you dropped each data source object, Visual Studio added a BindingSource component to the form. The binding source will act as an intermediary for data binding. The grid is bound to the binding source, and the binding source is bound to the data source.
Next, configure each grid. Select ‘Edit Columns’ from either the context menu or the Smart Panel for a DataGridView control, and the ‘Edit Columns’ box will appear. You can use the box to set column widths, header text, and so on.
I would definitely suggest changing the Name property for each column of every DataGridView on the form. If you have two grids on a form, as you might in master-detail forms, and if your objects have common property names (both the AuthorItem and BookItem objects have an ‘ID’ property), the Designer has been known to assign the same name to the columns of both DataGridView controls. If that happens, your form will crash the next time you open it, and you will have to start over again.
Once you have finished formatting your grids, it’s time to write a couple of lines of code. The design-time binding we did earlier bound the grid to our object structure, but not its data. In database terms, all we did was bind the objects’ schemas. So, now we need to bind for run time:
bindingSourceAuthors.DataSource = m_Authors;
bindingSourceBooks.DataSource = bindingSourceAuthors;
bindingSourceBooks.DataMember = "Books";
These lines appear at the end of the FormMain_Load() event handler. The first line binds the Authors binding source to the Authors list we loaded earlier. The second line binds the Books binding source to the Authors binding source. This is an important move—it synchronizes the Books grid to the currently selected author. Since the Books grid will display an AuthorItem’s Books property, the third line sets the DataMember property for the Books binding source to the current AuthorItem’s Books property.
And that’s all there is to it—three lines of code. The grids in the demo app support data binding adds, changes, and deletes just as they would if they were bound to a data set. We get all of the gain with none of the pain.
Data Binding and BindingList<T>
One of the cool things about the DataSource capabilities of Visual Studio 2005 is that they don’t require special collections or objects to work. Pretty much any collection will do. In the old days of .NET 1.x, a collection was fully bindable only if it implemented the IBindingList interface. Having tried to implement that interface once, I wouldn’t try again, even at gunpoint. Shoot me; it’s less painful.
Even though you can use just about any collection as a DataSource, there are still advantages to implementing IBindableList. Fortunately, Microsoft has made that simple with a new generic collection class, BindingList<T>. It’s similar to the generic class List<T>, but it implements the IBindingList interface, so you don’t have to. Simply derive your class from BindingList<T>, and you’re good to go.
I’m not going to spend a lot of time on BindingList<T>, because there is a great series of articles about it on MSDN:
The demo app includes two abstract classes, FSBindingList and FSBindingItem, that serve as base classes for most of my collections. FSBindingList is derived from BindingList<T>, and it implements sorting and searching capabilities you don’t get from BindingList<T>. So, simply derive your collection from FSBindingList, and your bound DataGridView control will support sorting and searching on the grid. Details are in the MSDN articles cited above.
The FSBindingItem class implements the IEditableObject interface. This interface supports ‘row-commit’ editing in a DataGridView. When bound to a data set, the DataGridView allows a user to cancel any changes to the current row by hitting the escape key. This is a behavior that many users are accustomed to and have come to expect, but an object must implement IEditableObject to support the feature. FSBindingItem implements the interface, so simply derive your business object from that class, and you gain row-commit editing in DataGridView controls.
By the way, any UI control that supports data binding also supports data source binding. That means business object properties can be bound to text boxes, labels, and other controls. And one final note about DataGridView controls: you may find that, after binding your object to a DataGridView at design time, the control doesn’t display a blank row for adding new data. That means it won’t let the user add new rows at run time, even if you have instructed it to do so in its Smart Panel. In most cases, this is because the BindingSource component to which the grid is bound has its AllowNew property set to false. Reset it to true at design time, and the blank ‘Add New’ row will reappear.
Data Binding Reports
Visual Studio 2005 contains a new ReportViewer control and a Report Designer to create reports for the viewer. Objects and collections can be data bound to ReportViewer reports, just as they can be bound to DataGridViews and other controls. The setup is a little more complicated than for a DataGridView, but not much.
The demo app contains a master-detail report showing each author on a separate page, along with the books written by that author. You can see the report by clicking the ‘View Report’ button on the main form:
Here is how to build a master-detail report like the one in the demo app: start by creating the report. A report is added to a project just like any other item. Right-click the project name in the Solution Explorer and select Add > New from the context menu. The ‘Add New Item’ box will appear; select ‘Report’ and give your report a name. The demo app’s report is named ‘AuthorsReport.rdlc’.
Once the blank report is open, drag items onto it from the toolbox. For starters, we will need some sort of repeating container to hold author information. Since we want a free-form page with one author per page, rather than a grid, we will use the List control from the Report Items section of the Toolbox. We drag it onto the report, drop it, and resize it to fit the page. Now we need to populate the list.
There are no label controls; labels are added using text box controls, which you type directly into. Object fields can be dragged directly from the Data Source window onto the list. For the master report, I dragged out some labels and fields. Then I dragged out a ‘Subreport’ control and dropped it on the list. I gave it the size you see on the form, then saved and closed it.
To show the apps, we need to create a subreport—we can’t use simple grouping. The first step in creating a subreport is to put a placeholder in the main report. Drag a Subreport control from the toolbox onto the report. It will appear as a gray box. Resize the box to the size of the subreport you plan to insert. In the demo app, we plan to insert a table with the same width as the report, so we resize the Subreport control to the width of the report.
Next, create the actual subreport. It is simply another report file, and it is set up using the same techniques as for the main report. Our demo app subreport is named ‘BooksSubreport.rdlc’, and we have set it up using a Table control from the Toolbox, since we want to show multiple books on one page. We set up table columns by dragging fields from the data source window to the data row of the Table control on the subreport. Finally, we resize the Table control to the same width as the main report, and resize the report so that it just contains the table.
Next, set up the communications from the main report to the subreport. Visual Studio 2005 doesn’t have the ability to pass fields directly from a report to a subreport, so we are going to have to provide a little plumbing to do that. To start, add a parameter to the subreport. The parameter will generally be the ID property of the current object in the main report.
To add the parameter, make sure the subreport is visible in the Designer. Select ‘Report Parameters’ from the Report menu, and the ‘Report Parameters’ box will appear. Add a parameter for the ID to the list on the left of the box. I added a parameter called ‘AuthorID’ to the subreport in the demo app. Once that is done, save and close the subreport.
Now connect the main report to the subreport. To do that, reopen the main report. Right-click on the gray subreport block and select ‘Properties’ from the context menu. On the General tab, select the subreport file in the ‘Subreport’ drop-down. The two reports are now connected.
Next, switch to the Parameters tab. We are going to link the parameter we created in the subreport to a field in the current record of the main report. Enter the name of our subreport parameter (AuthorID) in the ‘Parameter Name’ column. In the ‘Parameter Value’ column, select ‘Fields!Id.Value’ from the drop-down. The main report will now pass the current author’s ID to the subreport using the subreport’s AuthorID parameter. Save and close the main report.
We’re just about done. The next step is to create a viewer for the report. Each report is bound to a separate report viewer control. For the demo app, I simply added a ReportViewer control to the report form and docked the control to fill the form. The easiest way to bind the control to a report is by using the control’s smart panel. Select the report from the panel’s ‘Choose Report’ drop-down, and the control is bound to the report. Note that the ReportViewer created a BindingSource control to facilitate the binding. And note also that the ReportViewer doesn’t display anything other than its navigation controls at design time, even after it has been bound.
As with the DataGridView control, our design-time binding only bound the report to the structure of our Authors list, not to its data. We will need to bind the reports in code to achieve run-time binding. That task is carried out by the FormReport_Load() event handler:
private void FormReport_Load(object sender, EventArgs e)
{
CommandGetAuthors getAuthors = new CommandGetAuthors();
m_Authors = (AuthorList)m_AppController.ExecuteCommand(getAuthors);
reportViewer1.LocalReport.SubreportProcessing += new
SubreportProcessingEventHandler(LocalReport_SubreportProcessing);
bindingSourceAuthors.DataSource = m_Authors;
this.reportViewer1.RefreshReport();
}
Note that the handler gets the Authors list using the same Command class that the main form used. If we were using traditional MVC, with separate controllers for the two forms, there would be code duplication, and one can see where our code could start getting tangled up. As it is, we create a CommandGetAuthors object and pass it to the Controller.
Note also that we must subscribe to the ReportViewer’s SubreportProcessing event. We will use this event to intercept the ID as it is passed from the main report to the subreport. Using that ID, we will get the AuthorList object currently being processed by the main report. Then we will pass that object's Books collection to the subreport as its data source.
The SubreportProcessing event is very odd—it’s the only one I’ve ever seen that has a parent (the actual event name is ‘LocalReport.SubreportProcessing’). And it’s the only one for which you can’t create an event handler by double-clicking the event in the Windows Form Designer’s Properties window. That’s the reason, as much as anything else, why we add the code to the form-load event handler.
After subscribing to the SubreportProcessing event, bind the runtime list to the binding source control for the main report. Note that we only bind the main report, and we bind it to the list at the top of our hierarchy. We don’t bind the subreport directly. Instead, we set its data source as each object is processed in the main report.
That work gets done in the LocalReport_SubreportProcessing event handler. Here is what the code looks like:
private void LocalReport_SubreportProcessing(object sender,
SubreportProcessingEventArgs e)
{
int authorID = Int32.Parse(e.Parameters["AuthorID"].Values[0]);
AuthorItem currentAuthor = m_Authors.GetAuthor(authorID);
ReportDataSource dataSourceAuthorsBooks = new
ReportDataSource("ObjectDataBinding_Model_BookList",
currentAuthor.Books);
e.DataSources.Add(dataSourceAuthorsBooks);
}
The SubreportProcessing event is fired each time the ReportViewer reaches the subreport block while processing a page in the main report. It passes the subreport any parameters specified at design time, using its EventArgs to do so. We intercept these parameters in the event handler by reading the Parameters property of the EventArgs. In the demo app, we intercept the AuthorID parameter.
Next, we use the ID to get the AuthorItem object that corresponds to the author currently being processed by the main report. Finally, we create a new ReportDataSource object for the subreport and use it to pass the AuthorItem.Books property. The subreport uses the Books collection to fill its table.
Note that the name we pass to the ReportDataSource constructor must be the same as the name of the data source given to the subreport at design time. Why? Because, we are replacing that design-time data source with our run-time data source. To find the design-time name, open the subreport in the Report Designer and select ‘Data Sources’ from the Report menu. The design-time data source should be the only item in the ‘Report data sources’ list.
All-in-all, it’s a bit of a fire drill, and it’s not Microsoft’s most elegant piece of work. But after you have set up a couple of master-detail reports, it’s no big deal. After all, we’re only talking about four lines of code! And the results are certainly worth it.
Conclusion
That wraps up our tour of ADO.NET for object-oriented programmers. Over the course of this article, we have seen:
- A simple and flexible application architecture based on the MVC, DAO, and Command patterns. With serialization, this architecture can be extended to work in a variety of distributed computing environments.
- How to data-bind objects as easily as data sets in Visual Studio 2005, and how to create master-detail views for both updating and reporting.
- Base collection classes that provide support for extended data binding features such as sorting and searching.
You are welcome to use the FSBindingList and FSBindingObject classes in your own applications, so long as you credit the sources of the classes (me and the MSDN articles cited above). With the time that we save not having to write UI plumbing code, maybe we can all get in a little more time with our families. My wife said she would enjoy that.
References
- Code Smells: The term is attributed to Kent Beck and Martin Fowler, and is explained in Chapter 3 of Fowler’s book: Refactoring—Improving the Design of Existing Code (Addison-Wesley 2000).
- The Gang of Four: Four authors who wrote the seminal book on software design patterns. Gamma et al., Design Patterns—Elements of Reusable Object-Oriented Software (Addison Wesley 1995). The book is often referred to as the ‘GoF book’.
- Hummel Webcast Series: Dr. Joe Hummel, of Lake Forest College, is in the midst of presenting a really great series of webcasts on application architecture for MSDN. The webcasts are archived for viewing on demand and may be accessed here.
- The Single Responsibility Principle: Martin, Robert C., Agile Software Development (Prentice-Hall 2003), p. 95.
- Tootsie-Roll Pop: For the benefit of those who live outside the US, a Tootsie-Roll pop is a round piece of chewy chocolate, surrounded by a hard candy shell about five centimeters thick. American kids argue about whether it’s best to suck on the hard candy until it dissolves, or crunch down on it to get to the chocolate. It reminds me of the debate over Java vs. C#.
David Veeneman is a financial planner and software developer. He is the author of "The Fortune in Your Future" (McGraw-Hill 1998). His company, Foresight Systems, develops planning and financial software.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






 )?
)?
![Rose | [Rose]](https://www.codeproject.com/script/Forums/Images/rose.gif)
