Introduction
Most articles in this section are about improving thread synchronization techniques on synchronization objects, or improving thread management. When trying to solve an automation problem which involves multiple shared objects and sequenced actions, you might find that these techniques do not give you much help on architecting such systems.
In this article, a simple concurrent system is described, and a pipelined concurrent solution is implemented based a concurrent software design platform. The design has the following advantages:
- The software architecture clearly describes pipelined tasks, which allows easy kernel concurrency modification by simply adjusting the synchronization resource assignment strategy among tasks.
- The desired system pipeline concurrency is achieved by using the software design platform SDK, without using any (almost no) Operating System synchronization objects or threads. The simple solution makes it possible, for those who have not much interests or time on writing multithreaded automation software, to quickly implement a concurrent application framework, and focus on other important issues in a system.
Problem Description
An automatic cocktail machine is designed to make cocktails automatically by simply pushing menu buttons on the front panel of the machine.
The goal is to design an application to maximize system concurrency when multiple requests are made by customers at same time. Use the GUI to simulate the machine’s front panel so that customers can push the menu to order cocktails and to pick up the finished drinks.
Four kinds of cocktail recipes can be processed by the machine:
- Mai Tai.
- Scorpion Bowl.
- Zombie.
- Straight Martini.
The machine consists of five major hardware components, which are shown below.
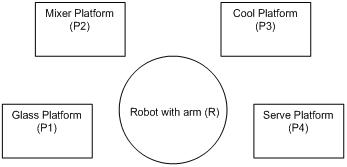
Figure 1
- Component R. It is a robot with an arm, which grabs glasses between P1, P2, P3, and P4.
- Component P1. It holds glasses of different kinds of cocktails. Different recipes might require different glasses.
- Component P2. It mixes cocktails according to a recipe, and then pours the mixed drink into a glass.
- Component P3. It cools the cocktail in a glass.
- Component P4. It presents one finished drink to the customer. After the drink is picked up, a sensor will detect the action.
Basically, the process of making a drink is to use R to move a cocktail glass from P1 to P4, and start component Pi at the proper time according to the recipe requirements.
The detailed operation sequences for Mai Tai, Scorpion bowl, and Zombie are as follows:
- When a cocktail is requested by pushing a button on the front panel of the machine, R picks a glass from P1 and moves it to P2.
- R moves from P2 to neutral position, so that it can move to any of P1, P2, and P3 again faster.
- P2 mixes the cocktail and pours it into the glass.
- R moves the glass from P2 to P3.
- R moves from P3 to neutral position, so that it can move to any of P1, P2, and P3 again faster.
- P3 cools the drink.
- After the cocktail is cooled, R moves the glass from P3 to P4.
- R moves from P3 to neutral position, so that it can move to any of P1, P2, and P3 again faster.
- A customer picks up the drink from P4. A sensor detects that P4 is empty, so that above process can be repeated.
The operation for the cocktail (Straight Martini) is same as the above, except it skips the cooling process. In other words, the mixed drink is moved directly from P2 to P4 without going to P3.
- When a cocktail is requested by pushing a button on the front panel of the machine, R picks a glass from P1 and moves it to P2.
- R moves from P2 to neutral position, so that it can move to any of P1, P2, and P3 again faster.
- P2 mixes the cocktail and pours it into the glass.
- R moves the glass from P2 to P4.
- R moves from P4 to neutral position, so that it can move to any of P1, P2, and P3 again faster.
- A customer picks up the drink from P4. A sensor detects that P4 is empty, so that the above process can be repeated.
The reason to make the machine handle two kinds of recipe sequences is to deliberately make the recipe execution a little more complex by different kinds of system resource requirements under different recipe executions. The timing differences of the same task required by different recipes could result in different system resource action sequences. For example, the drink “Martini” could come out first, even if it is requested later than a drink with longer execution, since the recipe “Martini” does not need the cooling process. If there is no good concurrent architecture, you can imagine that the software needs to deal with these special cases. In this sample, there is no special code to deal with such special cases, since the architecture of routes and the synchronization resources allocated to tasks automatically handle the resource synchronization.
The details of how components Pi work are not important here. The concurrency implementation is the focus of this article.
System Analysis
The following analysis is based on JEK Platform’s concurrent object model. It is recommended to read some samples in the JEK Platform before reading the following analysis.
The JEK object model is that an application engine consists of a matrix of routes and tasks. The rows represent routes, and columns represent tasks. The JEK kernel executes tasks in each route.
For this simple sample, the analysis is straightforward and obvious, even if you have not read any samples in the JEK Platform. Tasks or steps need to be identified so that a potential concurrency can be designed. Two kinds of recipes are processed by the system. The tasks are recipe process steps.
1. Type 1 Recipe
Recipe: Mai Tai, Scorpion Bowl, Zombie
|
Tasks
| Functions
|
CT1
| R gets a glass from P1 and puts it at P2.
|
CTr1
| Then, R moves to the neutral position.
|
CT2
| P2 mixes a requested cocktail, and pours it into a glass. (Exactly how P2 works in not important here.)
|
CT3
| After the cocktail is mixed, R moves the glass from P2 and moves it to P3.
|
CTr3
| Then, R moves to the neutral position.
|
CT4
| P3 begins to cool the cocktail. (Exactly how P3 works in not important here.)
|
CT5
| R moves the glass from P3 to P4.
|
CTr5
| Then, R moves to the neutral position.
|
CT6
| Wait for the customer to pick it up from P4. After a customer picks up the glass from P4, this task performs the necessary operation. We simply assume that T6 polls the hardware to check if the glass is taken away.
|
Figure 2
Since most recipes have the same execution sequence, the same tasks are created for different routes.
Although the Tri (i = 3, 5) task is to retrieve the robot arm to the neutral position, the execution contexts could be different depending on the hardware, since the starting positions are different.
The pipeline observation from the hardware configuration and the above process analysis is as follows:
- After CT3, P2 is free and is ready to mix another cocktail.
- After CT5, P3 is free and is ready to cool another cocktail.
- It is obvious that the bartender machine can hold at most three glasses inside, if the pipeline is implemented. Those three cocktail glasses are held on P2, P3, and P4.
Parallel task analysis:
- Micro concurrency inside a route.
- CTr1 and CT2.
- CTr3 and CT4.
- The system pipeline concurrency operation is obvious from the hardware architecture since it can hold three glasses inside. Therefore, we need to identify the boundaries of the tasks which can be pipelined.
- From CT1 to CTr3.
- CT4.
- From CT5 to CT6.
One route can only implement micro concurrency. The pipeline concurrency has to be implemented with multiple routes. In this sample, each route has the exact same purpose and sequence (except for “Martini”).
These routes share the same system resource which is called the synchronization resource.
If a recipe is pipelined inside the machine, it means that at least one task in the route is executed. Therefore, if four cocktails are requested, only three are pipelined. According to the analysis above, the machine can pipeline three cocktails at the same time. Three identical routes are defined.
The following synchronization resource is defined:
- SR_R represents the robot with the glass handling arm.
- SR_P2 represents P2.
- SR_P3 represents P3.
- SR_P4 represents P4.
Since more than one route could be active concurrently, the task synchronization between the routes is achieved with the synchronization resource, which is analyzed as following:
- For CT1, R is shared by four routes. It is defined as ProducerConsumerSR, with the name SR_R. This synchronization resource prevents four CT1 tasks in four routes to be executed at the same time, which is not allowed because of physical constraints.
- The reason that it can’t be defined as MutexSR is that CTr1 needs to occupy it immediately after CT1. The mutual exclusion is across more than one tasks.
- The reason for not defining CTr1 as part of CT1 is that CTr1 could take a lot of time. If it is defined as part of CT1; less concurrency will be achieved during CT2. Now, CTr1 can be parallel with CT2.
- CT2 in different routes shares P2, which is defined as a ProducerConsumerSR with the name SR_P2.
- CT3 and CTr3 occupy SR_R that is already defined.
- Like CT2, CT4 in different routes shares the same hardware resource P3. We define SR_P3 to represent this synchronization resource.
- CT5 and CTr5 occupy SR_R that is already defined.
- CT6 of different routes share P4. We define SR_P4 to represent this synchronization resource.
Synchronization Resource Allocation
|
Synchronization Resource
| Occupy Task
| Release Task
|
SR_R
| CT1
| CTr1
|
SR_R
| CT3
| CTr3
|
SR_R
| CT5
| CTr5
|
SR_P2
| CT1
| CT3
|
SR_P3
| CT3
| CT5
|
SR_P4
| CT5
| CT6
|
Figure 3
2. Type 2 Recipe
This recipe is a little shorter since it does not need the cooling process. The glass is moved from P2 to P4, instead of P3, after the drink is mixed.
Recipe: Straight Martini
|
Tasks
| Functions
|
CT1
| R gets a glass from P1 and puts it at P2.
|
CTr1
| Then, R moves to the neutral position.
|
CT2
| P2 mixes the requested cocktail, and pours it into the glass.
|
CT3_Martini
| After the cocktail is mixed, R gets the glass from P2 and moves it to P4.
|
CTr3_Martini
| R moves to the neutral position.
|
CT6
| Waits for the customer to pick it up from P4. After a customer picks up the glass from P4, this task performs the necessary operation. We simply assume that T6 polls the hardware to check if the glass is taken away.
|
Figure 4
Implementation
Four routes are created for the application engine. Routes 1, 2, 3 have identical task structures since recipes 1, 2, 3 have identical sequences. The only difference is their execution context. Route 4 has different task structures compared with routes 1, 2, 3.
Route classes
| Functions
|
CRoute1
| Process recipe Mai Tai.
|
CRoute2
| Process recipe Scorpion Bowl.
|
CRoute3
| Process recipe Zombie.
|
CRoute4_Short
| Process recipe Martini.
|
Figure 5
Route class definitions:
class CCustomRouteContext : public knRouteContext
{
public:
CCustomRouteContext(CMachine *pEngine);
~CCustomRouteContext();
CMachine* m_pEngineRef;
CAutoBartender1Dlg* GetDialog();
void AllocateRecipe(CCocktailRecipeBase *pRecipe);
void DeAllocateRecipe();
CCocktailRecipeBase *m_pCocktailRecipe;
};
class CRoute1 : public knRoute
{
public:
CRoute1(knEngine *pEngine, CCustomRouteContext *pCustomRouteContext);
virtual void Construct_CreateRoute_AddTask();
virtual void BeginRoute(knRouteContext *pRouteContext);
virtual void EndRoute(knRouteContext *pRouteContext);
};
class CRoute2 : public knRoute
{
public:
CRoute2(knEngine *pEngine, CCustomRouteContext *pCustomRouteContext);
virtual void Construct_CreateRoute_AddTask();
virtual void BeginRoute(knRouteContext *pRouteContext);
virtual void EndRoute(knRouteContext *pRouteContext);
};
class CRoute3 : public knRoute
{
public:
CRoute3(knEngine *pEngine, CCustomRouteContext *pCustomRouteContext);
virtual void Construct_CreateRoute_AddTask();
virtual void BeginRoute(knRouteContext *pRouteContext);
virtual void EndRoute(knRouteContext *pRouteContext);
};
class CRoute4_Short : public knRoute
{
public:
CRoute4_Short(knEngine *pEngine, CCustomRouteContext *pCustomRouteContext);
virtual void Construct_CreateRoute_AddTask();
virtual void BeginRoute(knRouteContext *pRouteContext);
virtual void EndRoute(knRouteContext *pRouteContext);
};
Engine class definition:
class CMachine : public knEngine
{
public:
CMachine(CAutoBartender1Dlg *pDlg);
~CMachine();
virtual void Construct_Debug_EnableDesignStudio();
virtual void Construct_Create_NamedSystemResource();
virtual bool Construct_CreateJob_AddRoutes();
virtual void EngineNotify__Start_Job();
virtual void EngineNotify__Stop_Job(enumJobStopReason eStopReason);
void InitCocktailRecipes();
CObArray m_arrayRecipe;
CAutoBartender1Dlg *m_pDlg;
};
The simulated recipe is defined in four arrays. Each row defines the execution content for a task. Each route reads this array and allocates the execution items into tasks using the function CCustomRouteContext::AllocateRecipe(CCocktailRecipeBase *pRecipe). The following lists a sample recipe, Mai Tai.
struct strucRecipeStep
{
long lIndex;
long lTimeInMilliSeconds;
char sTaskClassName[128];
char sOperation[128];
char sOperationContext[128];
char sPlatformRobotState[128];
};
const strucRecipeStep RecipeDef_Maitai[TOTAL_RECIPE_EXE_STEPS1] =
{
{0, 10000, "CT1", "R moves glass from P1 to P2.", "Mai Tai glass", "Mai Tai "},
{1, 1000, "CTr1", "R retrieve from P2 to neutral.", "N/A", ""},
{2, 10000, "CT2", "P2 mixes cocktail.", "Mai Tai mix", ""},
{3, 10000, "CT3", "R moves glass from P2 to P3.", "N/A", "Mai Tai"},
{4, 1000, "CTr3", "R retrieve from P3 to neutral.", "N/A", ""},
{5, 10000, "CT4", "P3 cools cocktail.", "Mai Tai cooling", ""},
{6, 10300, "CT5", "R moves glass from P3 to P4.", "N/A", "Mai Tai "},
{7, 1000, "CTr5", "R retrieve from P3 to neutral.", "N/A", ""},
{8, 0, "CT6", "Wait for customer to pick up.", "N/A", ""},
};
Result Analysis and Design Validation
A dialog window is created for simulating the bartender machine. Like real machines, you have to push “Start Machine” to start the bartender concurrent application engine.
When the machine is started by pushing the “Start Machine” button, four menu items are enabled. In this process, the bartender application engine starts four routes in the suspended mode.
The activities of the five components are shown as five boxes. The execution activities, such as what task is occupying the component and what recipe is being processed, are shown inside the boxes.
Validate a Simple Case
You can order a cocktail by pushing one of the four buttons. The glass moves from P1 to P4 during the process of recipe execution, which is marked by the light blue arrow in the following graph. The dark blue arrow shows what kind of drink is on P2 at present.

Figure 6
When processing a recipe, the execution timing is easy to verify. In the following timing diagram of route 0 (executing the Mai Tai recipe), tasks are sequentially executed, and there are two pairs of parallel tasks. The task rendezvous also looks correct.
Figure 7
Validate a Simple Pipeline Case
If more than one drink is ordered, the machine will pipeline the order inside the machine. In the following sample, Mai Tai and Scorpion Bowl are processed by the machine simultaneously, but each drink is at different process steps. In the following machine front panel graph, Mai Tai (route 0) and Scorpion Bowl (route 1) are ordered almost at the same time. Mai Tai on P4 is already done. Scorpion Bowl on P3 is queued and the cooling step is done.
Figure 8
When a drink is ready, it will be on P4 until a customer picks it up by clicking the check box, “Click to pick: (drink)”. Then, the queued drink on P3 will be moved to P4.
For the timing diagram shown below, three timelines marked by blue bubbles are explained:
- R completes the action of moving to the neutral position, after moving the mixed Mai Tai to P3 for cooling. Route 1 (Scorpion Bowl recipe) begins to move the glass from P1 to P2.
- R completes the action of moving to the neutral position after moving the cooled Mai Tai to P4. Now, the Mai Tai glass is on P4. Then, R begins to move the Scorpion Bowl glass from P2 to P3, which is task CT3.
- Route 1 (Scorpion Bowl recipe) CT4 is done. It means that the Scorpion Bowl drink is cooled and can be moved to P4.
Since the customer has not picked up Mai Tai, two drinks are queued inside the system.
Figure 9
Validate a Special Pipeline Case
A special case is studied to test the application engine’s choreography capabilities. The test case is to order Zombie first and followed by Martini immediately.
In the sample, we intentionally give the Martini recipe a shorter execution time than the Zombie recipe (CT4 cooling time is long, so that Martini might catch up the Zombie recipe execution). Since Martini skips the cooling process which is handled by P3, the Martini order might come out first even if the Zombie drink is ordered earlier.
You can imagine that if the cooling process is too short, Martini can never catch up the Zombie. But what is the boundary time of the cooling process that prevents such an event? The quickest way is to simulate.
In this experiment, the Zombie button is clicked first, and then the Martini. The result is that Martini comes out first.
Figure 10
Four timelines marked by blue bubbles on the time diagram below are explained for the above case:
- Route 2 (Zombie recipe) starts execution by starting CT1.
- Route 3 (Martini recipe) starts CT3_Martini, which occupies P4 (SR_P4). This is the most critical event that prevents route 2 from putting a cooled Zombie glass to P4. That is the reason the Martini order catches up the Zombie order even though it is ordered first. The reason that route 2 (Zombie recipe) could not occupy P4 first is that it is still in the cooling process CT4. The task CT5 (after CT4) occupies P4 (SR_P4), but it comes in too late.
- The Zombie drink is done on P3. Route 2 (Zombie recipe) CT4 is done. Zombie drink is cooled, but CT5 is blocked since P4 (SR_P4) is occupied by CT3_Martini of route 3.
- Martini is done and on P4.
If observing carefully, Martini could never catch up Zombie if CT4 is shorter than the vertical line marked by the blue bubble 2.
Figure 11
Demonstrated JEK Platform Features
A few important JEK Platform features are demonstrated in this simple sample:
- The route is a logical job execution path. The machine allows a maximum three cocktails to be pipelined. Four routes are created in the engine to execute four recipes. This concept makes it easier for the user to process different kinds of recipes under the same hardware configuration. Different routes with different task configurations can be created to process different kinds of recipes. A user can click four cocktail buttons at the same time (almost), and the machine will queue the requests based on the synchronization resource definition and its assignment among tasks in the different routes. No code is needed for queuing the recipe since it is handled by the JEK kernel.
- The application engine can be simulated before running on real hardware. This reduces the chances of breaking the hardware when coordinating the hardware operations.
- The timing diagram is generated without any special code in application layer.
- In this sample, different timings can be verified by simply changing the recipe definition, which allows the application engine to be tested under different timing conditions to ensure the quality of the product.
Compare the Pipelined Kernel with Other Possible Solutions
If not using the JEK SDK, the most obvious implementation is to create a thread for each hardware component, since this is the only way to achieve maximum concurrency. The thread manager or the monitor needs to be implemented to monitor what recipe is being executed, which figures out what thread execution context is needed for different recipes. It’s unlikely that a systematic approach is used during the analysis, the architecture could be hard to understand and the thread synchronization code could become very hard to maintain. Even worse, slight hardware modifications could result in massive code changes, which makes future enhancements even harder. Maintaining such code has huge costs.
The solution provided in this article has high maintainability and low enhancement costs since it has an easy to understand architecture. The software development tool also has an integrated simulation and validation environment which greatly simplifies the design and verification.
Limitations and Future Improvements
The most obvious limitations of the current implementation is that the machine can not queue the same kind of cocktail requests, even if the machine can queue up to three glasses internally. For example, the customer can not push the Mai Tai button three times in a short interval to order three Mai Tai-s simultaneously.
Possible Solutions:
At present, the four routes are preloaded with four different kinds of recipes. The JEK SDK requires route objects to be created when the engine is started, and route objects can not be dynamically created or deleted. One possible solution is to create three routes for one kind of recipe, so that the machine has the potential to handle three identical cocktails at the same time. Therefore, twelve routes can be created to handle such a scenario.
The number of routes created has nothing to do with the machine's physical architecture.
Conclusions
The advantages of the implementation presented in this article are:
- The system analysis method is easy to understand, which results in easy implementation of the application engine with the JEK SDK.
- The application engine framework can be easily modified and enhanced by different engineers, as long as they know how to analyze a concurrent system with the JEK object model.
- The JEK Platform supports the application engine validation and simulation that will save development costs.
Alternative implementations with Operating System synchronization primitives and threads will not guarantee a software engineer team to have a systematic analysis method and implement a flexible concurrent kernel architecture. Developing a simulation and validation support environment is not allowed in almost all development teams, which could result in much higher development costs for a product.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.





