Download DOLS_HTML.zip - 364.6 KB (10:52, 07/21/2007, GMT +8)
demo:
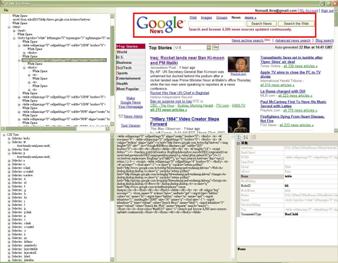
The program is very simple to demonstrate the function of library,
it is similar to demo program of MIL HTML Parser (http://www.codeproject.com/dotnet/apmilhtml.asp).
Introduction
This library produces a tree which like DOM tree of a given non-well-formed HTML document,
allowing the developer to read, compose, and modify the tree in a methodical way.
The library is based on MIL HTML Parser, and I try to improve the codepage
encoding problem, tolerance of tag missing, CSS Resolver and efficiency.
Background
This library was written to avoid having to convert a non-well-formed HTML
into XML prior to reading, whilst preserving the distinct HTML qualities.
Using the code
DOL.DHtml.DHtmlParser.DHtmlGeneralParser parser =
new DOL.DHtml.DHtmlParser.DHtmlGeneralParser();
DOL.DHtml.DHtmlParser.DHtmlDocument htmlDoc =
new DOL.DHtml.DHtmlParser.DHtmlDocument(parser);
htmlDoc.Load(@"..\Google News.htm");
htmlDoc.Save(@"..\Rebuild.htm");
StringBuilder builder = new StringBuilder();
htmlDoc.Dump(builder, "");
System.Diagnostics.Debug.Write("\n" + builder.ToString());
Debug Output information
├Object DHtmlDocument Dump :
│ DHtmlNode number: 6
│ Deep dump in the following:
│ │
│ ├Object DHtmlComment Dump :
│ │ Node ID: 1
│ │ Comment content:
================================================
DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"
================================================
│ │
│ ├Object DHtmlText Dump :
│ │ Node ID: 2
│ │ Text content is white space
│ │
│ ├Object DHtmlComment Dump :
│ │ Node ID: 3
│ │ Comment content:
================================================
saved from url=(0033)http://www.google.com/news?ned=us
================================================
│ │
│ ├Object DHtmlText Dump :
│ │ Node ID: 4
│ │ Text content is white space
│ │
│ ├Object DHtmlElement Dump :
│ │ Node ID: 5
│ │ HTML Tag: <html>
│ │ DHtmlNode number: 3
│ │ Child Object deep dump in the following:
│ │ │
│ │ ├Object DHtmlElement Dump :
│ │ │ Node ID: 6
│ │ │ HTML Tag: <head>
│ │ │ DHtmlNode number: 30
│ │ │ Child Object deep dump in the following:
│ │ │ │
│ │ │ ├Object DHtmlElement Dump :
│ │ │ │ Node ID: 7
│ │ │ │ HTML Tag: <title>
│ │ │ │ DHtmlNode number: 1
│ │ │ │ Child Object deep dump in the following:
│ │ │ │ │
│ │ │ │ ├Object DHtmlText Dump :
│ │ │ │ │ Node ID: 8
│ │ │ │ │ Text content: "Google News"
Structural diagram
HTML Parser

CSS Resolver
History
- 2007/07/21 Modify to create a new StringBuilder instance in each method that needs one in DHtmlTextProcessor
- 2007/05/13 Added structural diagram
- 2007/05/01 Improved tolerance of of attribute structure error
- 2007/04/29 Fixed one bug about tag missing
- 2007/03/28 Updated demo program (Added CSS Resolver demo)
- 2007/03/27 Fixed one bug in initiation of DHtmlElement<chsdate w:st="on" year="2007" month="3" day="22" islunardate="False" isrocdate="False">
- 2007/03/26
1. New demo program
2. Supported "Visitor Patten" in node hierarchy - 2007/03/22 Initial release
James S.F. Hsieh(Nomad Libra) Working as engineer for "Corel Intervideo" company situated in Taiwan.
He received his master degree in Graduate Institute of Network Learning Technology, National Central University, Taiwan in 2006.
His research interests are semantic Web services, intelligent software agent, machine learning, algorithm, software
engineering and multimedia programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






 .
. for your suggesting.
for your suggesting.
 . I wish the original parsing structure does not hinder you to extend these functions. If you need my help, please open mind to tell me. I am very happy this lib can help you.
. I wish the original parsing structure does not hinder you to extend these functions. If you need my help, please open mind to tell me. I am very happy this lib can help you.