Introduction
The included Sophia project is intended to be both instructive and fun. It is, at the most basic level, a chatterbox application with speech synthesis and speech recognition tacked on to it. I originally meant for it to be a showcase of what one can do with the System.Speech namespace, but as the project progressed, it became an obsession with how far I could push the concept of an artificial personality -- what could I do to make the personality seem more real? what could I do to make it more flexible? etc. Along the way, I had the help of my three children, ages 4 through 8, who often wouldn't even let me work on my computer because they were so busy playing with the demo application. This project is dedicated to them, and especially to Sophia, the youngest, for whom the application is named.
This article provides an overview of the various features of the GrammarBuilder class, including how to build increasingly sophisticated recognition rules. I will go over some tricks for making the bot personality appear more lifelike. I will also try to unravel some of the issues involving deploying an SR application to Windows XP rather than deploying to Vista. The included demo runs best on Vista. I have written Sophia to run on Windows XP also, but the speech recognition will necessarily be disabled, since not all methods available through the System.Speech namespace will work on XP. This article will also highlight some of the other gotchas you might encounter while working with the Vista managed Speech API. Finally, it will demonstrate an extensible design that allows multiple speech recognition applications to run together at the same time.
Background
Chatterboxes were among the earliest applications adapted for the personal computer. A chatterbox is simply an artificial personality that tries to maintain a conversation with users using pre-defined scripts. One of the earliest examples is Joseph Weizenbaum's Eliza, written in the mid-sixties. It used a scripted psychiatrist's persona to rephrase anything the user typed into the terminal as a question, and then threw the question back. Many of the games available in the early 80's were text-based, and great attention was paid to making text conversations with the computer both involving and immersive. A large part of this involved techniques for fooling the user, to some extent, into believing that the game he or she was playing was actually intelligent. Ada accomplished this by including enough flexibility so that responses to the user seemed spontaneous. Infocom accomplished this in its text-based adventures by using humor and even a certain amount of scripted self-awareness -- for instance, the game narrator could get into moods, at times, that would affect what would happen next. Emulating intelligence was always a high priority in these games.
The one thing missing from these emulations was the ability to actually talk to the computer using natural language. Even though the movies of the time presented this as something that could be easily accomplished (remember WarGames?), it never was. As speech recognition technology got better, however, the gaming industry also became more visually oriented and less interested in the experiments that were being done with artificial personalities. In the interim period, between then and now, the text-based experience has been sustained mostly by hobbyists who continue to write adventure games for the Z-machine specification created by Infocom, as well as new chatterbox scripts that have evolved over the years to converse over a wider variety of topics, and with a wider selection of responses, than the original Eliza.
The Sophia project is simply an attempt to bring speech recognition and synthesis to the text-gaming experience. With Microsoft's speech recognition technology and the API provided through the .NET 3.0 Framework's System.Speech namespace (formerly SpeechFX), not only is the performance fairly good, but implementing it has become relatively easy. The included demo project uses the AIMLBot interpreter created by Nicholas H.Tollervey. To play Z-machine based games, it uses the .NET ZMachine assembly written by Jason Follas. The AIML files (AIML stands for Artificial Intelligence Mark-up Language) used to give Sophia a personality come from the ALICE A.I. Foundation, and are based on Richard Wallace's prize-winning A.L.I.C.E. AIML set. You can expand the AIML bot personality by adding more files to the AIML FILES subfolder. To play ZMachine (sometimes called Frotz) games, just drop your *.dat or *.z3 file into the ...\Game Data\Data folder (sadly, at this point, the demo only plays games that run on version three of the ZMachine specification and below). Both AIML file sets and Zmachine text-based adventure dat files are ubiquitous on the Internet.
A lot of material about working with Vista and speech recognition can also be found in my introductory article Speech Recognition and Synthesis Managed APIs. If there are aspects of Vista speech recognition that you feel I have breezed through too quickly in this article, it is quite possible the reason is that I have already covered it there.
Playing the Demo
I will begin by going over what the demo application can do. I will follow this up with an explanation of some of the underlying techniques and patterns.
The application is comprised of a text output screen, a text entry field, and a default enter button. The initial look and feel is an IBX XT theme (the first computer I ever played on). This can be changed using voice commands, which I will cover later. There are three menus initially available. The File menu allows the user to save a log of the conversation as a text file. The Select Voice menu allows the user to select from any of the synthetic voices installed on her machine. Vista initially comes with "Anna". Windows XP comes with "Sam". Other XP voices are available depending on which versions of Office have been installed over the lifetime of that particular instance of the OS. If the user is running Vista, then the Speech menu will allow him to toggle speech synthesis, dictation, and the context-free grammars. By doing so, the user will have the ability to speak to the application, as well as have the application speak back to him. If the user is running XP, then only speech synthesis is available, since some of the features provided by .NET 3.0 and consumed by this application do not work on XP.
Speech recognition in Vista has two modes: dictation and context-free recognition. Dictation uses context, that is, an analysis of preceding words and words following a given target of speech recognition, in order to determine what word was intended by the speaker. Context-free speech recognition, by way of contrast, uses exact matches and some simple patterns in order to determine if certain words or phrases have been uttered. This makes context-free recognition particularly suited to command and control scenarios, while dictation is particularly suited to situations where we are simply attempting to translate the user's utterances into text.
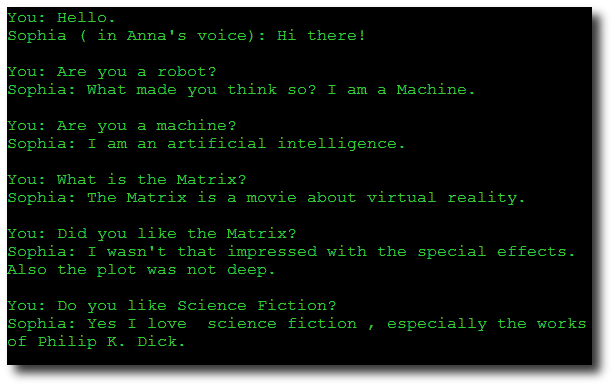
You should begin by trying to start up a conversation with Sophia using the textbox, just to see how it works, as well as her limitations as a conversationalist. Sophia uses certain tricks to appear more lifelike. She throws out random typos, for one thing. She also is a bit slower than a computer should really be. This is because one of the things that distinguish computers from people is the way they process information -- computers do it quickly, and people do it at a more leisurely pace. By typing slowly, Sophia helps the user maintain his suspension of disbelief. Finally, if a text-to-speech engine is installed on your computer, Sophia reads along as she types out her responses. I'm not certain why this is effective, but it is how computer terminals are shown to communicate in the movies, and it seems to work well here, also. I will go over how this illusion is created below.
In Command\AIML\Game Lexicon mode, the application generates several grammar rules that help direct speech recognition toward certain expected results. Be forewarned: initially loading the AIML grammars takes about two minutes, and occurs in the background. You can continue to touch type conversations with Sophia until the speech recognition engine has finished loading the grammars and speech recognition is available. Using the command grammar, the user can make the computer do the following things: LIST COLORS, LIST GAMES, LIST FONTS, CHANGE FONT TO..., CHANGE FONT COLOR TO..., CHANGE BACKGROUND COLOR TO.... Besides the IBM XT color scheme, a black papyrus font on a linen background also looks very nice. You can also say the command "PLAY GAME" to get a list of game files that are available in the \Game Data\DATA subfolder. Either say the name of the game or the numeric position of the game in the list (e.g., "TWO") in order to play it. To see a complete list of keywords used by the text-adventure game you have chosen, say "LIST GAME KEYWORDS." When the game is initially selected, a new set of rules is created based on different two word combinations of the keywords recognized by the game, in order to help speech recognition by narrowing down the total number of phrases it must look for.
In dictation mode, the underlying speech engine simply converts your speech into words and has the core SophiaBot code process it in the same manner that it processes text that is typed in. Dictation mode is sometimes better than context-free mode for non-game speech recognition, depending on how well the speech recognition engine installed on your OS has been trained to understand your speech patterns. Context-free mode is typically better for game mode. Command and control only works in context-free mode.
Using the code
XP vs Vista
The SophiaBot application uses the managed speech recognition and synthesis API for Vista (also called SpeechFX). SophiaBot also works on Windows XP, but only by implicitly disabling speech recognition (speech synthesis will work with SophiaBot on XP if the right components are installed). To understand why some things work and others do not, it is necessary to come to terms with the various parts of the SAPI puzzle. The managed speech synthesis and recognition API is contained in System.Speech.dll, one of the libraries that make up the .NET 3.0 Framework. .NET 3.0, in turn, is not a new version of the .NET Framework, but rather is a set of new libraries that have been curiously named in some sort of marketing effort. To run, then, SophiaBot requires both .NET 3.0 as well as .NET 2.0. The speech library is a wrapper for SAPI 5.3, which in turn is a COM wrapper for the Speech Recognition Engine 8.0. The managed speech API actually makes calls to both SAPI 5.3 as well as directly to the SR engine; it appears to use the former for speech recognition, and the latter, directly, for speech synthesis -- but that's just my impression. Since SAPI 5.3 is just an enhancement to the 5.1 API that can be installed on XP, many of the managed API calls will also work on XP. The grammar objects, which I use extensively, do not, unfortunately.
.NET 2.0, .NET 3.0, SAPI 5.3 and the speech engine all come with Vista, so nothing extra needs to be installed in order to get SpeechFX working on Vista. In order to get partial functionality in XP, both SAPI 5.1 as well as the 6.1 version of the speech engine must be installed. SAPI 5.1 can be downloaded from the Microsoft web site, and it is my understanding that it also comes as part of Windows XP service pack 2. The speech engine gets installed with various versions of Microsoft Office and Outlook. And of course, .NET 2.0 must be installed on the OS in order to get SpeechFX working correctly on XP (surprisingly, it appears after some testing that .NET 3.0 does not have to be installed, since the System.Speech.dll is included in the Sophia install).
Vista comes with the Microsoft Anna voice installed. An additional voice, Microsoft Lili, can be got by installing the Simple Chinese language pack. To my knowledge, no other synthetic voices are currently available.
Dumbing down the application
Using humans as the measure, computers do some things poorly, some things well, and some things too well. One of the things it does too well is respond too quickly. It is a tell that one is dealing with a machine and not a person, and with chatterboxes ruins the illusion that you are actually talking with an intelligence. To compensate for this, I slow the response rate down, so that Sophia's responses mimic a person typing. The code responsible for issuing events to the GUI initially pauses in order to emulate consideration, and then iterates through the characters that make up the response provided by the appropriate rules engine, and issues update events to the GUI one character at a time, with an appropriate intermittent pause.
public delegate void GenericEventHandler<T>(T val);
public event GenericEventHandler<string> Write;
public void TypeSlow(string outputText)
{
if (null == Write)
return;
Thread.Sleep(500);
Write("Sophia: ");
Thread.Sleep(1000);
SpeakText(outputText);
for (int i = 0; i < outputText.Length; i++)
{
Write(outputText.Substring(i, 1));
Thread.Sleep(50);
}
Write(Environment.NewLine + Environment.NewLine);
}
This in itself goes a long way toward propping up the illusion of an intelligent computer personality. Going off of various movies and TV shows, however, it became clear that we also expect the computer personality to speak to us, though the voice must also be somewhat artificial. In Star Trek, for instance, the voice tends to be monotone. In 2001, HAL's voice is human, but artificially calm. Also, the computer personality's speech typically matches the rate at which she types, as if she is reading aloud as she typed, or else as if we are reading her mind as she composes her response. All this is a bit peculiar, of course, since I am using cinematic idioms to judge what will appear natural to the end user -- all the same, it seems to work, as if the sci-fi movies don't so much predict what the future will be like as shape our expectations regarding that future.
The speech synthesizer available through SpeechFX has an async mode, which I use to make the speech synthesis occur at the same time as the typing, and roughly match the pace of the typing.
protected SpeechSynthesizer _synthesizer = new SpeechSynthesizer();
protected bool _isSpeechOn = true;
protected string _selectedVoice = string.Empty;
protected void SpeakText(string output)
{
if (_isSpeechOn)
{
_synthesizer.SelectVoice(SelectedVoice);
_synthesizer.SpeakAsync(output);
}
}
public string SelectedVoice
{
get { return _selectedVoice; }
set { _selectedVoice = value; }
}
Advanced Grammar
Next, I wanted to add speech recognition to my application, in order to hold two-way conversations with Sophia. There are several ways to do this, using SpeechFX. On Vista, I could have used the System.Speech.Recognition.SpeechRecognizer class, which allows one to access the cross-process speech recognition engine that Vista uses for typical command and control scenarios, and which also provides an attractive recognition GUI.

I wanted more control than the cross-process SR engine provides, however, and I also did not want what I did with the engine to affect any other applications, so I decided to use the in-process System.Speech.Recognition.SpeechRecognitionEngine instead. Whereas the SpeechRecognizer class always creates a reference to the same shared recognition engine, no matter what application you call it from, the SpeechRecognitionEngine class allows you to create multiple engines specific to each SR application you have.
For the speech recognition engine to be effective, you must load it up with System.Speech.Recognition.Grammar objects, which indicate the word patterns that you want the speech rec engine to try to match. This, in turn, can be done in two ways: you can either load the default dictation grammar, which will turn your application into a free-dictation application allowing users to say whatever they want and having a pretty good chance of being understood, or you can create custom grammars that steer the speech recognition engine toward certain expected phrases. Sophia actually runs in both modes; the user can select whichever mode works best for him.
Creating a dictation grammar is fairly straight-forward. Just instantiate a default instance of the dictation grammar, unload all other grammars from the recognization engine, and then add dictation.
protected object grammarLock = new object();
protected void LoadDictation()
{
DictationGrammar dictationGrammar = new DictationGrammar();
dictationGrammar.SpeechRecognized +=
new EventHandler<speechrecognizedeventargs />
(recognizer_DictationRecognized);
lock (grammarLock)
{
_recognizer.UnloadAllGrammars();
_recognizer.LoadGrammar(dictationGrammar);
}
}
There is actually more than one SpeechRecognized event that can be used to capture successful speech recognitions. The one thrown from the grammar object runs on a branching thread, and allows you to create special handler methods to deal with the phrase that is captured. This is especially useful when you have multiple grammars running, and want each one to handle speech commands differently. For instance, if besides the main dictation grammar you also want to add a select list of command and control methods, like "File Open" and "File Save", you can create a special method that handles just the command and control speech recognition event, but ignores anything else recognized by the dictation grammar.
Alternatively, you can handle all speech recognition events from all grammars in one place by creating a delegate to intercept the SpeechRecognized event of the speech engine itself, rather than the event thrown by particular grammars. Unlike the event thrown by grammar objects, this event is thrown in the main thread.
In addition to the SpeechRecognized event, the speech recognition engine also throws events when a spoken phrase is rejected, because it cannot be resolved, as well as during the recognition process when different guesses are made by the speech rec engine in an attempt to find an appropriate match.
Sophia captures these events and displays them in the GUI, so users can watch the speech recognition process as it occurs. Recognition successes are displayed in white, rejections are displayed in red, while hypotheses are orange.
Creating custom grammars is much more fun than dictation, however, and also provides a greater degree of control. It works best in command and control scenarios, where you only need to match a few select phrases to implement basic commands. In this demo project, I wanted to see how much further I could push that paradigm, and so I implemented grammars that recognize some 30,000 phrases in order to play old Frotz games using speech recognition, and upwards of 70,000 phrases for the underlying AIML-based artificial personality.
The Command and Control grammar is the simplest, so I will start there. In dealing with grammars, it is important to remember that a Grammar object is built using a GrammarBuilder object. A GrammarBuilder object, in turn, is built on a Choices object. Choices, finally, can be built out of text strings, wildcards, and even other GrammarBuilder objects.
A simple example of building a Grammar object involves a scenario in which the developer has only a few phrases that he wants the speech recognition engine to choose between. Each of these phrases is an alternative choice, and so should be a separate element in a Choices object. Here is some sample code to cover that particular situation:
protected virtual Grammar GetSpeechCommandGrammar()
{
GrammarBuilder gb = new GrammarBuilder();
Choices choices = new Choices();
choices.Add("List Colors");
choices.Add("List Game Keywords");
choices.Add("List Fonts");
gb.Append(choices);
Grammar g = new Grammar(gb);
return g;
}
Another section of the code can set a priority for this grammar, in order to resolve any possible recognition conflicts with other grammars (remember that the higher priority number takes precedence, while a dictation grammar's priority cannot be set); it can give the grammar a name, and it can add an event handler for the SpeechRecognized event to handle the recognition of any of these three phrases.
public override Grammar[] GetGrammars()
{
Grammar g = GetSpeechCommandGrammar();
g.Priority = this._priority;
g.Name = this._name;
g.SpeechRecognized += new EventHandler<speechrecognizedeventargs />
(SpeechCommands_SpeechRecognized);
return new Grammar[1]{g};
}
public void SpeechCommands_SpeechRecognized
(object sender, SpeechRecognizedEventArgs e)
{
string recognizedText = e.Result.Text;
if (recognizedText.IndexOf
("list colors", StringComparison.CurrentCultureIgnoreCase)>-1)
{
StringBuilder sb = new StringBuilder();
foreach (string knownColor in Enum.GetNames(typeof(KnownColor)))
{
sb.Append(", " + knownColor);
}
Write(sb.ToString().Substring(2));
}
else if (recognizedText.IndexOf
("list fonts", StringComparison.CurrentCultureIgnoreCase) > -1)
{
StringBuilder sb = new StringBuilder();
foreach (FontFamily font in
(new System.Drawing.Text.InstalledFontCollection()).Families)
{
sb.Append(", " + font.Name);
}
Write(sb.ToString().Substring(2));
}
else if (recognizedText.IndexOf
("list game keywords", StringComparison.CurrentCultureIgnoreCase) > -1)
{
if (_gameEngineBot != null)
{
Write( _gameEngineBot.ListGameKeywords());
}
else
Write("No game has been loaded.");
}
}
Finally, the grammar can be added to the in-process speech recognition engine.
This was a fairly simple scenario, however, and I want to cover some more complex grammars next. It may be the case that you want to recognize a certain set of keywords, but do not care what comes before or after. For instance, if you want the phrase "Play Game" to be recognized, as well as "Let's Play Game" or even "Whoozit Play Game", you can create a grammar that catches each of these phrases by using the AppendWildcard() method of the GrammarBuilder class.
The following example does just this, using grammar builders to create phrases that include wildcards. The grammar builders are then added to a choices object. The choices object is added to another grammar builder object, and finally a grammar is created from that grammar builder. (It should be pointed out that speech recognition is, naturally, not case sensitive. I use ALL CAPS to build grammars so that when a phrase is matched and returned to the GUI from the SpeechRecognized handler, matched phrases, as they are formatted in the SpeechRecognizedEventArgs.Result.Text field, can be distinguished from other phrases because they are returned in the same form in which they appear in the grammar, i.e., in this case, capitalized.)
protected virtual Grammar GetPlayGameGrammar()
{
Choices choices = new Choices();
GrammarBuilder playGameCommand = null;
playGameCommand = new GrammarBuilder();
playGameCommand.AppendWildcard();
playGameCommand.Append("PLAY GAME");
choices.Add(playGameCommand);
playGameCommand = new GrammarBuilder();
playGameCommand.Append("PLAY GAME");
playGameCommand.AppendWildcard();
choices.Add(playGameCommand);
choices.Add("PLAY GAME");
return new Grammar(new GrammarBuilder(choices));
}
There is one problem with the AppendWildcard() method. If you use it, you will not be able to retrieve the text that was recognized in the wildcard position. Instead, if you examine the SpeechRecognizedEventArgs.Result.Text field, you will find that the matched speech recognition text comes back as "... PLAY GAME", with elipses replacing the missing word.
If you need to know the missing word, then you should use the AppendDictation() method, instead. AppendDictation() basically tries to match one of the hundred thousand or so words that come with the default Dictation vocabulary in the place in the phrase where it is added. if AppendDictation() were used in the code above instead of AppendWildcard(), then you would be able to capture the missing word in phrases like "Let's play a game", or even "Cat play a game". "Whoozit play a game", however, still would never be returned in the SpeechRecognizedEventArgs parameter, since "Whoozit" isn't contained in the dictation vocabulary. In a tie between a choice that uses a wildcard place holder, and a choice that uses a dictation place holder, it appears (from the limited time I've spent playing with grammar building) that the dictation place holder is more likely to be recognized.
So far, you've seen that you can use the grammar builder object to add phrases, add wildcards, and add dictation place holders. In a very powerful variation, you can also append a Choices object. This is useful in cases where you have a short phrase, but want the last word of the phrase to come from a list. For instance, you might want to create a speech command such as "My home state is ...", but then instead of having the last word be either a wildcard (since this prevents you from capturing the final word spoken by the user) or a dictation (since this still allows too many inappropriate options), you want to limit the final word to one of the fifty legitimate answers. To accomplish this, you would create a Choices object to hold the names of the fifty states, and then use the Append() method to add it to your grammar builder. In a similar vein, the example below, based on sample code found in the MSDN library, uses the KnownColor enum to create a grammar that allows the user to select a new color for the active font.
GrammarBuilder gb = new GrammarBuilder();
Choices choices = new Choices();
GrammarBuilder changeColorCommand = new GrammarBuilder();
Choices colorChoices = new Choices();
foreach (string colorName in System.Enum.GetNames(typeof(KnownColor)))
{
colorChoices.Add(colorName.ToUpper());
}
changeColorCommand.Append("CHANGE COLOR TO");
changeColorCommand.Append(colorChoices);
choices.Add(changeColorCommand);
gb.Append(choices);
Grammar g = new Grammar(gb);
This technique was particularly useful in building the Frotz game grammars. If you recall ever playing these text adventure games (from my youth but perhaps not yours), each game has a vocabulary of 200 or so words. At first blush, this would seem like a lot of keywords to build a grammar out of, given the number of permutations you can create from 200 words; in practice, though, all useful Frotz commands are either single words or two word combinations. By creating grammars that included all the two word combinations that can be built from the available keywords as choices, I ended up with a pretty effective speech recognition tool, even though the final grammar includes tens of thousands of choices. For good measure, I also added each keyword as a single word choice, as well as keyword + dictation combinations.
protected virtual Grammar GetGameGrammar()
{
Choices choices = new Choices();
Choices secondChoices = new Choices();
GrammarBuilder before;
GrammarBuilder after;
GrammarBuilder twoWordGrammar;
foreach (string keyword in GameLexicon.GetAllItems())
{
if (keyword.IndexOf("\"") > -1)
continue;
string KEYWORD = keyword.ToUpper();
before = new GrammarBuilder();
before.AppendDictation();
before.Append(KEYWORD);
after = new GrammarBuilder();
after.Append(KEYWORD);
after.AppendDictation();
choices.Add(before);
choices.Add(after);
choices.Add(KEYWORD);
secondChoices.Add(KEYWORD);
}
foreach (string firstKeyword in GameLexicon.GetAllItems())
{
if (firstKeyword.IndexOf("\"") > -1)
continue;
string FIRSTKEYWORD = firstKeyword.ToUpper();
twoWordGrammar = new GrammarBuilder();
twoWordGrammar.Append(FIRSTKEYWORD);
twoWordGrammar.Append(secondChoices);
choices.Add(twoWordGrammar);
}
Grammar g = new Grammar(new GrammarBuilder(choices));
return g;
}
Historical note: while you are playing a Frotz game (also known as a Z-Machine game) in Sophia, you will notice that the keywords are sometimes truncated. For instance, there is no keyword for the ubiquitous "lantern", but there is one for "lanter". This was a technique employed in the original games to handle wildcard variations and misspellings.
Bot Command Pattern
In building SophiaBot, I used a variation of the command pattern that seems to work fairly well in managing SR functionality. The pattern solves several problems. First, each object that implements the IBotServer interface is responsible for managing its own grammars as well as all rules for responding to recognized input. Next, if a phrase is not adequately handled by a given IBotServer implementation, the recognition phrase should be passed on to another IBotServer for processing. For SophiaBot, I built four different Bot Servers (or, to put it another way, alternate artificial personalities for the Sophia personality). AIMLBotAdapter is a chatterbox that uses the included AIML files (Artificial Intelligence Mark-up Language) to form responses to user input. SpeechCommandBot handles a series of simple commands that allow the user to change the font color of the GUI or list the keyword commands used by the active WinFrotz game. PlayGameTransition is a text-based dialog that allows users to select a game to play from the available games found in the games directory. Finally, GameEngineBot actually loads up a game for play and creates a grammar based on the core vocabulary of the text-adventure game selected.
This design succeeds in handling at least two scenarios: one in which typed text is entered through the main interface, and two, when a spoken phrase is recognized by a particular grammar associated with a particular bot. When only text is entered using the keyboard, it is impossible to know which bot contains the correct handler. In this case, it is important that each bot is linked to another bot in serial fashion. The Read()method of the first bot in the link is called first, and it passes the entered text to its rules engine. If the engine is unable to find an appropriate response, the bot passes the entered text on to the Read() method of the next bot in the series until there are no bots left. When speech recognition is enabled using specialized grammars, the text will not necessarily commence with the first bot in the series. Instead, it will go to the bot associated with the grammar object that was best able to match the spoken phrase, which may equally be the first or the fourth bot in the chain. The SpeechRecognized handler for that grammar will then pass the recognized text to the Read() method of the object that contains it. For instance, if the grammar associated with the GameEngineBot recognizes the spoken phrase, then the Read() method of the GameEngineBot will attempt to come up with a proper response to the input. Only if it fails to come up with a response will it pass the input to the next bot in the chain as text.
The IBotServer interface also keeps track of the state of each bot, and throws events when a bot starts or stops. This is handy, since it allows the client object to determine how to manage the speech recognition engine when various events occur. For instance, when the game engine stops, I want the client to actually remove its grammars and then reload them when the game engine is restarted, since each game will have a different set of keywords and consequently will need a different grammar. The AIML bot, on the other hand, always uses the same set of grammars, and moreover recreating them is rather time consuming. In this case, I want to simply disable all the grammars when the engine is stopped rather than remove them completely from the speech recognition engine. The client is still responsible for determining most of the workflow and interaction between bots using this pattern, but a common interface helps at least to mitigate some of the complexity involved.
_aimlEngine = new AIMLBotAdapter(aIMLFolderPath);
_aimlEngine.OnUserInput += new GenericEventHandler<string />(DisplayUserInput);
_aimlEngine.OnStart += new EventHandler(EnableSelectedGrammar);
_aimlEngine.OnBotInfoResponse += new GenericEventHandler<ibotserver, />(TypeVerbatim);
_aimlEngine.OnBotResponse += new GenericEventHandler<ibotserver, />(TypeSlow);
_aimlEngine.OnFinish += new EventHandler<finisheventargs />
(DisableSelectedGrammar);
_aimlEngine.OnTextRecognized += new GenericEventHandler<string />
(IBotServer_OnTextRecognized);
_aimlEngine.OnUpdateLoadStatus += new GenericEventHandler<string />
(IBotServer_OnUpdateStatus);
GameEngineBot gameEngine = new GameEngineBot();
gameEngine.SavedGamesFolderPath = savedGamesFolder;
gameEngine.OnUserInput +=new GenericEventHandler<string />(DisplayUserInput);
gameEngine.OnStart +=new EventHandler(LoadSelectedGrammar);
gameEngine.OnBotInfoResponse += new GenericEventHandler<ibotserver, />(TypeVerbatim);
gameEngine.OnBotResponse += new GenericEventHandler<ibotserver, />(TypeSlow);
gameEngine.OnFinish += new EventHandler<finisheventargs />
(UnloadSelectedGrammar);
gameEngine.OnTextRecognized += new GenericEventHandler<string />
(IBotServer_OnTextRecognized);
gameEngine.OnStart += new EventHandler(gameEngine_OnStart);
gameEngine.OnFinish += new EventHandler<finisheventargs />
(gameEngine_OnFinish);
...
_firstBot.AddNextBot(_dialogEngine);
_dialogEngine.AddNextBot(gameEngine);
gameEngine.AddNextBot(_aimlEngine);
_aimlEngine.Start(aIMLFolderPath);
_dialogEngine.Start(gameDataFolder);
_firstBot.Start();
Gotchas!
For this application, I wanted to use the async methods of the speech synthesizer as well as the asyc methods of the speech recognizer, so that screen updates and text entry could all occur at the same time as these other activities. One of the problems in doing this is that the synthesizer and the recognizer cannot process information at exactly the same time and will throw errors if this is attempted, and so I had to throw in lots of synchronization locks to make sure that the recognizer was disabled whenever the synthesizer was active, and then turned on again when the synthesizer was done. This would have all been a lot simpler had I simply used the synchronous Speak() and Recognize() methods, but, alas, I got over-ambitious, and in the end the effect is much better, though I constantly worry that there is a deadlock scenario I have not completely worked out. Another gotcha is that the grammars don't always return events on the main thread, and so the Invoke() and BeginInvoke() methods of the main GUI form have to be used frequently in order to handle any delegates that originate in the Grammar.SpeechRecognized event. Invoke() and BeginInvoke() ensure that these events are handled in the main thread rather than some rogue thread, and that the calls are consequently thread-safe. Finally, loading grammars and unloading them cannot be done while speech recognition is active, and so this involves adding even more checks to make sure that the speech recognition engine is not recognizing when these actions are attempted. This involves not only cancelling any ongoing activity in the speech recognizer, but also making sure that any code that is currently processing a SpeechRecognized event has truly finished. Unless you are quite good at working with multi-threaded applications (I'm not particularly), then I would recommend going slowly and adding features one at a time in your own SR applications, in order to make sure that all threads end where you want them to, before moving on to more complex threading scenarios.
If you encounter any bugs in the code, come up with a better design for the IBotServer interface, or simply have one more bot that you think would work well in Sophia, please drop me a note. I look forward to reading your insights into how Sophia can be improved.
Further Reading
- More chatterbox scripts
- More zmachine games
- Jason Follas (author of the C# ZMachine used in this project)
- Nicholas H. Tollervey (author of the AIML interpreter used in this project)
Code Project articles
- Artificial Intelligence (AI) Chatbot and AI Chatbot Wizard: Create, Train and Chat by dzzxyz
- AI Chat bots Developing by elagizy
- Chatterbot Eliza by Gonzales Cenelia
- Borg Knowledge Assimilator by Sean Michael Murphy
- Building an AI Chatbot using a Regular Expression Engine by MattsterP
Article History
- 3/31/07 - [Correction] Eliza was the name of the original chatterbox, not Ada
- 3/31/07 - [Corrected link to other article]
- 3/31/07 - Added reading list, so that everyone who has covered this territory before receives proper acknowledgment
James is a program writer for a respectable software company. He is also a Microsoft MVP.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






