Introduction
The project that I’m currently working on is a framework that will enable other developers, for the next few years, to add algorithms that write the results to a quite large buffer. This data can be from one bit to several hundreds of KWords. The word size can vary from one execution to another, and the algorithms place the results to arbitrary addresses in the buffer.
Instead of allocating a huge byte array or a dynamic collection, we thought that it would be useful to split the buffer in small pieces, which allocate memory on demand. For security reasons, we added a bit level overwrite protection mechanism, to detect, as soon as possible, errors in the algorithms that cause them to write twice to the same position.
In this article, I try to explain my implementation of this buffer.
Background
The design of this buffer has a tight relationship with our application. An example of this is that, by default, all bits are set to 1. Apart from that, you may need a buffer with overwrite protection, with allocation on demand, or with another features that our buffer has, therefore I won’t try to justify why this design is useful for us, but I’ll try to make it clear how it works and how to use it.
At the end of the article, I’ll give some ideas on how to improve this design.
What does the buffer look like?
Let’s say that we need a buffer with a word size of 17 bits and a depth of 10MWord. How do we organize the buffer?
The first thing we have to do is split the buffer in pieces; we call these pieces Sectors, and in our case, they are all the same size, but it doesn’t have to be like this. So, our buffer will have a collection of Sectors. The memory needed by these sectors is allocated the first time we try to write to them (note that we don’t need to allocate the memory to read the default values). In our application, an arbitrary number of these sectors will never be written. With this technique, we save a lot of memory. In our example, we could split the 10MW in 160 sectors of 64KW.
We want to write data at bit level. Instead of giving the user of the buffer access to the word, we provide a set of Write methods implemented in a Word class. To be able to configure the number of bits per word, we implement each word as a byte array, and these Write methods wrap the access to these arrays (3 bytes per word, in our example). Furthermore, because we allocate a full sector at once, instead of having an array of byte arrays, we have a single byte array per sector (3 bytes/Word*64KW), and the Word class works with a subset of this array.
To be able to have overwrite protection, we need to keep track of all bits already written. We store this information in a buffer that I call BlackAndWhiteBuffer, and it has a bit per each bit in the data buffer. This means that we’ll use twice the memory that is required without overwrite protection. This alone justifies the concept of “locking” a sector when we are finished with it, making it read-only, and therefore we don’t need the BlackAndWhiteBuffer anymore, freeing its memory.
The last concept that we introduced to operate with this buffer is the Window. A window to the buffer gives access to a subset of the buffer. The algorithms access the buffer through these windows; this way we apply an offset to their output and we limit their access to the memory, because the window doesn’t give access outside of its boundaries.
The following diagram should help to understand these concepts.

In the diagram, we see that we can access the buffer through three different views:
- Memory view: continuous access to the whole buffer
- Windows: access through defined windows
- Sectors view: access through the individual sectors
Let’s analyze the examples shown in the diagram:
- Write access 1 shows how writing to the buffer causes the allocation of the whole sector and the corresponding
BlackAndWhiteBuffer. The data is seen on all views. - Write access 2 shows how we have the same behavior without having a window defined.
- Write access 3 shows that a sector has been allocated and then locked (the
BlackAndWhitBuffer is not present). The following sector has been locked before being allocated. Reading it will return the default word value. Note that we can’t lock a window, because it could share a sector with another active window.
Implementation
This solution is implemented in two assemblies:
Buffers.IWriteOnceBuffers: defines the interfaces for all classes as required by our guidelines, which I won’t discuss here, and custom exceptions.Buffers.WriteOnceBuffers: implements the specified functionality.
Shown below are the definitions of the main interfaces:
A few notes on the interfaces:
- Buffer, Sector, and Window have a property
Words that gives access to the collection of words. As explained before, these are not real collections, but different ways to access the underlying buffers. - Buffer offers two methods to add and remove windows.
- All interfaces implement
IEquatable<T>. These specific implementations compare the contents of the buffers. - Sector and Window have
StartAddress and EndAddress properties, but the access to the data is by offset (from 0 to Depth-1). - The low level work is done by the class
WordBuffer. This class is used instead of a plain byte[], and controls the data width, the allocation on demand, the initialization to the default value, and the locking. - In the following fragment of code, you can see the constructor and the operations of setting and getting data.
public WordBuffer(int numWords, int numBytesPerWord, long defaultValue)
{
if(numBytesPerWord < cntMinNumBytesPerWord || numBytesPerWord > cntMaxNumBytesPerWord )
throw new ArgumentOutOfRangeException("numBytesPerWord",
string.Format(CultureInfo.InvariantCulture, StringResources.ArgumentOutOfRangeMessage,
"numBytesPerWord", numBytesPerWord, cntMinNumBytesPerWord, cntMaxNumBytesPerWord));
this.numWords = numWords;
this.numBytesPerWord = numBytesPerWord;
long bwValue = defaultValue;
defaultValueInBytes = new byte[numBytesPerWord];
for(int i=0; i<numBytesPerWord; i++)
{
defaultValueInBytes[i] = (byte)bwValue;
bwValue>>=8;
}
for(int i=numBytesPerWord-1; i>=0; i--)
this.defaultValue = (this.defaultValue<<8) + defaultValueInBytes[i];
}
public long GetIntegerData(int byteOffset)
{
if(buffer==null)
{
return defaultValue;
}
else
{
switch(numBytesPerWord)
{
case 1:
return (long)buffer[byteOffset];
case 2:
return (long)BitConverter.ToUInt16(buffer, byteOffset);
case 4:
return (long)BitConverter.ToUInt32(buffer, byteOffset);
default:
long data = 0;
for(int i=numBytesPerWord-1; i>=0; i--)
data = (data<<8) + buffer[byteOffset+i];
return data;
}
}
}
public void SetIntegerData(int byteOffset, long value)
{
if(IsLocked)
throw new BufferIsReadOnlyException();
if(buffer==null)
AllocateBuffer();
Buffer.BlockCopy(BitConverter.GetBytes(value), 0, buffer, byteOffset, numBytesPerWord);
}
The WriteOnceBufferWord class is in charge of writing the data in the correct address, in the correct format, and controlling the overlaps. We don’t need an instance of this class per word, the same instance can be positioned on a specific address and given access to the right data. The WriteOnceBufferWordCollection class is in charge of positioning the word on the right offset.
Here follows two methods of WriteOnceBufferWord to modify a word:
public long Write(long value, long mask)
{
if( (IntegerBlackAndWhite & mask) != mask )
throw new WriteOverlappingException();
IntegerData &= (value|~mask);
IntegerBlackAndWhite &= ~mask;
return IntegerData;
}
public long Write(long value, int bitOffset, int lengthInBits)
{
if(lengthInBits==0)
return IntegerData;
long mask = 0x01;
for(int i=1; i<lengthInBits; i++)
{
mask<<=1;
mask|=0x01;
}
mask<<=bitOffset;
value<<=bitOffset;
return Write(value, mask);
}
As you can see, these methods access IntegerData and IntegerBlackAndWhite. These are two private properties of the same class that wrap the access to the right position on the buffer.
private long IntegerData
{
get
{
return ownerSector.DataBuffer.GetIntegerData(byteOffset);
}
set
{
ownerSector.DataBuffer.SetIntegerData(byteOffset, value);
}
}
private long IntegerBlackAndWhite
{
get
{
return ownerSector.BlackAndWhiteBuffer.GetIntegerData(byteOffset);
}
set
{
ownerSector.BlackAndWhiteBuffer.SetIntegerData(byteOffset, value);
}
}
To access the data as an integer number instead of a byte array, I convert it to a long. This limits the maximum number of bits per word to 63, which is enough for our application.
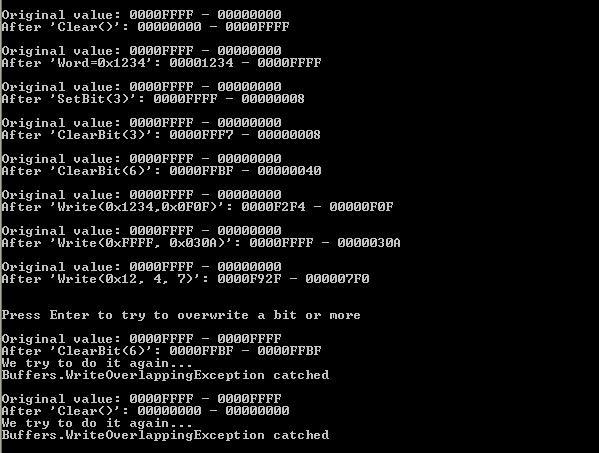
Sample application
The sample program that you can download is not a real life application, but a series of tests to show how to use the class and the effect of some operations on the allocated memory. Please note that the values shown include other variables and data used by the program, and it’s not intended to be a precise measurement of the memory used by each class or member.
Points of interest
This implementation has got to this, more or less, stable point after some iterations to improve its performance, which is still affected considerably by the fact that the default word value is not 0. Some improvements could be done by implementing initialization on demand, for example. Another point that affects the performance is the transformations between byte[] and long. Maybe these transformations could be skipped at some points. Other ideas on improving performance are very welcome.
If you have a look to the implementation of WriteOnceBufferWordCollection, you’ll see that it implements IList<IWriteOnceBufferWord> to provide type safe access to the collection, but it implements the IList too. This allows the use of data binding with controls like DataGridView in WinForms 2.0. You can bind quite large buffers to a grid in two lines of code.
For extremely large buffers, it would be interesting to implement some sort of serialization to disk, for example, for locked sectors. Now, the whole buffer can be serialized and deserialized easily with the two static methods provided. This serialization keeps the exact state of the buffer. If a sector is locked, it requires obviously less disk space.
Version history
- 10/03/2008: First published.
I finished my Degree in Industrial Electronics in the year 2000. I worked for 6 years as a Hardware and Software development engineer in Barcelona. On January 2007 I moved to Dublin to work as Software Engineer and I specialised in .NET technologies. Currently I'm consulting for other companies and running my own start up project Trainer Inside (www.trainerinside.com)


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





