Introduction
This project was initially started by Rama who did almost all of the coding.
Personal affairs halted his progress and he handed it over to Nish who took it
up from where Rama had left off. Nish finished off the stuff and did some
statistical analysis on the results obtained. We wanted to get an idea of how different languages and tools compare with
each other in terms of performance. There are a variety of categories
where speed and performance can be measured, but the first thing which that came
to mind was
computation, and thus prime number generation was chosen as the criteria.
The next job was to decide how to implement something that can be
performance-compared in various languages. First the various common options had
to be chosen. We picked up the following ten different language options that are
available to the general Microsoft programmer.
The participants
- Visual C++ 7
- Visual Basic 6
- C#
- VB.NET
- Managed C++ compiled totally to IL
- Managed C++ with arithmetic intensive stuff in unmanaged code
- C# ngen'd
- VB.NET ngen'd
- Managed C++ compiled totally to IL and ngen'd
- Managed C++ with arithmetic intensive stuff in unmanaged code and ngen'd
The objective was to use a single test application to run and measure the
timings. Thus component DLLs were developed in all 10 language options. We ignored considering the overhead
due to COM in .NET calls as we did not expect it to be very significant.
The Code
We used a simple COM interface that, when given the number of primes to compute,
computed them. The IComputePrimes interface looks like this:-
interface IComputePrimes : IDispatch
{
HRESULT CalculatePrimes([in] int numPrimes);
};
This was generated by using the default options of the ATL object wizard. Any object
implementing this interface is expected to calculate and store as many prime
numbers as specified by numPrimes .
Now let's see how the code looks like for various cases.
The C++ code
STDMETHODIMP CComputePrimes::CalculatePrimes(int numPrimes)
{
if (m_rgPrimes != NULL)
delete [] m_rgPrimes;
m_rgPrimes = new int[numPrimes];
m_rgPrimes[0] = 2;
m_rgPrimes[1] = 3;
int i = 2;
int nextPrimeCandidate = 5;
while(i < numPrimes)
{
int maxNumToDivideWith = (int)sqrt(nextPrimeCandidate);
bool isPrime = true;
for(int j = 0;
(j < i) && (maxNumToDivideWith >= m_rgPrimes[j]);
j++)
{
if ((nextPrimeCandidate % m_rgPrimes[j]) == 0)
{
isPrime = false;
break;
}
}
if (isPrime)
m_rgPrimes[i++] = nextPrimeCandidate;
nextPrimeCandidate += 2;
}
return S_OK;
}
The prime numbers computed are stored in an integer array m_rgPrimes. The above
code tries to divide an odd number with all the prime numbers which are less
than its square root to decide whether the number is a prime or not. If yes it
stores it the array.
C# and MC++
The code for C#, Managed C++ is similar except that in the two cases with
Managed C++ where we mix native code into the managed code, the code is broken
into two separate functions as shown below.
void CalculatePrimes(int numPrimes)
{
primes = new int __gc[numPrimes];
int __pin* rgPrimes = &primes[0];
UnmanagedComputePrimes (rgPrimes, numPrimes);
}
The array is a managed array and we pin the array and call an unmanaged
function
that calculates the primes and fills the array.
VB/VB.NET Code
Private Sub IComputePrimes_CalculatePrimes(ByVal numPrimes As Long)
ReDim Primes(numPrimes)
Primes(1) = 2
Primes(2) = 3
Dim NextPrimeCandidate As Long
NextPrimeCandidate = 5
Dim i As Long
Dim j As Long
Dim MaxNumToDivideWith As Long
Dim IsPrime As Boolean
i = 3
Do While i <= numPrimes
MaxNumToDivideWith = Sqr(NextPrimeCandidate)
IsPrime = True
j = 1
Do While (j <= i) And (MaxNumToDivideWith >= Primes(j))
If NextPrimeCandidate Mod Primes(j) = 0 Then
IsPrime = False
Exit Do
End If
j = j + 1
Loop
If IsPrime Then
Primes(i) = NextPrimeCandidate
i = i + 1
End If
NextPrimeCandidate = NextPrimeCandidate + 2
Loop
End Sub
The VB.NET code looks similar with Sqr replaced with System.Math.Sqrt function.
The VB6 code is compiled with optimizations that will closely resemble the
generated C++ code like removing all integer overflow checks.
The test clients
All the cases are compiled into a DLL. All assemblies are registered for COM
interoperability. We have two test clients, a managed client and a native
client. The native client is coded in VC++ and uses the #import keyword.
__int64 ComputeAndGetResults(
ATLPrimesLib::IComputePrimesPtr spComputePrimes,
int numPrimes)
{
LARGE_INTEGER li1, li2;
li1.QuadPart = 0;
li2.QuadPart = 0;
QueryPerformanceCounter(&li1);
spComputePrimes->CalculatePrimes(numPrimes);
QueryPerformanceCounter(&li2);
return li2.QuadPart - li1.QuadPart;
}
int _tmain(int argc, _TCHAR* argv[])
{
try
{
ATLPrimesLib::IComputePrimesPtr spComputePrimes(argv[1]);
int numPrimes = atol(argv[2]);
LARGE_INTEGER f;
QueryPerformanceFrequency(&f);
std::cout << ComputeAndGetResults(spComputePrimes, numPrimes);
}
catch(_com_error& e)
{
}
return 0;
}
The managed client is written using C#.
try
{
Assembly assem = Assembly.Load(args[0]);
IComputePrimes primes =
(IComputePrimes)assem.CreateInstance(args[1]);
int numPrimes = Int32.Parse(args[2]);
long t1 = 0, t2 = 0;
QueryPerformanceCounter(ref t1);
primes.CalculatePrimes(numPrimes);
QueryPerformanceCounter(ref t2);
long freq = 0;
QueryPerformanceFrequency(ref freq);
Console.Write(t2 - t1);
}
catch(Exception e)
{
Console.Error.WriteLine(e.ToString());
}
Both the clients use the QueryPerformanceCounter API call as a
measure of the performance. The lesser the better. We have a program called
RunMultipleTests [C#] that calls both the clients for each of the 10 types of
DLLs. Take a look at the Main.cs file for how this is implemented. We called all
10 implementations once each to generate 10 primes, then 100, 1,000, 10,000,
100,000 and finally 1,000,000 (One million).
The results
I have selected a few of the generated results for discussion here. Smaller
numbers indicate higher performance.
| Language | Primes | Native Callee | Managed Callee |
| ATLPrimes | 10 | 18,241 | 192,538 |
| VBPrime | 10 | 21,057 | 191,597 |
| CSharpPrimes | 10 | 1,201,258 | 1,003,710 |
| CSharpPrimes (ngen'd) | 10 | 99,017 | 20,357 |
| VBNetPrimes | 10 | 1,680,241 | 1,440,198 |
| VBNetPrimes (ngen'd) | 10 | 101,201 | 21,644 |
| MCPPPrimes1 | 10 | 1,443,943 | 1,117,279 |
| MCPPPrimes1 (ngen'd) | 10 | 107,362 | 29,574 |
| MCPPPrimes2 | 10 | 977,667 | 699,355 |
| MCPPPrimes2 (ngen'd) | 10 | 127,969 | 53,861 |
The above table shows the various results obtained when generating 10 primes.
As you can observe, the fastest performance was for the ATL DLL invoked from a
native C++ client. But it might surprise you to see that when the same DLL was called from a managed client through .NET COM interop, the performance has
fallen by almost 900%. So much for COM interop and it's supposed efficiency. It
hurt my ego a good deal to see that the VB DLL invoked from a native client
showed far superior performance to the Managed C++ DLL. Funnily the managed DLLs
don't show a drastic difference in performance between native invocation and
managed invocation. The exception is the MC++ DLL version 2 which is the
unmanaged-managed mixed version. All the managed DLLs show an amazing
performance increase when ngen'd. Perhaps it's time we all started taking ngen
more seriously. Very surprisingly, the ngen'd C# DLL was the second fastest of
all combinations. Curiously the VB.NET DLL was the slowest of them all. Here is
a graph of the above table.
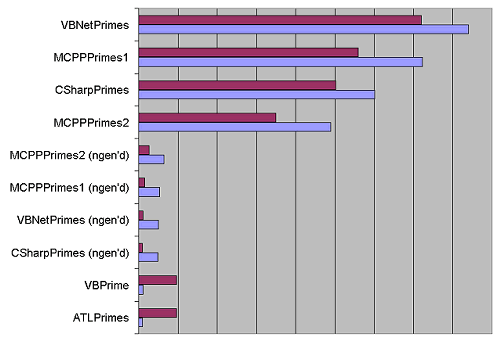
But then 10 primes is too small a number to be making such observations.
Therefore we'll now move onto the results for 1000 primes. The excel sheets in
the download will list the full tables for those who are interested. And you can
always tweak the sample projects to give you other combinations and
permutations.
| Language | Primes | Native Callee | Managed Callee |
| ATLPrimes | 1000 | 1,674,822 | 1,843,077 |
| VBPrime | 1000 | 1,659,063 | 1,830,014 |
| CSharpPrimes | 1000 | 2,951,717 | 2,665,328 |
| CSharpPrimes (ngen'd) | 1000 | 1,755,078 | 1,655,643 |
| VBNetPrimes | 1000 | 3,606,253 | 3,400,125 |
| VBNetPrimes (ngen'd) | 1000 | 2,108,643 | 1,954,464 |
| MCPPPrimes1 | 1000 | 3,110,415 | 2,742,913 |
| MCPPPrimes1 (ngen'd) | 1000 | 1,719,734 | 1,642,938 |
| MCPPPrimes2 | 1000 | 2,678,031 | 2,359,011 |
| MCPPPrimes2 (ngen'd) | 1000 | 1,748,994 | 1,742,121 |
Well, well, well! Suddenly the performance comparisons don't seem as
contrasting as they did when we generated 10 primes. Now the combination that
gave best performance is the fully managed MC++ DLL after ngen'ing. What is so
painful is to see that the VB6 DLL has out-performed the ATL DLL in both managed
and native invocation. Again VB.NET shows pathetic performance. But again you'll
see that ngen'ing has an amazing performance boost effect on the managed
assemblies. Now let's skip a few tables and go straight to the one million mark.
| Language | Primes | Native Callee | Managed Callee |
| ATLPrimes | 1000000 | 19,389,792,910 | 19,400,345,304 |
| VBPrime | 1000000 | 19,334,822,911 | 19,340,626,315 |
| CSharpPrimes | 1000000 | 19,371,408,155 | 19,426,052,083 |
| CSharpPrimes (ngen'd) | 1000000 | 19,386,294,992 | 19,325,672,507 |
| VBNetPrimes | 1000000 | 19,870,238,968 | 19,980,902,937 |
| VBNetPrimes (ngen'd) | 1000000 | 20,007,201,165 | 19,900,407,405 |
| MCPPPrimes1 | 1000000 | 19,363,699,234 | 19,346,647,324 |
| MCPPPrimes1 (ngen'd) | 1000000 | 19,339,817,493 | 19,317,645,432 |
| MCPPPrimes2 | 1000000 | 19,450,368,014 | 19,325,875,844 |
| MCPPPrimes2 (ngen'd) | 1000000 | 19,345,122,911 | 19,429,232,591 |
Both Rama and Nish were pleasantly surprised to find that as we went to
higher and higher numbers for prime number generation, the stark contrasts in
performance started paling very noticeably till finally at the one million mark,
they all showed very similar performance. Again the ngen'd fully managed
MC++ DLL was the best and the VB.NET DLL was the worst. What was most curious
was that ngen'ing actually had a negative impact on the VB.NET DLL. And here is
a graphical representation.

Here is another graph that shows the impact ngen has on managed assemblies
You'll notice that ngen has maximum impact on VB.NET programs and as you'd
guess least impact on MC++ code that has native code blocks. You'll also notice
that the impact of ngen seems to decrease as we generate a higher number of
primes. This is made very clear in the following graph
So far we have only seen cases where the methods were called once. Thus the
managed versions suffered because of JIT compiling overheads. So we did multiple
calls to try and see if the managed versions got any faster after the first
call. So we looped the calls thrice. Here are some sample test results. Don't be
surprised by the difference in results with the tables above. The first set of
tests were run on a Dual P-III 550 MHz with 384 Mb RAM. So numbers are higher
for the first set of results because the performance counter frequency is quite
high for a dual processor machine. The multiple-method-call tests were all run
on Single P-III 800 MHz with 384 Mb RAM. Obviously the performance frequency is
lower and thus the numbers are also smaller. But you'll notice that the ratios
remain more or less the same.
| Language | Primes | Native Callee
#1, #2 & #3 | Managed Callee
#1, #2 & #3 |
| CSharpPrimes | 10 | 5973 | 35 | 25 | 4848 | 56 | 46 |
| CSharpPrimes (ngen'd) | 10 | 476 | 32 | 276 | 95 | 60 | 45 |
| VBNetPrimes | 10 | 7663 | 38 | 29 | 8144 | 59 | 50 |
| VBNetPrimes (ngen'd) | 10 | 489 | 35 | 29 | 101 | 63 | 51 |
| MCPPPrimes1 | 10 | 6270 | 34 | 26 | 5383 | 57 | 46 |
| MCPPPrimes1 (ngen'd) | 10 | 499 | 31 | 24 | 127 | 56 | 46 |
| MCPPPrimes2 | 10 | 4466 | 38 | 25 | 3646 | 61 | 47 |
| MCPPPrimes2 (ngen'd) | 10 | 624 | 31 | 25 | 247 | 65 | 47 |
You'd notice that there is a amazing increase in performance for the 2nd call
and further calls. The most noticeable performance improvement is for the non-ngen'd DLLs.
The ngen'd C# DLL shows a slight anomaly for it's 3rd run, but this might have
been due to some OS activity coinciding with that exact moment. It's nothing but
an anomaly, so you may safely ignore it. Thus, whether you ngen it or not, from
the 2nd run onwards your methods will be nearly as fast as native calls, because
there is no JIT overhead. But it will not be as fast obviously because of other
overheads like garbage collection. You'll also notice that the 3rd call has
actually improved over the 2nd call, but this improvement across calls drops
sharply as we increase the call loop count. Now let's take the results for a
larger number of primes.
| Language | Primes | Native Callee
#1, #2 & #3 | Managed Callee
#1, #2 & #3 |
| CSharpPrimes | 10000 | 165346 | 162135 | 158838 | 159857 | 157004 | 156279 |
| CSharpPrimes (ngen'd) | 10000 | 155593 | 154611 | 156586 | 157266 | 156629 | 154440 |
| VBNetPrimes | 10000 | 180720 | 172494 | 173198 | 175535 | 171634 | 170705 |
| VBNetPrimes (ngen'd) | 10000 | 172432 | 173577 | 172076 | 173416 | 175305 | 173921 |
| MCPPPrimes1 | 10000 | 165775 | 159783 | 160712 | 161040 | 158640 | 157350 |
| MCPPPrimes1 (ngen'd) | 10000 | 155954 | 164162 | 159695 | 155283 | 159554 | 155928 |
| MCPPPrimes2 | 10000 | 160007 | 154570 | 154990 | 171823 | 158746 | 156686 |
| MCPPPrimes2 (ngen'd) | 10000 | 156243 | 153972 | 154144 | 154966 | 157720 | 167443 |
Ah, now the performance improvements of ngen are not as obvious. This again
confirms the fact that over the long run, the bottlenecks of JIT fades off
slowly and finally just about disappears.
Some conclusions
- Using ngen has a tremendous performance improvement on your managed code.
This is specifically higher when called from a managed client than when
invoked from a native C++ client.
- Managed/Unmanaged transitions are inefficient. And the unmanaged to managed transitions
are much slower than the managed to unmanaged transitions. Thus wherever
possible it's best to avoid managed/unmanaged transitions.
- There is a marked improvement in performance of managed code if they are
repeatedly invoked, because the JITing is done only the first time.
- As we increase the number of primes the performance differences between
the various languages starts to reduce, which again underlines the fact that
without the JIT overhead managed code is just as good as native code.
- Of all the .NET compilers, the VB.NET compiler seems to produce the
slowest code. We think this is because VB.NET checks for overflows in all
arithmetic operations (verified using ILDasm)
- The C# compiler seems to be markedly better than the MC++ compiler (pure
managed code).
- Using ngen has most impact on VB.NET assemblies and least impact on MC++
assemblies
- Mixing unmanaged and managed code with C++ is far more efficient than pure
MC++. In fact pure MC++ is much slower than C# for fully managed projects. Thus unless you plan to
integrate MFC or ATL, C# is the better choice over MC++.
Updates and fixes
- Aug 10 2002 - A major goof-up was fixed. In the looped method tests, we
had looped at the wrong place. Instead of looping the method we actually
looped the execution of the client process. This has been fixed, and the
tables and the excel sheets have been updated.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






 , Keep Smiling.
, Keep Smiling.


 :
: )
)