Introduction
g2log was made to be a simple, efficient, and easy to understand asynchronous logger.
The core of g2log is only a few, short files and it should be easy to
modify to suit your needs. It comes with logging, design-by-contract
CHECK macros, and catching and logging of fatal signals such as SIGSEGV
(illegal memory access) and SIGFPE (floating point error) and more. It
is cross-platform, tested on both Linux and Windows.
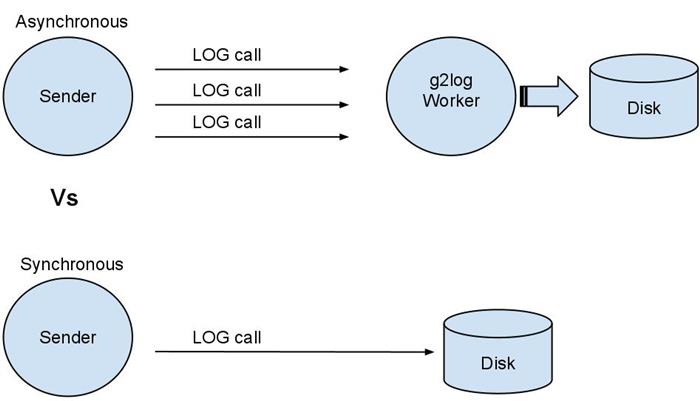
What separates g2log from other logger utilities is that it is asynchronous. By using the Active Object pattern g2log does the slow disk access in the background. LOG calls are asynchronous and thereby g2log gets improved application performance.
A comparison with the pseudo asynchronous Google glog (v.0.3.1) shows that g2log is much more efficient, especially in a worst case scenario.
I have split this presentation in two parts
- #[Part 1] G2log asynchronous logging
explains how g2log works. A brief introduction to the API for making
LOG calls and some of its internals. This is the part you should read if
you are a developer who is curious about it and how it works. The code
examples are kept brief but the few, short, files are easily browsed at
g2log/src found at https://bitbucket.org/KjellKod/g2log/src
- #[Part 2] Performance: g2log vs Google's glog shows how a very effective, pseudo asynchronous, but still synchronous logging utility (Google's glog) compares to an asynchronous logger (g2log). The performance section shows that the asynchronous
g2log is much more efficient, especially in a worst case scenario. This
section can be read standalone for anyone who is interested in g2log's
performance.
g2log is made with code techniques and building blocks suggested by many great software gurus. I have just connected the dots. There are probably other free asynchronous loggers
out there, but at the time of this writing, I have not yet encountered
one. That is why I am sharing this code with you. My contribution to the
community and thanks for all the great help I have received in person,
from articles and blogs. Of course, with this in mind, it just makes
sense to make g2log free as a public domain dedication.
A version of this article was originally published at www.kjellkod.cc.
Contents
- Introduction
- [Part 1] g2log: Asynchronous logging
- 1 Introducing g2log
- 2 Why the synchronous logger is traditionally preferred to the asynchronous
- 2.1 How g2log satisfies the crashing requirement
- 3 Using g2log
- 3.1 Initialization
- 3.2 Flush at shutdown
- 3.3 Logging levels
- 3.3.1 Logging levels example
- 3.4 Conditional logging
- 3.5 Streaming API
- 3.6 Printf-like API
- 3.7 Design by contract (a.k.a. assertion programming)
- 4 Influences
- 5 Requirements
- 6 The code
- 7 Why and what-if
- [Part 2] Performance: g2log vs. Google's glog
- 8 Introduction: Performance comparison
- 8.1 The actual LOG call
- 9 Rationale for the comparison
- 10 Facts and numbers
- 11 Simplified description of Pseudo Asynchronous
- 12 Performance comparison
- 12.1 Average LOG call times
- 12.2 Average LOG call times with congestion
- 12.3 Maximum LOG call times
- 12.4 The complete picture
- 13 Background thread: Total times - improvement
- Conclusions
- 14 Performance conclusion
- 15 g2log summary and reflections
- References
- History of changes
[Part 1] g2Log: asynchronous logging
Introducing g2log
g2log is an asynchronous logging utility made to be efficient and easy to use, understand, and modify. The reason for creating g2log was simply that other logging software I researched were not good enough API-wise or efficiency-wise.
API-wise I was just not happy with the calls to some of the logging utilities I tried. They were too verbose and made the code look cluttered.
Efficiency-wise, I am of the firm belief that whenever there is a slow file/disk/network access, it should be tried to the utmost to process this in a background thread. I got disappointed with all the logging software I tried, as they were serial (synchronous), i.e., a LOG call was written to file before the log caller could continue, which obviously slows down the log caller. There are good, traditional, [#reasons] for using a synchronous logger but I believe g2log satisfies those reasons while still being asynchronous.
Being responsive is a key requirement in the software I work with. Slowing down a thread because it is doing a LOG call is not good enough. Thus I decided to create the asynchronous g2log.
For those who are interested, and not for flaming reasons, the loggers I looked into and found lacking were: Google's glog, ezlogger, and log4Cplus.
To get the essence of g2log it is only needed to read a few highlights:
- All the slow I/O disk access is done in a background thread. This ensures that the other parts of the software can immediately continue with their work after making a log entry.
- g2log provides logging, Design-by-Contract [#CHECK], and flush of log to file at shutdown.
- It is thread safe, so using it from multiple threads is completely fine.
- It catches SIGSEGV and other fatal signals (not SIGINT) and logs them before exiting.
- It is cross platform. For now, tested on Windows7 (VS2010) and ubuntu 11.10 (gcc 4.6). There is a small difference between the Linux and the Windows version. On Linux a caught
fatal signal will generate a stack dump to the log. This is not available on Windows due to Windows complexity when traversing the stack. - g2log is used in commercial products as well as hobby projects since early 2011.
- The code is given for free as public domain. This gives the option to change, use, and do whatever with it, no strings attached.
There you have it, g2log in essence.
A side point: g2 was a keyword in the first commercial project that used g2log. It stands for second generation (g2), thus the naming was easy. It is just a happy coincidence that one of the inspirations to g2log's API was called glog.
Why the synchronous logger is traditionally preferred to the asynchronous
A logger requirement is often to have the log entry on file, on disk, before the software would continue with the next logical code instruction. Traditionally, that meant only using a synchronous logger since it seemingly guaranteed that it would write straight to a file.
The demand that a made log entry is on file before continuing is common when debugging a crashing application. From now on, we call this the crashing requirement.
To the developer, it is vital to know that all the information is caught in the log before taking the next, potentially fatal, step. The downside to this is that the synchronous, slow, logging will penalize performance.
How g2log satisfies the crashing requirement
The crashing handling requirement was addressed by using a signal handler. You can see this at https://bitbucket.org/KjellKod/g2log/src please browse to g2log/src/ and see crashhandler.h and OS specific crashhandler_win.cpp or crashhandler_unix.cpp.
The signal handler will catch common OS or C-library triggered fatal signals that would kill the application. When catching a fatal signal, g2log sends the background worker a message telling it to handle a fatal event. The calling thread then sleeps until the background worker is finished. Meanwhile, the background worker is processing the messages in FIFO order.
When the background worker receives the (FIFO queued) fatal-event-message, it writes it to file and then continues to kill the application with the original signal. This way all the FIFO queued log messages that came before the fatal-event-message will be written to file before the crash is finished.
For the crashing requirement, when the application is killed with a fatal signal, g2log is still to be preferred to a synchronous logger. Performance will be good while still managing to handle flushing all written logs to file.
Using g2log
g2log uses level-specific logging. This is done without slowing down the log-calling part of the software. Thanks to the concept of active object g2log gets asynchronous logging - the actual logging work with slow disk I/O access is done in a background thread.
Compared to other logging utilities that does the I/O in the calling thread, the logging performance gain can be huge with g2log. This is shown below in the [#Performance comparison] page where I compare the mostly awesome Google glog library to g2log. Google's glog is what I call pseudo asynchronous since it can fake asynchronous behavior while it is really a synchronous logger. What is apparent is that the average time is up to 48% better with g2log. In the worst case scenarios, g2log is a factor 10-35 times faster than glog.
g2log provides both stream syntax and printf-like syntax according to your preference. The streaming API is very similar to other logging utilities and libraries so you should feel right at home when using it.
Initialization
A typical scenario for using g2log would be as shown below. Immediately at start up, in the main function body, g2logWorker is initialized with the prefix of the log and the path to the log file. A good rule is to use argv[0] as the log file prefix since that would be the name of the software that is starting up.
#include "g2log.h"
int main(int argc, char** argv)
{
g2logWorker g2log(argv[0], "/tmp/whatever-directory-path-you-want/");
g2::initializeLogging(&g2log);
The example program g2log-example would generate a log file at /tmp/ according to the rule prefix.g2log.YYYYMMDD-HHMMSS.log, i.e. something like g2log-example.g2log.20111114-092342.log.
Flush at shutdown
At closing of the application software, g2logWorker will go out of scope. This will trigger the destruction of the active object that g2logWorker is using. Before the active object is destroyed, any pending log writes are flushed to the log file. That way, no log entries will be lost.
Active::~Active() {
Callback quit_token = std::bind(&Active::doDone, this);
send(quit_token);
thd_.join();
}
Logging levels
The available logging levels are: INFO, DEBUG, WARNING, FATAL. These levels are fixed in the software but can easily be changed if needed. The levels can be added or removed easily from the very first lines of g2log/src/g2log.h.
By using the C preprocessor macro for token concatenation, the level itself is used to call the appropriate function.
#define LOG(level) G2_LOG_##level.messageStream()
Typos, or using log levels that do not exist, will give compiler errors.
LOG(UNKNOWN_LEVEL) << "This log attempt will cause a compiler error";
The compiler error will express something like:
>> ...
>> 'G2_LOG_UNKNOWN_LEVEL' was not declared in this scope
>> ...
For a log level that does not exist, or is spelled incorrectly, the concatenation will end up in a call to a non-existent function. This will then generate the compilation error.
Thanks to this safe use of a C preprocessor macro, the API is clean and direct.
Logging levels example
FATALFATAL
#include "g2log.h"
int main(int argc, char** argv)
{
g2logWorker g2log(argv[0], "/tmp/whatever-directory-path-you-want/");
g2::initializeLogging(&g2log);
LOG(INFO) << "Simple to use with streaming syntax, easy as ABC or " << 123;
LOGF(WARNING, "Printf-style syntax is also %s", "available");
LOGF(FATAL, "This %s is FATAL. After log flush -> Abort()", "message");
LOG(FATAL) << "This message is FATAL. After log flush -> Abort()";
}
Conditional logging
Conditional logging is provided. Conditional logging is handy when making a log entry under a certain condition.
LOG_IF(INFO, (1 < 2)) << "If " << 1 << "<" << 2 << " : this text will be logged"; LOGF_IF(INFO, (1<2), "if %d<%d : then this text will be logged", 1,2);
Of course, conditional logging can be used together with the FATAL log level instead of using [#CHECK]. If the condition does not evaluate to true, then the FATAL level and the message is ignored.
LOG_IF(FATAL, (2>3)) << "This message is not FATAL";
LOG_IF(FATAL, (2<3)) << "This message is FATAL";
Streaming API
The streaming API uses a normal C++ std::ostringstream to make it easy to stream strings, native types (int, floats, etc). The streaming API does not suffer from the format risks that printf-type APIs have.
LOG(DEBUG) << "Hello I have " << 1 << " car";
LOG(INFO) << "PI is: " << std::setprecision(6) << PI;
printf-like API
For the first release of g2log, I was persuaded to add printf-like syntax to g2log. This was implemented as a variadic function and comes with the usual risks associated with printf-like functions. At least printf-like logging is buffer overflow protected, thanks to vsnprintf.
printf-like API is still appealing to some mainly because of the nice text and data separation. I hope to move to variadic templates when they are supported on Windows.
If deciding to use a printf-like API, the calls will be somewhat different. The API calls are changed to: LOGF, the conditional LOGF_IF, and the Design-by-Contract CHECKF.
LOGF(DEBUG, "This API is popular with some %s", "programmers");
LOGF_IF(DEBUG, (1 != 2), "if true, then this %s will be logged", "message");
CHECKF(foo(), "if 'false == foo()' then the %s is broken: FATAL), "contract");
The risks with a printf-like API can be mitigated on Linux. Compiler warnings for erroneous syntax can be generated by using the -Wall compiler flag.
const std::string logging = "logging";
LOGF(DEBUG, "Printf-type %s is the number 1 for many %s", logging.c_str());
The log call above is badly formatted. It has two %s, but only one string argument. With the gcc compiler and flag -Wall enabled, the compiler would generate a warning similar to: warning: format "%s" expects a matching "char*" argument [-Wformat].
To be on the safe side, I personally prefer to use the stream API, both on Linux and Windows.
Design by contract (a.k.a. assertion programming)
It is common programming practice to have early error detection through assert. Conditions in the code are checked and the application is aborted if the conditions are not fulfilled. This is an important part of Design-by-Contract and is sometimes called assertion programming.
Most common is to use various CHECK macros to verify the condition and to quit the application if CHECK(condition) fails. g2log provides CHECK functionality for both streaming and printf-like APIs.
CHECK(1 != 2); CHECK(1 > 2) << "CHECK(false) will trigger a FATAL message, put it on log, then exit";
Or with printf-like syntax:
const std::string arg = "CHECKF";
CHECKF(1 > 2, "This is a test to see if %s works", arg.c_str());
Influences
g2log's streaming API as well as the macro concatenation for creating a log API with compiler check for log levels can be found in other logging utilities. Similar logging usage can be found in Petru Marginean's Dr. Dobbs logging articles [4] and [5] and Google's glog [6].
If you have read my previous blogs or already browsed through g2log's code, then it should come as no surprise that g2log was influenced and inspired by:
- Petru's articles, as a start influence. As always, he has inspirational articles that makes you want to explore [4] and [5].
- Google's glog [6] is an awesome logging library, maybe even one of the best in the world. If it wasn't for glog's lack of asynchronous logging, then g2log probably would never have existed.
- The effective concurrency blogs by Herb Sutter.
- Last, but not least, Anthony Williams C++ Concurrency in Action e-book [16] and blogs [17] a, that made me want to do something in C++11. Pronto.
Requirements
Version 1.0 of g2log is released with this article. Building it requires either C++11 compliant compiler or the just::thread's implementation of std::thread and CMake. On Linux, I have used gcc4.6, on Windows I have used Visual Studio 2010 Express and Visual Studio 11 (beta).
For windows users you can use g2log as is without just::thread starting with Visual Studio 11 as that comes with C++11 std::thread.
For Linux users the best bet is (at this moment) to use just::thread's implementation of std::thread. The gcc4.7 comes with std::thread and a reader has contacted me after successfully setting up gcc4.7 and using g2log with it. His preliminary testing says that it works but was a pain to set up (gcc).
If you do not have gcc 4.7 and do not plan to buy just::thread's
std::thread implementation and still want to use this logging utility, then you are still not in a rut.
std::thread can easily be exchanged for whatever threading library (Qt, MFC, boost, pthread) that you use on your platform. The necessary code changes you need to address are then mostly in
src/shared_queue.h and
src/active.h/.cpp.
The thread part of g2log is encapsuled within an active object. I have previously done similar active objects with QThread, pthread and more. If you do not have access to std::thread then maybe these could help. The code is available at https://github.com/KjellKod/active-object.
The code
I have put up a BitBucket repository for g2log. You can access the files there: https://bitbucket.org/KjellKod/g2log/src. You can do the mercurial download using the command hg clone https://bitbucket.org/KjellKod/g2log. Another option is to use the, possibly old, snapshot that should be attached with this article.
If you have any suggestions for improvements or notice something that should be corrected, then please tell me and I will do my best to incorporate it with the rest of the code.
Why and what-if
- Why is g2log using the antique C-inherited
varargs instead of variadic templates?.
Variadic templates should of course be used, in time. I'm only waiting for it to be supported on Visual Studio. At the time of this writing, it is not and I wanted it to be as similar on Linux as on Windows.
- Why is not g2log using this or that boost library?
I wanted g2log to be a small, contained utility that did not use too many external libraries apart from those that belonged to the C++11 standard. just::thread's std::thread library is a C++11 library implementation. std::thread is already now available in the currently beta/experimental gcc 4.7.
- Sometimes you wrote Linux and Windows but did you not mean Visual Studio 2010 on Windows and gcc 4.6 on Linux?.
Yes, of course. It was easier to simplify it like that. It is of course possible to use gcc on Windows as well.
- Why can levels not be disabled/enabled at runtime?
On a request from a reader I created a g2log fork at BitBucket to do just that. This might be incorporated later into the main g2log but you are of course welcome to use it already now. You can find it at: https://bitbucket.org/KjellKod/g2log-dynamic-levels
- Why is the
shared_queue wrapping a std::queue and not a std::deque? Isn't std:deque faster?
It makes sense in regard to that the std::queue is FIFO and shared_queue is used by the Active Object in a strict FIFO order. I have tested the performance difference and for the tests that I have run with std::deque (2 million logs by 2 threads), std::vector proved to be slightly faster for both average and the worst case scenario.
On stress tests involving higher data loads to the queue, it could be that std::deque would be faster, I just have not tested it and I stick with std::queue for now. The change is easy to make if needed, only a couple of lines in shared_queue.h.
- What guarantees can you give if my software creates more log entries than g2log can manage to save to my very, very slow disk?
Well. None. How's that? If your software over-schedules LOG calls log so much that the background g2log worker cannot possibly keep up, then the following will happen:
1 Your application software will continue to run and push logs pretty fast onto the message queue. It will still be responsive. If you use a synchronous logger instead, it would not be so responsive but be stalled for the larger portions of its execution time.
2 The shared message queue would continue to grow, consuming more and more RAM. In the end, if the log over-scheduling continues, bad things would happen as all of the RAM would not be enough.
In short: if the use of a logger is completely nuts, then nutty things will happen. If using an asynchronous logger, then the software would still be responsive for some time. If you use a synchronous logger, you would be mostly stalled. In both cases, your hard drive could fill up. Depending on your system, the out-of-disk scenario is more likely than out of RAM. At least on my laptop that is what happened during some of the [#extreme performance testing].
[Part 2] Performance: g2log vs. Google's glog
In the performance sections below, I compare g2log against a [#pseudo asynchronous] logger: Google's glog version 0.3.1. If this is not so important to you I suggest you just skim it or go straight away to the [#Conclusions].
Introduction: Performance comparison
glog is a good candidate for comparison since it is very fast on the average, maybe even the fastest synchronous logger due to its pseudo asynchronous behavior. Even though glog is very effective, it is outperformed by g2log both for the average case and for the worst case scenario.
The purpose of this performance comparison is in no way meant to discredit Google's glog. Quite the contrary. I believe that Google's glog is an amazing piece of software and it provides a lot more functionality than g2log probably ever will. The purpose of this performance comparison is instead to test g2log against a very good synchronous logger. Through this comparison, I hope that the performance differences and why they differ will be obvious. I hope also that it will be clear when an asynchronous logger truly is preferable.
The actual LOG call
Since g2log uses both printf and stream-like APIs but their performances are similar, I show only tests using exactly the same streaming LOG call for g2log as for glog.
LOG(INFO) << title << " iteration #" << count << " "
<< charptrmsg << strmsg << " and a float: " << std::setprecision(6) << pi_f;
Rationale for the comparison
On Google glog's forum, I noticed that requests for an asynchronous glog was met with silence. It was partly because of this I decided to make g2log.
Much later, I got contacted by a software engineer who had noticed my asynchronous feature request on the forum. He was also frustrated with glog's (quote) "poor performance" and naturally interested in the asynchronous g2log. I do not know if he is using g2log today or not, but thanks to his expressed need for improved performance, I decided to include this performance comparison.
Facts and numbers
All the data used here can be viewed in an online spreadsheet. The performance tests are easily reproducible since they come with the g2log code. I have also attached a copy of the performance measurements logs in case someone would like to have access to it.
The tests were made on a Dell Latitude E6500 laptop, Intel Core2 Duo CPU P8600 2.40GHz x2, with a solid state drive. On another system using a standard harddrive, the difference between synchronous (glog) and asynchronous (g2log) would be larger.
Simplified description of pseudo asynchronous
The key to the pseudo asynchronous performance is that glog buffers log entries. Every buffered LOG call is very fast since slow disk access is avoided. At certain triggers, or when the buffer is full, a flush-to-disk operation is performed. This results in that the latest log entry is penalized by the disk I/O access time for many previous entries.
The buffer-then-flush method gives a better average performance than a truly synchronous logger. However, every now and then, performance will be hit as all of the log entries are written to file at once.
Performance comparison
As previously stated, g2log manages disk access I/O in the background. This means that the call to make a log entry will result in a string that is asynchronously forwarded to a background worker. The worker is in due time saving the text to file.
Apart from that g2log is asynchronous, no real optimization has been made. This can be shown below where the average times sometimes do not differ too much between the two logger utilities. In the worst case scenario, when I/O wait times peak, that's when glog suffers and g2log shines.
Average LOG call times
For the average case, it is not always a big difference between the two. The pseudo asynchronous behavior gives glog good results for a test run of 1 thread creating 1 million log entries. The numbers used below can be viewed at the online performance chart tab "Tab for 1 million entries".
Average Application time per call [us]: 1 thread creates 1 million log entries
| g2log | glog | g2log % better than glog |
| 9.56 | 11.113 | 13.97% |

Average LOG call times with congestion
It is apparent that the total time (ref: the online spreadsheet) is more than the time spent for glog. The total time is the time from when the LOG calls started to when all the LOG calls are on file.
This is as it should be: g2log does not buffer log entries, not even if writing several log entries at once, instead the background thread writes them to file as soon as a log entry is available. This is an area where the background thread on g2log is not optimized. However, it is also of less importance - the important time to keep low is the application time. It is the application wait time for a LOG call to be finished that will slow down the LOG caller.
When adding contention, the average times for Google's glog worsens. Every now and then, the threads will have to wait a long time when the thread-safe buffer is emptied and written down to file.
Average application time per call, in microseconds [us], 4 threads, each creating 1 million log entries
| g2log [us], | glog [us], | g2log % better than glog |
| 6.52 | 12.45 | 47.63% |
Clearly, g2log outperforms even a pseudo asynchronous logger on the average as soon as there is congestion. The slow I/O is definitely penalizing the software if not done in the background.
Maximum LOG call times
With thread switching, mutex overhead, etc., there will of course be some peak wait times for g2log. Using a test setup with different number of threads, it is clear how these peak times increase with the data load. Compared to glog, the peak times for g2log pales in comparison. g2log's peak times are in the range of 10 - 35 times less than glog's peak times [online spreadsheet tab: maximum times].
How maximum and peak times, in milliseconds [ms], increase with the number of threads. Each thread is writing 1 million log entries.
| threads | g2log [ms], | glog [ms], | g2log factor better than glog |
| 1 | 13 | 459 | 35.31 |
| 2 | 28 | 920 | 32.86 |
| 4 | 42 | 925 | 22.02 |
| 8 | 66 | 914 | 13.85 |
| 16 | 113 | 1065 | 9.42 |
The complete picture
To really show how the peak times can hit performance, a scatter chart is used below. Maybe this graph is a good wake-up call for synchronous log users? [Online spreadsheet tab: complete picture comparison]
Below is the same data shown but in an area chart. The red noise in the end are the peak times. Although it might look insignificant, they represent a significant part of the total time consumption.
Background thread: total times - improvement
What is not shown here, but available in the online spreadsheet, are the total times for the background logger. With the current implementation, the g2log background thread writes log entries to disk as soon as one is available. This is of course not efficient, since every new disk access operation is slow.
This can be optimized if, for some reason, the total disk I/O time must be decreased for the background thread. An easy optimization would be to use the glog's scheme, but on the background thread's side. By buffering log entries in the background, and flushing it on triggers (time, or buffer full), the total disk I/O time would be significantly decreased.
Conclusions
Performance conclusion
It is obvious that KjellKod's g2log is faster than Google's glog, both when measuring the average times and when measuring the worst cases. This has more to do with the fact that glog is (partly) synchronous in nature while g2log is asynchronous. In the average case, Kjellkod's g2log is 10-48% faster than Google's glog. In the worst case scenarios, g2log is a factor 10-35 times faster than glog.
The pseudo asynchronous glog is much more efficient than a traditional synchronous logger. However, the peak times are alarming and discouraging.
The tests were made on a laptop with a solid state drive. On another system using a standard hard drive, with even slower disk access, the difference between synchronous (glog) and asynchronous (g2log) would be considerable.
The implication of using a synchronous logger is that sometimes the I/O wait times will be long. Using a synchronous logger can halt the log calling thread for a very long time. This is usually not desired since being responsive is a normal software design goal.
G2log's average time is less than glog's average time. In the worst case scenario, the asynchronous g2log has a tremendous advantage over the synchronous glog.
g2log summary and reflections
I can only speculate why the public versions of Google's glog, ezlogger, and log4Cplus are not made with true asynchronous logging. It is the traditional approach to a logger, but if you think about it, it is almost silly not having the slow disk access operations done in the background. This is clearly shown in the performance comparison section above.
It does seem that Google's glog might indeed be asynchronous when used internally at Google. This according to the glog owner, Shinichi's comment at the glog forum google-glog/issues/detail?id=55.
A probable reason not already discussed could be that these loggers were made pre C++11 (std::thread was not available and maybe it was too much effort to make them threaded cross-platform). Another probable reason could be that the authors behind these loggers chose to not tie their logger too tightly with third party threading libraries such as MFC, Qt, or Boost.
Either way, C++11 is already here. g2log is free. Use it with std::thread through the just::thread implementation or an C++11/std::thread compliant compiler (Visual Studio 11). Alternatively, you can simply replace the encapsulated threaded part, inside the active object, for a thread library of your choice. What are you waiting for? Go get it :)
Thank your for reading my article. I hope you can use g2log as is, parts of it or just be inspired to something else.
References
- Kjellkod blog: Candy for programmers
- Kjellkod blog: Design by Contract & why not also a Quick and Dirty Logger?!
- KjellKod.cc: Active Object the C++11 way
- Dr.Dobbs, article by Petru Marginean: Logging In C++
- Dr.Dobbs, article by Petru Marginean: Logging In C++: Part 2
- Google's glog logging library
- Various Q&A at StackOverflow regarding streaming, logging. Too many to enumerate.
- Wikipedia: Uncontrolled format string
- gcc.gnu.org Standard Predefined Macros
- gcc.gnu.org Function Names as Strings
- cppreference.com printf format
- unixwiz.net __attribute__
- codemaestro.com Variadic arguments in C/C++
- Herb Sutter Effective Concurrency: Prefer Using Active Objects Instead of Naked Threads
- C++11 std::thread implementation from just::thread (by Anthony Williams)
- Anthony Williams book: C++ Concurrency in Action
- Anthony Williams blog: Thread safe queue using condition variables
- Wikipedia, type of Design-by-Contract: Assertion (computing)
- Apache listing of C++11 compiler support
- StackOverflow, gcc stackdump
- gcc.gnu.org symbol demangling
- Suavcommunity, signal handling porting Unix/Windows
- IBM Windows/Unix signal handling
- Tutorialpoints C++ Signal handling
- TinyMicros Linux overflow signal handler example
History of changes
- 11/22/2011: Initial CodeProject version. g2log is v.1.0.
- 03/12/2011: Minor changes: corrected formatting of text and pictures. Clarified selected parts of the text
- 07/12/2011: Article overview, added zip download, updated formatting + added an introduction picture
- 08/12/2011: Updated the content overview, small text changes and grammar correction.
- 04/03/2012 - 05/03/2012: Just::thread no longer necessary on Windows thanks to Visual Studio 11. Updated source code, BitBucket and rollbacked to correct broken TOCs.
Enjoying Colorado! Family and intense software development.
Kjell is a driven developer with a passion for software development. His focus is on coding, boosting software development, improving development efficiency and turning bad projects into good projects.
Kjell was twice national champion in WUKO and semi-contact Karate and now he focuses his kime towards software engineering, everyday challenges and moose hunting while not being (almost constantly) amazed by his daughter and sons.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 








