Introduction
A common situation is to prepare invoices, etc. from information in a database. Clients usually have extremely customized invoice formats, but the data to be filled in is basically the same. This article and its related code present a new (I have searched, but could not find anything related to this topic, so I believe it's new), innovative, and productive way of producing dynamic Office documents. I am using the word Office in this entire document as it does not relate solely to Microsoft Office. I have tested this approach on Open Office as well, and it works. The associated code enables to perform Token Replacement on both Office products.
Background
Until now, I was creating HTML on the fly, and making it available for download as a *.doc or *.xls file, exploiting Office application capabilities for processing HTML documents. But, there was a limit this approach would go to. There were obvious limitations in precise positioning in HTML and how Office applications interpret and display that. Not to mention the advanced processing capabilities of Office documents that are missing while generating dynamic HTML.
A new approach had been swirling around my mind since the time Office products embraced XML formats. We, developers, have been using token replacement for a long time for producing dynamic content. How about doing it with Office documents!!
So, I finally got a chance to implement this, when the document I had to produce exceeded HTML formatting capabilities. Now, I was trying to create a Word document, with tokens of the form [$TokenName$] in it, and replacing the tokens with actual text, programmatically. However, it was not as easy as I thought.
Word 2007 splits up tokens into multiple parts, depending upon regions to be checked for spellings. Ditto is the case with OO (OO refers to Open Office). These Office products might split up what you consider a single word into multiple runs (they use the word run) of text surrounded by their XML. That makes the scenario almost impossible. I tried to discuss my approach at Microsoft Forums and at Brian Jones' blog. However, I could not get any useful help.
So, I decided to take it up myself.
Some More Background
As I said, I would be talking of Office XML in general, not particularly related to Microsoft Office or Open Office. Consider one thing before moving forward, only Microsoft Office 2007 applications use a full XML document format. Office 2003 probably uses XML, but I have not studied the Office 2003 document format. Neither have I tested the code on Office 2003 documents.
Regarding OO, I downloaded it specifically for this project. The version was 2.4 at the time I downloaded it. So, it should work on it and later versions. However, you, as a developer, should not be worried. Read forward.
I evaluated several options before actually having to use this approach I am describing (you can say, I was not left with any other option). VSTO is Microsoft Office centric. Also, with the minimal knowledge I collected about VSTO (by asking questions on forums), I thought it would not help. Microsoft's Open XML SDK for Office was indeed a very attractive one. However, I was not in any way interested in the Open XML schemas used by Microsoft Office, and this product's documentation clearly stated that you need to have a good knowledge of the XML schemas to exploit this library.
Then, I ripped opened a Microsoft Office 2007 document (it is simply a zip file, just unzip it), and analyzed the contents. It was plain XML. And, I immediately decided to use the XML processing capabilities of .NET to process what it actually was, just plain-sane XML, not treating it as any special schema.
So, the attached code does not require anything special to be installed. You can use it easily on a Desktop application, as well as a Web application, with the only requirement of .NET 3.5 installed on the machine where the code is executing. Not even the associated Office product needs to be installed. I am treating it as pure XML, so there are no other requirements absolutely. Just prepare an Office document with your tokens in it, deploy the document with your code, and you are ready to scramble.
Now Comes the Code
It all starts with opening up an Office package (an Office file is now called an Office package technically, as it is not just a single file). A good starting point would be to open any Office document with your favorite Zip tool and analyze the contents.
I am using the SharpZipLib library for anything related to processing Zip files during this token replacement process. Once you open the Zip file, you would notice that there are multiple files. The main content file is "word/document.xml" for Microsoft Word 2007 and "content.xml" for OO Writer. As of now, the code can process only Word and Writer packages. I would add support for Excel and OO Calc as I get time. I acknowledge that the code attached is a bit immature at this time. Still, I am writing this article to discuss it with others so that you can adapt and enhance it for your scenario, if you find it useful. I am not sure when I would be able to make enhancements myself.
The overall code structure is divided into 4 components (as of the 3rd version of this library):
- Replacers - These denote sections of Office Documents (header, content, footer, etc.). Token Replacement can be performed on each section independently. These were added in the 2nd version of this library.
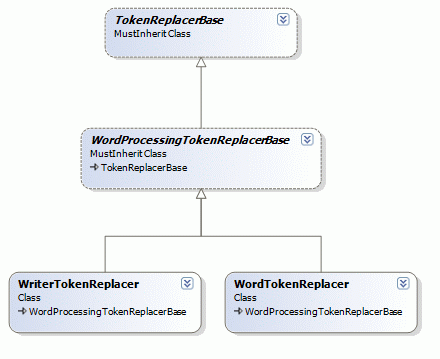
- Documents - These classes represent the Office Documents (.docx, etc.) themselves. Each document can choose to expose desired sections. e.g. Microsoft Word & OO Writer documents expose a header, content & footer section where each section has a replacer associated with it, that performs Token Replacement in that section. The following code snippet might help to clarify this:
doc.header.replaceToken("[$Date$]", DateTime.Today)
doc.content.replaceToken("[$Consignee$]", Loreium Ipsum)

- Interfaces - These interfaces are implemented by the Office Documents (explained below in the Add-In section).
- Helper classes - These classes provide utility functions to help in token replacements.
Straight away after opening up the Zip file, I read its contents into an XDocument (the code uses LINQ and LINQ to XML all over). Right now, the major regarding functionality actual Token Replacement is coming from the TokenReplacerBase class. This is the base class for all the Replacers for different sections of an Office document.
However, you as a user needs to have an instance of a concrete class of TokenizedDocumentBase. You get this instance by using static factory methods of the TokenizedDocumentProxy class. You specify the filename (with its path) to open, the token start, and the token end (both strings). This proxy class has been introduced in the 3rd version of this library again for reasons explained in the Add-In section below. An example code snippet should help:
Dim p As IWordProcessingTokenizedDocument = TokenizedDocumentProxy.getDocumentProcessor_
(Of IWordProcessingTokenizedDocument)( _
SupportedExtensions.docx, _
"ProcessedInvoice.docx", _
"[$", "$]", _
True)
OfficePackage is the helper class to enable reading and modification of the Office document packages. Formatter, MetadataProcessor, Currency etc. are other helper classes used for various purposes during Token Replacement.
Regex
The code relies heavily on the .NET System.Text.RegularExpressions for token replacement. You should be careful while choosing the token start and the token end. As of now, the characters in your token delimiters should not appear in your content. I have used "[$" and "$]" as the delimiters in the attached sample docx files.
Immediately after constructing an object of the appropriate Document class (by using the factory methods in TokenizedDocumentProxy), you can start calling the replaceToken() method (in a loop probably, to process all tokens), passing in your token (including the delimiters) and the replacement value. On the first call to this method, the code parses the entire content, looking for tokens, and stores a dictionary of matches found with the token as the key. After that, and on all subsequent calls, it just consults this dictionary to perform the substitution.
As an alternative, you can create a List (of TokenReplacementInfo) (a helper class in the project), and call replaceTokens(), passing in this List just once, and it performs all the substitutions.
XmlUtil is the helper class that helps in Office XML specific text matching and replacement.
Sample
Suppose you have the following token: [$Date$].
You can replace it with the call...
doc.content.replaceToken("[$Date$]", DateTime.Today)
... where t is an object of the concrete class for the package you are processing (Rahul.Office.MS.Word.WordTokenizedDocument or Rahul.Office.OO.Writer.WriterTokenizedDocument).
Fine Points
- The token replacement functionality is flexible. You can specify metadata in your token to control exactly how the token is replaced. E.g.:
- The token:
[$Date$<metadata><type>date
</type><format>dd.MM.yyyy</format></metadata>]
when replaced, would adhere to the date format you specified.
- As another one:
[$InvoiceTotalValue$<metadata><type>money
</type><format>text</format></metadata>]
would treat the replacement value as a monetary one, and automatically convert it to English (hundred thousand, five hundred six only, etc.).
- The last metadata supported right now is for normal text.
[$InvoiceTotalValue$<metadata>
<type>money</type><format>text</format>
<transform>upper</transform></metadata>
The transforms "upper" and "lower" converts the text to uppercase or lower-case, respectively. This can be applied to text as well as monetary values whose format is text.
Note that the metadata appears only in the Office document you have prepared. While making function calls, you still just call:
t.replaceToken("[$Date$]", DateTime.Today)
The code automatically determines if that token has any metadata attached in the document. The metadata tags can appear anywhere between your token.
- The same token can appear multiple times. The default behavior is to replace all occurrences of the same token with the replacement value specified as the first call to
replaceToken() with that token as the input. However, there is an overload of replaceToken() available, where you can specify the ith occurrence of the token to be replaced. Thus, the following call...
t.replaceToken("[$Date$]", DateTime.Today, 2)
... would replace only the second occurrence of the token [$Date$] in the original content. (There are some finer points related to ith occurrence replacement, which are documented properly in the code attached.)
The same token can occur multiple times with different metadata. And, each token occurrence would be replaced taking into consideration the metadata specified, if any, for that occurrence only.
- Another common situation in invoicing would be an invoice that can contain multiple products. But, you don't know how many when preparing the tokenized document at the development time. Not need to worry. Just prepare a sample row in a table. Leave a unique token in that row in any cell. Then, before calling
replaceToken(), call replicateRow(), passing in that unique token and the number of times the row is to be replicated. - All replacements are done in memory. When you are finished, remember to call the
save() function, as that replaces the content in the original Office package specified in the constructor.
Using the Code
Here are the precise steps for using the code:
- Prepare a Word or Writer document (not template) with tokens in it.
- Create a Console application. Add a reference to the attached Rahul.Office assembly
- Start replacing tokens. A sample code is presented below.
Sample
Here's all it takes to replace tokens:
Sub Main()
System.IO.File.Copy("TokenizedInvoice.docx", _
"ProcessedInvoice.docx", True)
Dim p As IWordProcessingTokenizedDocument = _
TokenizedDocumentProxy.getDocumentProcessor_
(Of IWordProcessingTokenizedDocument) _
(SupportedExtensions.docx, _
"ProcessedInvoice.docx", _
"[$", "$]", _
True)
Dim list As New List(Of TokenReplacementInfo)
list.Add(New TokenReplacementInfo("[$LCNo$]", "11111"))
list.Add(New TokenReplacementInfo("[$LCInvoiceNo$]", "22222"))
list.Add(New TokenReplacementInfo("[$LCInvoiceDate$]", DateTime.Today))
p.body.replicateRow("[$ReplicateRow$]", True, 2)
list.Add(New TokenReplacementInfo("[$LCGoodOrderName$]", _
"My neighbour's car", 0))
list.Add(New TokenReplacementInfo("[$LCGoodOrderBrand$]", _
"Bentley", 0))
list.Add(New TokenReplacementInfo("[$LCGoodOrderSpecification$]", _
"Black, with leather upholstery", 0))
list.Add(New TokenReplacementInfo("[$LCInvoiceTotalValue$]", 10010200))
list.Add(New TokenReplacementInfo("[$LCDeliveryType$]", "CNF"))
p.body.replaceTokens(list)
If (TypeOf (p) Is IWordProcessingTokenizedDocumentExtension) Then
Dim pext As IWordProcessingTokenizedDocumentExtension = _
CType(p, IWordProcessingTokenizedDocumentExtension)
pext.replaceTokenWithHtml("[$HtmlToken$]", _
"Html text that replaced a token")
End If
p.save()
End Sub
Advantages over Open XML SDK or Other Such Options
- You need to have a good understanding of Open XML schemas for using these SDKs.
- You are stuck with one particular product when using them.
- You need them installed on the target machine for use. Here, just drop the Rahul.Office assembly into the bin folder, or copy the code files to your project.
I am not trying to play down these SDKs. They are very powerful. But, I believe they are too powerful to be used in regular development, unless you have a good understanding of schemas.
3rd Version - Add-In Architecture Introduced
The second version of this library introduced support for Token Replacement in Header and Footer sections (see this comment) (But please, download the code attached with this article, not that comment, because that code is obsolete and the file has been removed from Rapidshare).
Some time after releasing the second version, I had an interesting scenario, where a client wanted to be able to replace a token with Html produced dynamically. As anyone would imagine, this was a considerably complex scenario because you simply cannot replace the Token with HTML markup. This would render the Office document corrupt, because HTML is not compatible with Office markup.
I needed to provide this functionality. It was simply not possible to provide a conversion from HTML to Office markup. This would have been way too complex and outside the scope of this library. Some Googling revealed the support of VSTO for such scenarios. However, remember VSTO is a Microsoft Office centric collection of libraries for enabling processing of Microsoft Office documents from .NET code. More importantly, VSTO requires a valid copy of Microsoft Office to be installed on the machine.
So, I refactored this library for Add-In architecture. The core support for Token Replacement together with all the features mentioned above come from the core Rahul.Office.dll assembly. However, this assembly itself tries to load Rahul.Office.MS.dll or Rahul.Office.OO.dll assemblies. These assemblies can provide extended support for Token Replacement for the corresponding Office product. However, if not found, the core assembly reverts to itself for the Token Replacement features it provides.
To support this refactoring, the TokenizedDocumentBase was refactored into a set of interfaces. The ITokenizedDocument interface provides methods that all Tokenized Documents should implement. IWordProcessingTokenizedDocument interface contains methods that all Word processors (Microsoft Word, OO Writer, etc.) should provide. Both these interfaces are implemented completely by classes inside the core Rahul.Office.dll assembly.
However, another interface IWordProcessingTokenizedDocumentExtension provides extension methods that Add-In assemblies might choose to implement. Currently, it provides a single method replaceTokenWithHtml, which is implemented by the Rahul.Office.MS.dll assembly for Microsoft Word Tokenized documents.
To support this architecture, a special TokenizedDocumentProxy class has been created, with static factory methods like:
getDocumentProcessor(ByVal extension As SupportedExtensions, _
ByVal documentPath As String, ByVal tokenStart As String, _
ByVal tokenEnd As String, ByVal lookForDedicatedAssemblies As Boolean) _
As ITokenizedDocument
Now if you pass
true as the last argument, it would look for the Add-In assemblies, before falling back to itself in case those are not found. In case, you pass
false as the last argument, the Add-In assemblies would not be looked for. I would strongly recommend passing
false, unless you need the additional features required by the Add-In assemblies.
Some points of caution:
- Pass
false if you don't require the extension features as Add-In assemblies are loaded dynamically through Reflection, which might impact performance. - The Add-In assemblies provide features for a specific Office product. Hence, they can provide non-standard implementations not available for the other Office products.
- The Add-In assemblies might have their own pre-requisites. e.g. If you choose to download the source Ccde with Add-Ins, you get Rahul.Office.MS.dll that provides Microsoft Office specific extensions. It provides these features using VSTO, which requires Microsoft Office to be installed on the matching before you can use it.
Thus, if you don't require the additional Add-In feature, you should download the source code without the Add-Ins. The only extension feature being provided by the Add-In currently is the ability to replace a Token with HTML formatted string.
Also, note that VSTO uses Interop extensively and is hence, considerably slow. - If you are using the Add-In assemblies, remember they are loaded by Reflection, and should reside in the same directory as the core Rahul.Office.dll assembly.
Still To Be Done
I needed to deliver the functionality quickly to a client, and assembled the original code quickly. Since then, I have made some enhancements to it, that I have updated in the article.
I am using lots of regex, and probably they can be tweaked to increase performance (although I have been able to Token Replace large documents in virtually no time). There are many more features or metadata extensions that could be added. Support for Excel and Calc, at least, is desired. More replacement options, the list would never end.
I will try to take time out and enhance this. But, right now, as it stands, the code should satisfy many requirements in a majority of the cases.
Also Available On My Blog
The source code for this article is also available on my blog, Token Replacement in Office documents. The article would always be kept updated together with its source code here on CodeProject. However, I have noticed it takes time for the article to be updated on CodeProject once I submit an updated version (this last version took in excess of 2 weeks to get updated). So, you can download the latest code from my blog post. Simultaneously, the updated code would always also be available here on CodeProject.
History
- 22nd December 2008: Initial post
- 22nd May, 2009: Article updated
- 11th November, 2009: Article updated
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





 Thank you so much for all your work and for sharing it with us!
Thank you so much for all your work and for sharing it with us!