Introduction
People sort mixed text and numbers differently than most computers seem to. For example, ask a computer to order the list “A1”, “A2”, and “A10”, and more than likely, you will get “A1”, “A10”, “A2”. Intuitively, we expect “2” to come before “10”, not after. Most sorts use lexical order, comparing text one character at a time. '2' comes after '1', hence, “2” follows “10”, lexically.
The question becomes, how do you get a more natural ordering?
Background
There are a few approaches to take. The simple one, which makes some assumption on the data to be ordered, assumes text contains only a number, or a string, but never both. Other approaches assume only one numeric portion, possibly at the front of the string. More advanced techniques create a custom comparer that checks two strings segment by segment, performing an ordering on numeric segments differently than ordering on non-numeric segments. This does require you be able to provide the sort algorithm or data with the comparison function.
The algorithm in this article uses a different approach. It assumes that you are stuck with lexical ordering. So, the technique now becomes one where you transform the original string to a new string with the property that, using a traditional lexical ordering, yields the natural order for the original untransformed strings.
First, I'll define a precise natural order that I can use to implement the conversion. A 'numeric' segment consists of a string having only characters '0', '1', '2', ... '9'. A 'non-numeric' segment has only characters other than '0', '1', '2', ... '9'. One can then decompose any string into a list of alternating numeric and non-numeric segments. For example, “C.10 CODE 2” decomposes to “C.”, “10”, “ CODE “, “2”, and “C.2 CODE 10” decomposes to “C.”, “2”, “ CODE “, “10”.
Using this decomposition, I define a simple natural order as: Compare the strings segment by segment. If both segments are numeric, treat them as integer representation when comparing, otherwise, use the typical lexical comparison on the segments. The first difference generates the final comparison result. For example, “C.10 CODE 2” and “C.2 CODE 10”, 2 < 10, giving “C.2 CODE 10” < “C.10 CODE 10”. Special care should be taken for numeric segments beginning with '0'. The numeric portion should still drive of the main comparison, but, if they compare equal, the longer zero padded one should follow the shorter. “01” orders to before “001”.
This leads to an implementation suggested by one of the approaches mentioned, defining a comparer. But, how can we transform “C.2 CODE 10” = C02 and “C.10 CODE 2” = C10 into new strings, such that they always lexically order to C02 < C10, using the same rules?
To solve this, note that numeric segments have a length on par with their order of magnitude (excluding left zero padding). We can solve the problem if we can code a magnitude that orders lexically, and prefix the number segment with it. If done this way, the lexical comparison will always compare numeric segments only for equal magnitude numbers, which indeed can be done character by character.
For this implementation, I assumed most numbers have fewer than 9 digits. The code transforms these numbers into a string with the magnitude as a single digit, followed by the number. For example:
- 4 has magnitude 10^0. Coding yields “0” + “4” = “04”.
- 12345 has magnitude 10^4. Coding yields “4” + “12345” = “412345”
I also assumed no one would ever need to order numeric segments longer than ~10^9 digits long. For numbers longer than 9 digits long, I prefix with '9', followed by the magnitude of the magnitude minus 9, followed by the magnitude minus 9, followed by the number -- These magnitudes will always be equal or greater than 9; subtracting 9 allows a shorter than average text string ("0" instead "9", "1" instead of "10", etc.) For example:
- 1234567890 has magnitude 10^9. 9-9 = 0 has magnitude 10^0. Coding yields “9” + “0” + “0” “1234567890”.
- A digit sequence 900 characters long has magnitude 10^899. 899-9 = 890 has magnitude 10^2. Coding yields “9” + “2” + “890” + [the 900 characters].
As mentioned, to order zero padded numbers correctly, the algorithm must append a count of left padded zero. I used the same method used to encode the magnitude, as zero padding. If the non-padded numbers are equal, and tack these to the end of the token. They only ever matter if ever number and non-numeric characters are equal.
This technique does have a drawback. It must process every character in every string, and produce another string. In contrast, a comparison technique may be able to return an ordering after comparing only the first character.
Implementing the Algorithm
When writing code, I find that implementing a unit test results in better code and maintainability. I implemented a unit test first, to verify the token sorts as expected (Normally, I would write an nUnit test, but until I install and configure it on my home system, a manual test will have to do). I've removed some of the more tedious aspects of the unit test from the code snippet, but give a basic idea on usage, as well as verify the token generator works.
public void TestOrder()
{
string[] testInput = new string[] { ... };
string[] expectedOrder = new string[] { ... };
List<string> sortedOrder = new List<string>(
from i in testInput
orderby i.GetAlphaNumericOrderToken()
select i );
}
Note the use of a LINQ query, and the method to get the token -- the GetAlphaNumericOrderToken() extension method.
Getting into the working code itself, in my StringExtensions class, the algorithm takes the form:
public static string GetAlphaNumericOrderToken
( this string s, bool includeHexPatterns, bool ignoreZeroPadding )
{
if( s == null )
{
return s;
}
Note that extension methods can be invoked, even when calling with a null object. The first lines handle this special case, mapping the null string to a null string token.
MatchCollection matches;
if( includeHexPatterns )
{
matches = integerAndHexRegex.Matches( s );
}
else
{
matches = integerRegex.Matches( s );
}
if( matches.Count == 0 )
{
return s;
}
I originally coded only to match integer sequences. A commenter noted some occasions call for ordering hex sequences as well. The regular expressions driving the two different modes differ only in including the hexadecimal pattern of "0x" followed by one or more hex symbols.
After checking for a special case where no embedded numbers were found, and some space management to generate some string builders into which the token will be written:
int pos = 0;
foreach( Match match in matches )
{
sb.Append( s, pos, match.Index - pos );
int len = match.Length;
int zeros = 0;
if( ignoreZeroPadding )
{
while( zeros + 1 < len && s[match.Index + zeros] == '0' )
{
++zeros;
}
len -= zeros;
}
The loop starts by appending text prior to the numeric text match. It then computes a length for the numeric text token. The zero padding option forces the zero padding comparisons to the end of the token. This way, a user can arbitrarily left zero pad numeric text sequences, and still get intuitive numeric order.
AppendLengthCode( sb, len );
sb.Append( s, match.Index + zeros, match.Length - zeros );
if( ignoreZeroPadding )
{
AppendLengthCode( zeroPadOrder, zeros + 1 );
}
pos = match.Index + match.Length;
}
sb.Append( s, pos, s.Length - pos );
if( ignoreZeroPadding )
{
sb.Append( " " );
sb.Append( zeroPadOrder );
}
return sb.ToString();
}
Using the technique described already, the logic codes the length, or magnitude, of the number into the text, followed by the number text itself, sans the left padded zeros.
Finally, once all the numeric segments have been processed, the zero padding tokens are appended to the end of the string.
The code for AppendLengthCode(..) follows pretty directly to the coding algorithm I described above:
private static void AppendLengthCode( StringBuilder sb, int len )
{
const int largestSmallMagnitude = 9;
if( len <= largestSmallMagnitude )
{
sb.Append( "012345678"[( len - 1 )] );
}
else
{
sb.Append( '9' );
string lenText = ( len - largestSmallMagnitude - 1 ).ToString();
sb.Append( lenText.Length.ToString() );
sb.Append( lenText );
}
}
Using the Code
I created a quick Windows Form wrapper to aid in visualization of the tokens and the sort order. Starting the application should show a form with a sample list of unorder strings:

Clicking the "Lexical Sort" button orders the list according to the standard lexical order of strings. This order works once you get used:
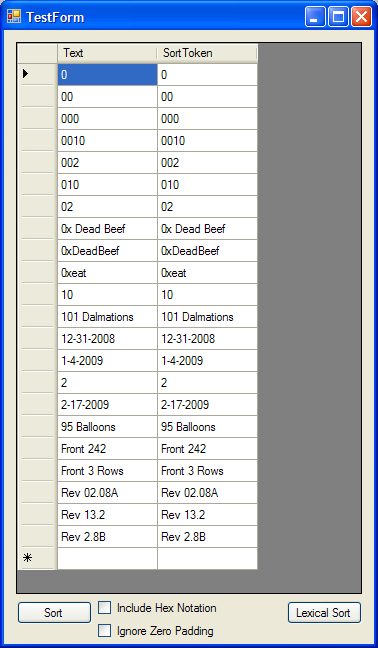
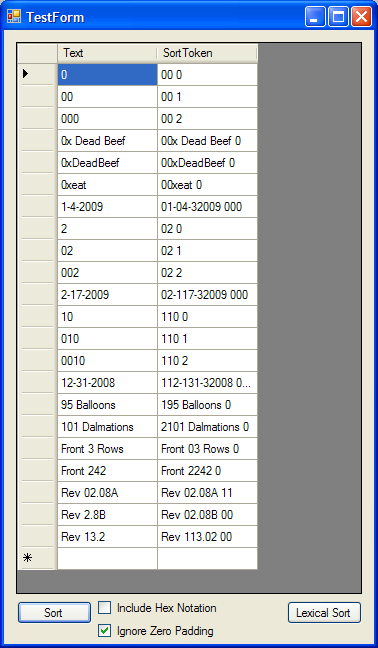
However, using the different check boxes, and clicking 'Sort' demonstrates a more human like order to the list:
One responder asked why I would handle zero padding as a special case. The list order follows, if you do not ignore zero padding:
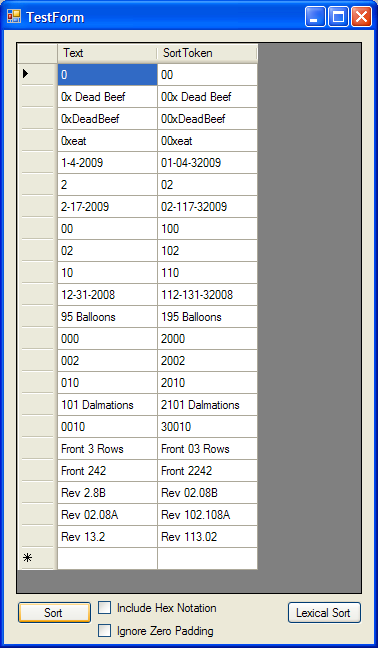
Such an order might have some fringe use, so I left in the option get this ordering. I also included an option to process hexadecimal strings, to demonstrate that any text patterns that can be translated into a magnitude + lexical token can be ordered this way.
This concludes the demonstration of the test application.
Points of Interest
One interesting extension with this algorithm would extend the ability into the .NET SQL CLR. Using a user defined function would allow SQL queries to use the ordering directly:
SELECT *
FROM MyTable
ORDER BY dbo.GetAlphaNumericOrderToken( MyTable.TextField )
I chose not to do this currently, since I'm not sure how difficult getting C# Express and SQL Server Express working together in a CLR environment; deployment, etc. However, it should not be too difficult to accomplish this in a full version of Visual .NET Studio. Feel free to tackle it if you are keen on using this in SQL queries.
History
- 17th February, 2009: Initial post
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 









