Overview
BigInt is a general-purpose unbounded integer implementation consistent with C# and .NET numeric type conventions: it's an immutable ValueType, implements IComparable<BigInt>, IEquatable<BigInt>, and IConvertable interfaces, and supplies arithmetic operators and various implicit and explicit conversion operators.
To date, there are very few options available for C# .NET developers in need of "Big" numbers. Chew Keong TAN's C# BigInteger[^] is very fast, but specialized for cryptology at the neglect of memory considerations (implemented with a constant length Array, memory is quickly exhausted, and performance degraded when the length is set even moderately high). Microsoft's J# BigInteger[^] is also available, but is awkward to use (reference type, no operators, Camel-case), and also requires distributing the J# runtime with your applications.
BigInt is implemented with a LinkedList<byte> in base-10. Hence, memory consumption and performance are not as optimal as may be achieved with an Array in a higher base. That being said, BigInt is reasonably performing and light enough on memory that it should be suitable for many applications.
Arithmetic
Standard pencil and paper algorithms are implemented for addition, subtraction, multiplication, and division. Hence, addition and subtraction yield m + n complexity where m and n are the number of digits in each operand, respectively. And multiplication and division are order m * n. Multiplication uses mutation internally for performance gains (the addition steps are accumulated in the result with AddTo, sparing repeated large memory allocation we'd otherwise incur for temporary states).
Common Algorithms
Beyond basic arithmetic, several common algorithms are provided for BigInt including min, max, mod, pow, and truncated square root, to name a few.
Operators
All binary and unary operators traditionally associated with numeric types are provided; however, bitwise operations and operators have yet to be implemented.
Conversion
To avoid redundancy, while risking incompatibility across all .NET languages, we refrain from using non-default constructors as a method of conversion to BigInt; instead, we rely on implicit conversion operators for lossless conversions from numeric .NET System types, and explicit conversion operators for other useful types. BigInt.Parse and BigInt.TryParse are preferable methods for constructing BigInts from strings, but we also make an exception and implement an explicit string to BigInt conversion operator to accommodate Enumerable.Cast<string>(BigInt). In addition, several lossy explicit conversion operators paralleling IConvertable are provided for conversion from BigInt to other types.
Serialization
BigInt is suitable for both binary and XML serialization. Marked with the Serializable attribute, only the private fields of BigInt (digits and isneg) participate in binary serialization, as is appropriate. Default XML serialization, whereby public fields and properties are serialized, is wholly inappropriate; therefore, we implement the IXmlSerializable interface, representing the BigInt via BigInt.ToString for WriteXml, and deserializing via BigInt.Parse for ReadXml.
Properties
Divisors, ProperDivisors, DigitsLeftToRight, and DigitsRightToLeft are implemented as object streams (IEnumerable<BigInt>) and were selected for their ability to describe fundamental aspects of integers. The first two expose the integer intrinsics. The latter support manipulating integers on the structural level. A PrimeFactorization property is pending implementation.
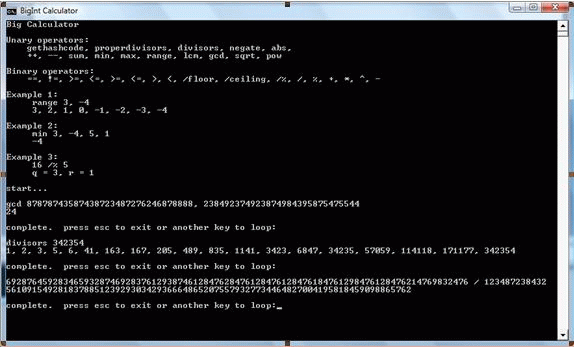
Big Calculator
The sample application provided is driven by BigInt's static Eval method. Eval can parse and evaluate many simple binary and unary BigInt expressions. Eval / BigCalculator may be extended in the future to support processing complex expression trees and typical calculator features such as variable assignment.
History
| Version | Date | Description |
| 1.00 | May 10, 2009 | First release |
| 1.01 | May 11, 2009 | Improved performance of Pow by using exponentiation by squaring. Improved performance of Gcd (and therefore Lcm) by using the Euclidean algorithm.
Modified Range to accept reverse ranges. |
| 1.02 | May 16, 2009 | Fixed remainder bug. |
| 1.03 | May 17, 2009 | Improved division memory usage. |
I'm developing Unquote, a library for writing unit test assertions as F# quoted expressions: http://code.google.com/p/unquote/
I am working through Project Euler with F#: http://projecteulerfun.blogspot.com/
I participate in Stack Overflow: http://stackoverflow.com/users/236255/stephen-swensen


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 







