Introduction
This article describes a sample parser of reg files using the Boost Spirit Parser Framework. The main aim of this article is to share the experience, and that's why here, I'll show not so much the solution for the concrete task or the usage of the concrete technology as the way the development process goes. In particular, we'll discuss why we use the curtain libraries and make one or another solution.
Testimonials
I would like to thank the people who developed the following projects - they made the implementation of this project easier:
I want to say a personal thank you to Silviu Simen for his article INI file reader using the Spirit library.
Background and history of this task
There was a project in which I took part and we needed to test the working of a parser for Windows hive Registry files. These files are stored in binary representation and the structure of such a file is not documented by Microsoft. But, by means of research, my colleagues managed to clear out this structure, and after that, the question of verifying the parser work appeared.
To perform testing, I decided to use the functionality of exporting of Registry in two formats: hive and reg. Thus, I could obtain two different files for the same Registry key and after that check the working of the Windows hive Registry file parser.
The structure of the Registry file - I'll give an example below - is very similar to the structure of the ini file, so you can use standard Windows functions for reading values in this file. But the problem is that, functions work very slow for big files, and that is why this parser was developed - a parser for reg files where I use the Boost Spirit Parser Framework. The reasons why standard Windows functions are slow will be considered below in this article.
What is a reg file?
Let's consider the general view of a reg file structure first, and some special complicated cases will be considered as necessary.
I've taken the following material from here http://en.wikipedia.org/wiki/Windows_Registry.
.REG files (also known as Registration entries) are text-based human-readable files for storing portions of the Registry. On Windows 2000 and later NT-based Operating Systems, they contain the string Windows Registry Editor Version 5.00 at the beginning and are Unicode-based. On Windows 9x and NT 4.0 systems, they contain the string REGEDIT4 and are ANSI-based. Windows 9x format .REG files are compatible with Windows 2000 and later NT-based systems. The Registry Editor on Windows on these systems also supports exporting .REG files in Windows 9x/NT format. Data is stored in .REG files in the following syntax:
[<Hive Name>\<Key Name>\<Subkey Name>]
"Value Name"=<Value type>:<Value data>
Example 1 (different types):
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft]
"Value A"="<String value data>"
"Value B"=hex:<Binary data>
"Value C"=dword:<DWORD value integer>
"Value D"=hex(7):<Multi-string value data>
"Value E"=hex(2):<Expandable string value data>
Example 2 (real):
[HKEY_CURRENT_USER\Key]
"Value string"="B"
"Value dword"=dword:00000001
"Value hard"=hex(1000800c):53,00,65,00,72,00,76,00,69,00,63,00,65,00,53,00,\
74,00,61,00,72,00,74,00,54,00,79,00,70,00,65,00,00,00,4d,00,61,00,78,00,44
Making a little digression, I want to stress that the number in the line " hex(1000800c) " is the type identifier and it can be anything. It's often used as the data in the security branch [HKEY_LOCAL_MACHINE\SAM].
And now, let's try to extend the information about the possible contents of the reg file. Here, I represent some facts obtained during our research process:
1) Key Name may consist of alphabetical symbols and " , \ , [ , ].
2) Number of values of one key can be from 0 to infinite
3) Value Name can be:
- symbol '@' - it means default
- "text" - any symbols can be in this "text"
even these ones: \n , " , \ , [ , ]
but it always ends with "\n symbols in sequence
4) Value data can be:
- "text" - any symbols can be in this "text"
but it always ends with " and \n in sequence
- binary:
- dword:XX
- hex:XX
- hex(N):XX
Comments:
XX can be the pairs of number symbols separated by comas and
it can end with '\' symbol that means that
data continue in the next line
Example:
dword:72,...,00,\
00,..,20
Two approaches and their comparison
As it was mentioned, the structures of reg files and ini files are quite the same, so I started to search for methods for working with ini files. I found the standard Windows functions.
Using the Windows API functions
Windows gives a lot of functions to work with INI files; we are interested in two of them for our task:
GetPrivateProfileSectionNames<link>: Retrieves the names of all the sections in an initialization file.GetPrivateProfileSection<link>: Retrieves all the keys and values for the specified section of an initialization file.
So, we should call GetPrivateProfileSectionNames one time to obtain the list of keys and then call GetPrivateProfileSection to obtain the values inside the keys.
The problem is that if the file is quite big, i.e., there are a lot of keys in it, then we should call GetPrivateProfileSection several times to read from the file. Here is some row test data: file size: 30 MB, file includes about 30,000 keys, the parsing of this file takes about 20 minutes. And, I should say that reg files are often bigger than 100 MB.
So, the problem:
Unjustified number of readings from the file.
Solution:
It's necessary to load the file to the memory at one time or in some parts and then parse its content using your own tools.
Using a custom parser
When parsing a reg file content using your our own tools, it's good idea to use already developed work. Thus, I came across the article about the ini file reader using the Spirit library. Using the example of the ini file parser, I developed my reg file parser.
Why boost::spirit ?
The Spirit Parser Framework is an object oriented recursive descent parser generator framework implemented using template metaprogramming techniques. Expression templates allow users to approximate the syntax of Extended Backus Naur Form (EBNF) completely in C++.
I was also attracted by these factors:
- There are no intermediate conversions to some code needed, and also no external applications except for the compiler.
- You need to include only two header files and no libraries to use the Spirit Parser Framework.
Useful links:
Fleeting glance on boost::spirit
The main idea of using boost::spirit is in using the rules. Usually, several basic rules are defined, and then other rules are defined by means of overridden operators as a combinations of basic rules. The following example shows the creation of rules using "AND" and "NOT" operators:
RuleType simpleRule = ~ch_t('A') & ~ch_t('B');
This rule works for any symbol except for 'A' and 'B'.
Below in this article, each rule will be described in detail, but now, I want to give some quick information about possible operators - to let you imagine what the possible operations with the rules are.
Set operators:
a | b Union Match a or b. Also referred to as alternative
a & b Intersection Match a and b
a - b Difference Match a but not b. If both match and b's matched text
is shorter than a's matched text, a successful match is made
a ^ b XOR Match a or b, but not both
Sequencing Operators:
a >> b Sequence Match a and b in sequence
a && b Sequential-and Sequential-and. Same as above,
match a and b in sequence
a || b Sequential-or Match a or b in sequence
Optional and Loops:
*a - Match a zero (0) or more times
+a - Match a one (1) or more times
!a - Match a zero (0) or one (1) time
a % b - Match a list of one or more repetitions
of a separated by occurrences of b.
This is the same as a >> *(b >> a).
Note that a must not also match b
Single character parsers:
anychar_p Matches any single character
(including the null terminator: '\0')
alnum_p Matches alpha-numeric characters
alpha_p Matches alphabetic characters
blank_p Matches spaces or tabs
cntrl_p Matches control characters
digit_p Matches numeric digits
graph_p Matches non-space printing characters
lower_p Matches lower case letters
print_p Matches printable characters
punct_p Matches punctuation symbols
space_p Matches spaces, tabs, returns, and newlines
upper_p Matches upper case letters
xdigit_p Matches hexadecimal digits
Other comments:
negation ~
Example: ~ch_t('x') - matches any character except 'x'
Introduction to the parser development
Further in this article, I'll try to keep the high level of clearness so I'm sorry in advance if you think that my descriptions are too detailed.
The description starts from the heart of the parser - its algorithm. The algorithm is described in parts, and then the wrapper for this algorithm is described, and then other auxiliary classes. At the end, we'll consider a concrete usage example and test.
Algorithm description
The algorithm is represented by a function and interface:
template<class charT>
struct IResultProcessor
{
virtual ~IResultProcessor(){}
virtual void OnKeyFound(const charT* begin, const charT* end)=0;
virtual void OnValueNameFound(const charT* begin, const charT* end)=0;
virtual void OnValueDataFound(const charT* begin, const charT* end)=0;
};
template<class charT>
inline bool ParseRegFileImpl(const charT* buffer,
IResultProcessor<charT>* resultProc);
It follows from the function names that the algorithm will call the OnKeyFound function for each key name found, OnValueNameFound for each value name found, and OnValueDataFound for the value content.
An observant reader can ask a question: "Why is the processing of value separated into two functions, OnValueNameFound and OnValueDataFound, after all it it one single entity?" The answer is simple: "The implementation of this processing inside the algorithm would be hard and so the algorithm entrusts calling inside it the processing of these two parts".
Preparatory work
At this stage, we will prepare the environment for the convenient work. In particular, we should use namespaces, shorten the line for rule creation, and define frequently used rules.
using namespace boost::spirit;
typedef rule<scanner<const charT*> > RuleType;
typedef chlit<charT> ch_t; typedef chset<charT> chs_t; typedef IResultProcessor<charT> ResProcT;
chs_t anychar_t(anychar_p); chs_t eol_CR('\r'); chs_t eol_LF('\n'); chs_t eol_t(eol_CR);eol_t |= eol_LF;
Auxiliary rules
RuleType blanks = * blank_p;
RuleType not_name_separator = ~ch_t(']') & ~ch_t('[');
RuleType empty_data = blanks >> (eol_t | ch_t('\0'));
RuleType other_data = *(anychar_t & not_name_separator &
~ch_t('@')& ~ch_t('"'));
The first rule is to omit the blanks and tabs. Asterisk means that the rule can work several times in a row or not work at all.
The second rule is to make sure that the current symbol is not the name separator.
The third rule is to omit empty data. The operator >> means that the rule at the left side of the operator and the rule at the right side should be performed in sequence, one after another.
The forth rule is assigned to free data not part of the separators. Any symbol matches this rule except for name separators, @ - the identifier of value by default, and the symbol " that signals the end of the line. This rule can work either several times or never.
Rule for the key name
RuleType ident_kname_continue = ch_t(']') >> ~eol_t;
RuleType ident_key_name = *(anychar_t & ~ch_t(']')) ||
ident_kname_continue >> ident_key_name;
This rule can be illustrated on the scheme:
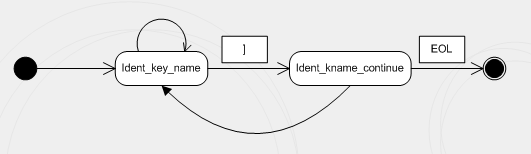
Rule ident_kname_continue is an auxiliary for ident_key_name. First of all, ident_key_name is the recursive rule, and after the process meets symbol ], it tries to define if it is the end of the name or the part of the name. If symbol ] is the part of the name, i.e., there is no symbol of line end after it, and then this rule starts itself again and continues parsing.
Let's consider the following case for example:
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\_HARD_NAME[123]_ABCD]
In this example, the symbol ] is the part of the name and that's why it's necessary to check if there is the symbol of line end after it. You can see such names in the Registry.
Rule for the Value name
RuleType ident_vname_continue = +ch_t('"') >> ~ch_t('=');
RuleType ident_vname_sz_skip = ch_t('\\') >> ch_t('"');
RuleType ident_vname_sz_body = *(anychar_t & ~ch_t('"') || ident_vname_sz_skip );
RuleType ident_vname_sz =
ident_vname_sz_body >> *(ident_vname_continue >> ident_vname_sz_body);
RuleType ident_vname_sz_impl = ch_t('"') >> ident_vname_sz >> +ch_t('"');
RuleType ident_vname_def = ch_t('@');
RuleType ident_value_name = ident_vname_def | ident_vname_sz_impl;
This rule can be represented on the scheme:

Rule for the value content
RuleType vdata_bin_body =*(anychar_t & ~ch_t('\0') &
~eol_t & ~ch_t('\\'));
RuleType vdata_bin_continue = ch_t('\\') >> eol_t;
RuleType vdata_bin = vdata_bin_body >>
*(vdata_bin_continue >> vdata_bin_body);
RuleType vdata_sz_continue = +ch_t('"') >> ~eol_t;
RuleType vdata_sz_body_impl = *(anychar_t & ~ch_t('"'));
RuleType vdata_sz_body = vdata_sz_body_impl >>
*(vdata_sz_continue >> vdata_sz_body_impl);
RuleType ident_vdata_sz = ch_t('"') >> vdata_sz_body >> +ch_t('"');
RuleType ident_vdata = ident_vdata_sz | vdata_bin;
This rule can be represented on the scheme like this:
Rule that describes the line with the key name
RuleType l_key =
other_data>> ch_t('[') >> ident_key_name [bind(&CRegFileParserImpl::OnKeyFound,
this, _1,_2) ] >>
blanks >> ch_t(']') >> blanks >> *eol_t;
This rule requires the execution of several rules in sequence. The new idea here is to use the operator []. In this case, it means that when the rule is activated, the functor transferred as the parameter should be called. And, the range where this rule worked will be transferred to this functor via two parameters.
Rule that describes the line with the Value
RuleType l_values =
other_data>> ident_value_name
[bind(&CRegFileParserImpl::OnValueNameFound, this, _1,_2) ] >>
blanks >> ch_t('=') >> blanks >> value_data
[bind(&CRegFileParserImpl::OnValueDataFound, this, _1,_2) ] >>
blanks >> *eol_t;
This rule is much like the previous one. At this moment, we can return to the question stated during the interface discussion: "Why is the processing of Value separated into two functions OnValueNameFound and OnValueDataFound, after all it is one single entity?". Now, we can give a more detailed answer. As it's seen from the code above, it's hard to support an interface corresponding to the reg file structure by means of boost::spirit - a function call with 4 parameters for the whole value.
Gathering everything together
RuleType lines = l_key | l_values | empty_data;
RuleType reg_file = lexeme_d [*lines] ;
return (parse(buffer, reg_file).full);
So, we finished the algorithm of reg file parsing. The rules for the key name are set, the value is aggregated, and the file parsing starts.
The whole function looks like the following:
template<class charT>
inline bool ParseRegFileImpl(const charT* buffer,
IResultProcessor<charT>* resultProc)
{
using namespace boost::spirit;
typedef rule<scanner<const charT*> > RuleType;
typedef chlit<charT> ch_t; typedef chset<charT> chs_t; typedef IResultProcessor<charT> ResProcT;
chs_t anychar_t(anychar_p); chs_t eol_CR('\r'); chs_t eol_LF('\n'); chs_t eol_t(eol_CR); eol_t |= eol_LF;
RuleType blanks = * blank_p;
RuleType not_name_separator = ~ch_t(']') & ~ch_t('[');
RuleType empty_data = blanks >> (eol_t | ch_t('\0'));
RuleType other_data = *(anychar_t & not_name_separator &
~ch_t('@')& ~ch_t('"'));
RuleType ident_kname_continue = ch_t(']') >> ~eol_t;
RuleType ident_key_name = *(anychar_t & ~ch_t(']')) ||
ident_kname_continue >> ident_key_name;
RuleType ident_vname_sz_skip = ch_t('\\') >> ch_t('"');
RuleType ident_vname_sz_impl =
*(anychar_t & ~ch_t('"') || ident_vname_sz_skip );
RuleType ident_vname_sz = ch_t('"') >>
ident_vname_sz_impl >> +ch_t('"');
RuleType ident_vname_def = ch_t('@');
RuleType ident_value_name = ident_vname_def | ident_vname_sz;
RuleType vdata_bin_body =
*(anychar_t & ~ch_t('\0') & ~eol_t & ~ch_t('\\'));
RuleType vdata_bin_continue = ch_t('\\') >> eol_t;
RuleType vdata_bin = vdata_bin_body >>
*(vdata_bin_continue >> vdata_bin_body);
RuleType vdata_sz_continue = +ch_t('"') >> ~eol_t;
RuleType vdata_sz_body_impl = *(anychar_t & ~ch_t('"'));
RuleType vdata_sz_body = vdata_sz_body_impl >>
*(vdata_sz_continue >> vdata_sz_body_impl);
RuleType ident_vdata_sz = ch_t('"') >>
vdata_sz_body >> +ch_t('"');
RuleType ident_vdata = ident_vdata_sz | vdata_bin;
RuleType l_key =
other_data>> ch_t('[') >> ident_key_name [bind(&ResProcT::OnKeyFound,
resultProc, _1,_2) ] >>
blanks >> ch_t(']') >> blanks >> *eol_t;
RuleType l_values =
other_data>> ident_value_name [bind(&ResProcT::OnValueNameFound,
resultProc, _1,_2) ] >>
blanks >> ch_t('=') >> blanks >> ident_vdata [bind(&ResProcT::OnValueDataFound,
resultProc, _1,_2) ] >>
blanks >> *eol_t;
RuleType lines = l_key | l_values | empty_data;
RuleType reg_file = lexeme_d [*lines] ;
return (parse(buffer, reg_file).full);
}
CRegFileParser
It's time to consider the wrapper class for this algorithm. This class assumes the processing of the value name and the value content. In other words, this class supports the following intrface:
template<class charT>
struct IRegFileObserver
{
virtual ~IRegFileObserver(){}
virtual void OnKeyFound(const charT* begin, const charT* end)=0;
virtual void OnValueFound(const charT* nameBegin, const charT* nameEnd,
const charT* dataBegin, const charT* dataEnd)=0;
};
And the class itself:
template<class charT>
class CRegFileParser:public IResultProcessor<charT>
{
typedef std::pair<const charT*,const charT*> BuferRange;
BuferRange lastVName_;
IRegFileObserver<charT>* pObserver_;
bool bLastVNameProcessed_;
public:
CRegFileParser(IRegFileObserver<charT>* pObserver)
: pObserver_(pObserver)
, bLastVNameProcessed_(true)
{}
bool Parse(const charT* buffer)
{
return ParseRegFileImpl(buffer,this);
}
private:
void OnKeyFound(const charT* begin, const charT* end)
{
CheckVNameProcessed(true);
pObserver_->OnKeyFound(begin,end);
}
void OnValueNameFound(const charT* begin, const charT* end)
{
CheckVNameProcessed(true);
bLastVNameProcessed_ = false;
lastVName_.first = begin;
lastVName_.second = end;
}
void OnValueDataFound(const charT* begin, const charT* end)
{
CheckVNameProcessed(false);
bLastVNameProcessed_ = true;
pObserver_->OnValueFound(lastVName_.first,
lastVName_.second,begin,end);
}
void CheckVNameProcessed(bool needToBeProcessed)
{
if(bLastVNameProcessed_ != needToBeProcessed)
throw std::exception("Value data not " +
"found for founded value name");
}
};
Using Pool
Before considering the observers created for testing, we should describe the usage of the boost Pool library.
What is Pool?
Pool allocation is a memory allocation scheme that is very fast, but limited in its usage.
Installation
The Boost Pool library is a header file library. That means there is no .lib, .dll, or .so to build; just add the Boost directory to your compiler's include file path, and you should be good to go!
How do I use Pool?
To make it convenient, I created the following classes that have the functionality of the standard STL containers but use the boost Pool library:
#include <boost/pool/pool_alloc.hpp>
#include <map>
#include <vector>
#include <list>
#include <string>
template<class _Kty, class _Ty>
class QMap : public std::map< _Kty, _Ty, std::less<_Kty>,
boost::fast_pool_allocator< std::pair<_Kty,_Ty> > >
{};
template<class _Ty>
class QVect : public std::vector< _Ty, boost::pool_allocator<_Ty> >
{};
template<class _Ty>
class QList : public std::list< _Ty, boost::pool_allocator<_Ty> >
{};
template<class _Ty>
class QStringStream :
public std::basic_stringstream< _Ty,std::char_traits<_Ty>,
boost::pool_allocator<_Ty> >
{};
template<class _Ty>
class QString: public std::basic_string<_Ty,std::char_traits<_Ty>,
boost::pool_allocator<_Ty> >
{
typedef std::basic_string<_Ty,std::char_traits<_Ty>,
boost::pool_allocator<_Ty> >
BaseClass;
public:
QString(){}
QString(const _Ty* first,const _Ty* last)
: BaseClass(first,last)
{}
};
The only disadvantage - as you could notice - is no full support for original constructors. I actually think that it's not a big problem, you can just insert the necessary constructor if it's needed.
Observers
Some observers were created for testing purposes:
CRegStatusObserver - assigned to print the status of the parsing process on the screen in percentage.CRegCountObserver - assigned to print the number of keys and the values on the screen.CRegPrintObserver - assigned to print all the keys and values on the screen.CRegFullObserver - assigned to store all the keys in std::map, where the name of the Registry key is key and the vector of all the values of this Registry key is the std::vector values.CRegObserversPool - assigned to make it possible to use several observers simultaneously.
It's important to mention that these observers print information on the screen, but they can be used to print to the file or some other stream. For example, CRegCountObserver:
template<class charT,class streamT>
class CRegCountObserver:public IRegFileObserver<charT>
{
size_t keysCount_;
size_t valuesCount_;
streamT& out_;
public:
CRegCountObserver(streamT& out)
: keysCount_(0)
, valuesCount_(0)
, out_(out)
{}
~CRegCountObserver()
{
out_ << "Keys count: "
<< keysCount_
<< "\t Values count: "
<< valuesCount_
<< "\n";
}
...
};
And some examples of its usage:
CRegCountObserver<char> screenObsr(std::cout);
std::stringstream strStream;
CRegPrintObserver<char,std::stringstream> stringObsr(strStream);
std::fstream fileStream;
CRegPrintObserver<char,std::fstream> fileObsr(fileStream);
The usage of other observers is the same.
Auto-tests description
All auto-test are represented in the one project, RegFileParserAutoTest.
The test is a console application developed with the Boost Testing Framework. Five complicated cases were chosen to be the test data: one for key name, two for value name, and two for value content.
There is one more case with the typical content of a reg file. So, we have six cases, and there are two versions of reg file format - ANSI and UNICODE (Regedit4 and Regedit5 correspondingly); each of our cases duplicates for two formats. As a result, we have 12 test files.
To control the results of parsing, we use a comparison of the original content and the content parsed and saved in memory using CRegPrintObserver:
template<class charT>
class TestRunner
{
protected:
typedef std::basic_string<charT> stringT;
typedef std::basic_stringstream<charT> stringstreamT;
typedef std::basic_fstream<charT> fstreamT;
public:
...
static void
RunTest(const std::wstring& fileName)
{
std::vector<char> buffer;
ReadFile(fileName,&buffer);
stringstreamT stream;
reg_parser::CRegPrintObserver<charT,stringstreamT>
coutObserver(stream);
reg_parser::CRegFileParser<charT> regParser(&coutObserver);
if( !regParser.Parse( (charT*)&buffer[0] ) )
throw std::exception("Parsing fail.");
stringT parsedStr;
AddRegHeader(&parsedStr);
parsedStr += stream.str();
stringT originalStr = stringT((charT*)&buffer[0]);
using namespace boost;
trim_if(originalStr,is_any_of("\n\t\0 "));
trim_if(parsedStr,is_any_of("\n\t\0 "));
if( parsedStr != originalStr)
{
std::wstring parsedFileName = fileName + L"_parsed";
fstreamT file(parsedFileName.c_str(),
fstreamT::out | fstreamT::trunc);
if( file.is_open() == false )
throw std::exception("Can't create file for "
"result of parsing.");
BOOST_SCOPE_EXIT( (&file) )
{
file.close();
}
BOOST_SCOPE_EXIT_END
file << parsedStr;
throw std::exception("Parsed data not "
"equal to original data.");
}
}
...
};
Description for manual testing
Manual tests are represented in one project, RegFileParserTestCmd. The test is a console application implemented using Boost Program Options that has these parameters:
C:\RegFileParser\bin\Debug>RegFileParserTestCmd.exe --help
Allowed options:
--help produce help message
--reg_file arg source reg file
--print Enable printing to the screen
--count Enable counting parsed keys and values
--status Enable printing status of parsing
It's a pity that I don't have enough time to add options to save the parsed content to a file, and using the save option like it is in autotest doesn't seem to be aesthetic to me.
Registry export using Regedit
Conclusion
This article is a special piece of knowledge, so may be it's not as systematic as it should be.
It was really interesting to learn boost spirit, and I managed to get the pleasure of my work with it and some aesthetic satisfaction - not just get my task done. After all, this discovered to be very effective; for example, the calculation of number of keys and values in a Registry file of 250 MB now takes a couple of seconds only.
So learn something new, and good luck to you in your development!
ApriorIT is a software research and development company specializing in cybersecurity and data management technology engineering. We work for a broad range of clients from Fortune 500 technology leaders to small innovative startups building unique solutions.
As Apriorit offers integrated research&development services for the software projects in such areas as endpoint security, network security, data security, embedded Systems, and virtualization, we have strong kernel and driver development skills, huge system programming expertise, and are reals fans of research projects.
Our specialty is reverse engineering, we apply it for security testing and security-related projects.
A separate department of Apriorit works on large-scale business SaaS solutions, handling tasks from business analysis, data architecture design, and web development to performance optimization and DevOps.
Official site: https://www.apriorit.com
Clutch profile: https://clutch.co/profile/apriorit
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





 Then you could search it. I vote for this feature!
Then you could search it. I vote for this feature!