Introduction
In order to allow your programs to be used in international
markets it is worth making your application Unicode or MBCS
aware. The Unicode character set is a "wide character"
(2 bytes per character) set that contains every character
available in every language, including all technical symbols and
special publishing characters. Multibyte character set (MBCS)
uses either 1 or 2 bytes per character and is used for character
sets that contain large numbers of different characters (eg Asian
language character sets).
Which character set you use depends on the language and the
operating system. Unicode requires more space than MBCS since
each character is 2 bytes. It is also faster than MBCS and is
used by Windows NT as standard, so non-Unicode strings passed to
and from the operating system must be translated, incurring
overhead. However, Unicode is not supported on Win95 and so MBCS
may be a better choice in this situation. Note that if you wish
to develop applications in the Windows CE environment then all
applications must be compiled in Unicode.
Using MBCS or Unicode
The best way to use Unicode or MBCS - or indeed even ASCII -
in your programs is to use the generic text mapping macros
provided by Visual C++. That way you can simply use a single
define to swap between Unicode, MBCS and ASCII without having to
do any recoding.
To use MBCS or Unicode you need only define either _MBCS
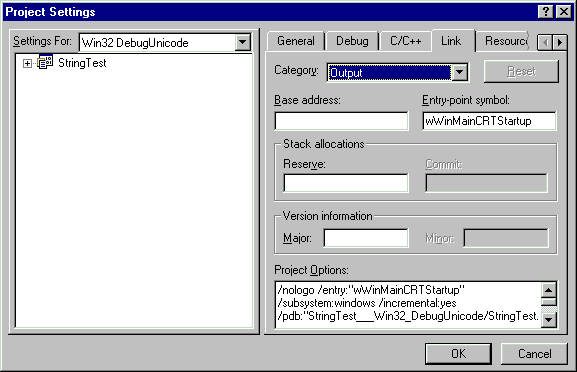
or _UNICODE in your project. For Unicode you
will also need to specify the entry point symbol in your Project
settings as wWinMainCRTStartup. Please note that
if both _MBCS and _UNICODE are
defined then the result will be unpredictable.
Generic Text mappings and portable functions
The generic text mappings replace the standard char or LPSTR
types with generic TCHAR or LPTSTR macros. These macros will map
to different types and functions depending on whether you have
compiled with Unicode or MBCS (or neither) defined. The simplest
way to use the TCHAR type is to use the CString
class - it is extremely flexible and does most of the work for
you.
In conjunction with the generic character type, there is a set
of generic string manipulation functions prefixed by _tcs.
For instance, instead of using the strrev
function in your code, you should use the _tcsrev
function which will map to the correct function depending on
which character set you have compiled for. The table below
demonstrates:
| #define | Compiled
Version | Example |
| _UNICODE | Unicode (wide-character) | _tcsrev maps to _wcsrev |
| _MBCS | Multibyte-character | _tcsrev maps to _mbsrev |
| None (the default: neither _UNICODE
nor _MBCS defined) | SBCS (ASCII) | _tcsrev maps to strrev |
Each str* function has a corresponding tcs*
function that should be used instead. See the TCHAR.H file for
all the mapping and macros that are available. Just look up the
online help for the string function in question in order to find
the equivalent portable function.
Note: Do not use the str*
family of functions with Unicode strings, since Unicode strings
are likely to contain embedded null bytes.
The next important point is that each literal string should be
enclosed by the TEXT() (or _T())
macro. This macro prepends a "L" in front of literal
strings if the project is being compiled in Unicode, or does
nothing if MBCS or ASCII is being used. For instance, the string
_T("Hello") will be interpreted as "Hello" in
MBCS or ASCII, and L"Hello" in Unicode. If you are
working in Unicode and do not use the _T()
macro, you may get compiler warnings.
Note that you can use ASCII and Unicode within the same
program, but not within the same string.
All MFC functions except for database class member functions
are Unicode aware. This is because many database drivers themselves
do not handle Unicode, and so there was no point in writing Unicode
aware MFC classes to wrap these drivers.
Converting between Generic types and ASCII
ATL provides a bunch of very useful macros for
converting between different character format. The basic form of
these macros is X2Y(), where X is the source
format. Possible conversion formats are shown in the following
table.
| String Type | Abbreviation |
|---|
| ASCII (LPSTR) | A |
| WIDE (LPWSTR) | W |
| OLE (LPOLESTR) | OLE |
| Generic (LPTSTR) | T |
| Const | C |
Thus, A2W converts an LPSTR to an LPWSTR,
OLE2T converts an LPOLESTR to an LPTSTR, and
so on.
There are also const forms (denoted by a C)
that convert to a const string. For instance, A2CT
converts from LPSTR to LPCTSTR.
When using the string conversion macros you need to include
the USES_CONVERSION macro at the beginning of
your function:
void foo(LPSTR lpsz)
{
USES_CONVERSION;
...
LPTSTR szGeneric = A2T(lpsz)
...
}
Two caveats on using the conversion macros:
- Never use the conversion macros inside a tight loop. This
will cause a lot of memory to be allocated each time the
conversion is performed, and will result in slow code.
Better to perform the conversion outside the loop and
pass the converted value into the loop.
- Never return the result of the macros directly from a
function, unless the return value implies making a copy
of the data before returning. For instance, if you have a
function that returns an LPOLESTR, then do not do the
following:
LPTSTR BadReturn(LPSTR lpsz)
{
USES_CONVERSION;
return A2T(lpsz);
}
Instead, you should return the value as a CString,
which would imply a copy of the string would be made
before the function returns:
CString GoodReturn(LPSTR lpsz)
{
USES_CONVERSION;
return A2T(lpsz);
}
Tips and Traps
The TRACE statement
The TRACE macros have a few cousins - namely
the TRACE0, TRACE1, TRACE2
and TRACE3 macros. These macros allow you to
specify a format string (as in the normal TRACE
macro), and either 0,1,2 or 3 parameters, without the need to
enclose your literal format string in the _T()
macro. For instance,
TRACE(_T("This is trace statement number %d\n"), 1);
can be written
TRACE1("This is trace statement number %d\n", 1);
Viewing Unicode strings in the debugger
If you are using Unicode in your applciation and wish to view Unicode strings
in the debugger, then you will need to go to Tools | Options | Debug and click
on "Display Unicode Strings".
The Length of strings
Be careful when performing operations that depend on the size
or length of a string. For instance, CString::GetLength
returns the number of characters in a string, NOT the size in
bytes. If you were to write the string to a CArchive
object, then you would need to multiply the length of the string
by the size of each character in the string to get the number of
bytes to write:
CString str = _T("Hello, World");
archive.Write( str, str.GetLength( ) * sizeof( TCHAR ) );
Reading and Writing ASCII text files
If you are using Unicode or MBCS then you need to be careful
when writing ASCII files. The safest and easiest way to write
text files is to use the CStdioFile class
provided with MFC. Just use the CString class
and the ReadString and WriteString member
functions and nothing should go wrong. However, if you need to
use the CFile class and it's associated Read
and Write functions, then if you use the following code:
CFile file(...);
CString str = _T("This is some text");
file.Write( str, (str.GetLength()+1) * sizeof( TCHAR ) );
instead of
CStdioFile file(...);
CString str = _T("This is some text");
file.WriteString(str);
then the results will be Significantly different. The two lines of
text below are from a file created using the first and second code snippets
respectively:

(This text was viewed using WordPad)
Not all structures use the generic text mappings
For instance, the CHARFORMAT structure, if the RichEditControl
version is less than 2.0, uses a char[] for the szFaceName field,
instead of a TCHAR as would be expected. You must be careful not
to blindly change "..." to _T("...") without
first checking. In this case, you would probably need to convert
from TCHAR to char before copying any data to the szFaceName
field.
Copying text to the Clipboard
This is one area where you may need to use ASCII and Unicode
in the same program, since the CF_TEXT format for the clipboard
uses ASCII only. NT systems have the option of the CF_UNICODETEXT
if you wish to use Unicode on the clipboard.
Installing the Unicode MFC libraries
The Unicode versions of the MFC libraries are
not copied to your hard drive unless you select them during a
Custom installation. They are not copied during other types of
installation. If you attempt to build or run an MFC Unicode
application without the MFC Unicode files, you may get errors.
(From the online docs) To copy the files to
your hard drive, rerun Setup, choose Custom installation,
clear all other components except "Microsoft Foundation
Class Libraries," click the Details button, and
select both "Static Library for Unicode" and
"Shared Library for Unicode."


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 







 Is it true?
Is it true?


