Introduction
Sending or routing zip-files via BizTalk is very easy. Even zipping those archives just before sending them in a custom pipeline component is no big deal since there are handy libraries like Ionic.Zip. The usual way is to create a zip-file in a custom pipeline component, put all files in it, and then save it to a MemoryStream. Finally, this stream is assigned to the outgoing message. Done! (See here.)
But what if an archive grows up to a gigabyte? You don’t want that amount of data in your memory, so you might think of a streaming approach. There are a few tutorials on the net which describe streaming pipeline components. Check out MSDN to get a detailed introduction to that topic.
This article will combine two issues: creating an archive in a pipeline component with Ionic.Zip and following the streaming approach to avoid holding the compressed data in memory. At the end of this document, you will know how to zip and send thousands of files in an archive using about 100 KB in memory.
Background
I chose the topic because I recently was challenged by a zip-file having over 25,000 files to send to a bunch of FTP-destinations. The real challenge was an XML file among these files, which was unique for every single destination. I didn't want to create a gigabyte-zip for every destination, store them on disk, and then send it. So I got the idea of creating the archives in a pipeline on the fly. But whatever I tried, there was no way to do this without having the whole data at least once in memory. And that lead me to System.OutOfMemoryExceptions all the time. So you might think of ZipOutputStream from Ionic.Zip? Sure, but this stream writes central directory-information on disposing and for this - in some way - all the data of that stream still has to be readable. Whenever I tried to trick that stream, I got a CRC-error. So there was no way around to point ZipOutputStream to file or to memory. No win!
The second approach Ionic.Zip-Lib offers you is to create a zip using a ZipFile object and Save() it giving it a stream. Also non-seekable streams are supported, so there is a way to sequentially write a zip-file without jumping around to update file-headers or to write central directory-info. Since I do not want to stress memory, I have to create a custom stream for the ZipFile.Save() method.
The Scenario
I got an XML-document in BizTalk messagebox with tons of file-paths, which point to local disk files. The aim is to send a zip-archive with all those referenced files and the XML-document itself in it. As I already mentioned, System.OutOfMemoryException is no aim.
First of all, I will show you the easy way to do it. Create a new pipeline-component (learn about it here) and read out the file-paths. Create a zip-file using a MemoryStream and assign it to the message.
public IBaseMessage Execute(IPipelineContext pContext, IBaseMessage pInMsg))
{
var lstFiles = new List<string>();
using(var oXmlReader = XmlReader.Create(pInMsg.BodyPart.GetOriginalDataStream()))
{
while (oXmlReader.ReadToFollowing("path", "http://namespace.uri"))
{
var strFileLocation = oXmlReader.ReadElementContentAsString();
if (!lstFiles.Contains(strFileLocation))
lstFiles.Add(strFileLocation);
}
}
var oZip = new ZipFile();
oZip.AddFiles(lstFiles, "");
oZip.AddEntry("metafile.xml", pInMsg.BodyPart.Data);
var oMemoryStream = new MemoryStream();
oZip.Save(oMemoryStream);
oMemoryStream.Seek(0, SeekOrigin.Begin);
pInMsg.BodyPart.Data = oMemoryStream;
pContext.ResourceTracker.AddResource(oMemoryStream);
return pInMsg;
}
So this is what I don't want: high memory usage. My own stream called OntheflyZipStream will do better.
public IBaseMessage Execute(IPipelineContext pContext, IBaseMessage pInMsg)
{
var lstFiles = new List<string>();
using(var oXmlReader = XmlReader.Create(pInMsg.BodyPart.GetOriginalDataStream()))
{
}
var oMsgStream = pInMsg.BodyPart.GetOriginalDataStream();
var oOTFZipStream = new OntheflyZipStream(oMsgStream, "metafile.xml", lstFiles);
pInMsg.BodyPart.Data = oOTFZipStream;
pContext.ResourceTracker.AddResource(oOTFZipStream);
return pInMsg;
}
Remark for those having problems (especially with new SFTP-Adapater in BT2013):
For some reason, the new SFTP-adapter in BizTalk 2013 will not read from my custom stream although it is assigned to the message. Without entering the Read-method at least once, the send port immediately gives you an ACK. You can solve the problem by wrapping OntheflyZipStream with a ReadonlySeekableStream (use the same buffer size as you will do for ChunkByChunkStream later on):
var oReadonlyStream = new ReadOnlySeekableStream(oBufferedZipStream, 1024 * 100);
pInMsg.BodyPart.Data = oReadonlyStream;
pContext.ResourceTracker.AddResource(oReadonlyStream);
You do not see any ZipFile object here. The whole magic happens in the custom stream. It's time to introduce OntheflyZipStream. The following picture will help me to explain the functionality:
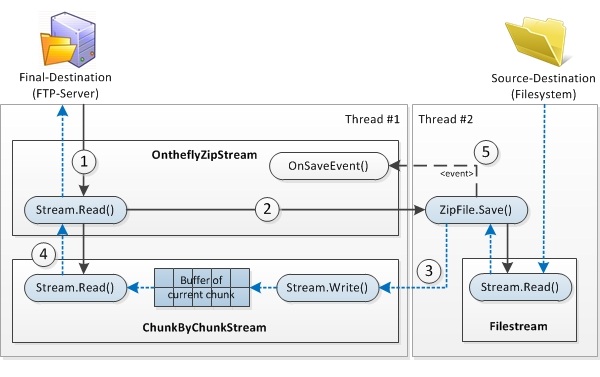
Since OntheflyZipStream is an own stream-implementation, it has to handle the read-requests. Writing is not supported on BizTalk message-streams so we don't care. First time the OntheflyZipStream is asked for data it has to determine where to get it. As we want to return a zip-archive, the source to read from is the output of ZipFile.Save(). Because we are only interested in several bytes from the Save() output at once, it is not necessary to buffer all the data. This is were my own ChunkByChunkStream comes into play. This is the stream (a wrapped memorystream) where Save() writes into. On the other hand, it is the stream where to read from in order to resolve a read request from destination. To keep it small, the ChunkByChunkStreamm only has a small buffer. It receives data from ZipFile.Save() until the buffer is full. In this case, it stops writing and lets the OntheflyZipStream read it out. If the buffer is read out, it will be cleaned and the writing from the ZipFile.Save() method goes on. Reading and writing the data is not synchronous, so it is recommended to work with separate threads. One for reading, one for writing.
Step by Step
0) Before reading or writing, OntheflyZipStream has to do some work in its constructor. You already saw the instantiation of that stream in the last code-lines, so here we continue:
public delegate void ZipFileSaveDelegate(Stream oStream);
ZipFileSaveDelegate _oDelegateZipFileSave;
ChunkByChunkStream _oChunkByChunkStream;
Nullable<ZipProgressEventType> _oSaveStatus = null;
public OntheflyZipStream(Stream oMetafileStream, string strStreamsFilename, List<string> lstFiles)
{
var oZip = new ZipFile();
oZip.AddFiles(lstFiles, "");
using (var oStreamReader = new StreamReader(oMetafileStream))
{
oZip.AddEntry(strStreamsFilename, oStreamReader.ReadToEnd(), Encoding.UTF8);
}
oZip.SaveProgress += OnSaveEvent;
_oDelegateZipFileSave = new ZipFileSaveDelegate(oZip.Save);
}
The constructor gets the original message-stream, a name for its file-representation in the zip-archive, and the enumerated files as a list. Both message and files are added to the ZipFile object from Ionic.Zip-Lib. The actual saving will not start here, we only need a delegate to invoke the Save() method later on. The difficult part is to keep track of what is happening in the Save() method while it runs in another thread. Therefore we get the event SaveProgress which we will subscribe to.
1-2) As soon as the OntheflyZipStream becomes the message-stream in BizTalk (by assigning it to the message-stream (see the Execute() method in pipeline component), it has to be prepared for read-requests. So, we go on with overwriting the Read() method.
public override int Read(byte[] buffer, int offset, int count)
{
if (_oSaveStatus == null)
{
_oChunkByChunkStream = new ChunkByChunkStream() { Buffer = 1024 * 100 };
_oDelegateZipFileSave.BeginInvoke(_oChunkByChunkStream, null, null);
}
if (_oSaveStatus == ZipProgressEventType.Saving_Completed &&
_oChunkByChunkStream.IsReadComplete)
{
return 0;
}
return _oChunkByChunkStream.Read(buffer, offset, count);
}
On first read (we get this information by checking the last SaveEvent, which is nothing, because the Save() method was not invoked yet), the ChunkByChunkStream is created with a buffer-size. I choose 100 KB to keep my promise from the introduction, but it might be recommended to use one to ten megabytes. You will see what it means to size the buffer later on. Next, we will invoke the Save() method. As I already mentioned, ChunkByChunkStream is where to write zip-data to. We also have to check, if there is nothing more to read from. This is the case when we catch an event from the Save() method saying save is complete and the currently chunked data is read out from the stream. Return 0 to let the caller know that no further read-requests are necessary - the zip-file is complete.
Most important is the last line, where we finally read from the current chunk of the ZipFile.Save() method's output. If there is nothing to read, because Save() method did not finish writing the current chunk, the Read()-method of ChunkByChunkStream will wait for it. It simply throttles the process of reading. More about that coming soon.
3) The OntheflyZipStream has nothing to do with writing data. It invoked the Save() method in another thread and does not care about it anymore. The only connection it has to the written data is over the ChunkByChunkStream. So let's have a look at the Write() method of that stream.
public class ChunkByChunkStream : MemoryStream, IDisposablee
{
bool _bIsWriting = true;
long _lBuffer = 1024 * 32;
int _intReadTimeout = 1000;
int _intWriteTimeout = 1000;
public override void Write(byte[] buffer, int offset, int count)
{
var dtTimesOut = DateTime.Now.AddMilliseconds(ReadTimeout);
while (!_bIsWriting)
{
if (dtTimesOut < DateTime.Now)
throw new TimeoutException("Consumer did not read buffered zip-chunk in time.");
Thread.Sleep(50);
}
base.Write(buffer, offset, count);
if (BufferExceeded) StopWriting(true);
}
}
First of all, I have to mention that the ChunkByChunkStream never writes and reads at the same time. So when ZipFile.Save() method writes something new to this stream, it holds on writing to the buffer as long as the current chunk is not read out. This is done by a while-loop, checking whether the stream is currently open for reading. Do some sleeping enhances the performance (ever read that?). When written, the Write() method checks if the defined buffer-size is exceeded -> turn off writing and turn on read mode.
public bool BufferExceeded
{
get { return Length >= Buffer; }
}
public void StopWriting(bool bPositionToBegin)
{
if (bPositionToBegin) base.Seek(0, SeekOrigin.Begin);
_bIsWriting = false;
}
4) So when the buffer-size exceeds and the Write() method stops itself (it's actually running again, but sleeping in the while-loop), the Read() method awakes. It can fulfill read-requests from OntheflyZipStream as long as the current chunk of data is not read out (-> IsReadComplete):
public override int Read(byte[] buffer, int offset, int count)
{
if (IsReadComplete) ContinueWriting(true);
var dtTimesOut = DateTime.Now.AddMilliseconds(WriteTimeout);
while (IsWriting)
{
if (dtTimesOut < DateTime.Now)
throw new TimeoutException("Zip did not write next zip-chunk in time.");
Thread.Sleep(50);
}
return base.Read(buffer, offset, count);
}
public void ContinueWriting(bool bResetStreamFirst)
{
if (bResetStreamFirst) SetLength(0);
_bIsWriting = true;
}
public bool IsReadComplete
{
get { return (Length == Position); }
}
I think you already got the idea with the while-loop. Same here, but now waiting for the write process to end.
A last note on the timeout-values used above to avoid having infinite while-loops. A MemoryStream does not implement these member but throws a NotImplementedException(). Override these members and set it as you want. The best approach is to set the value depending on the buffer-size.
public override int ReadTimeout
{
get
{
return _intReadTimeout * Buffer / 1000 > int.MaxValue ?
int.MaxValue : Convert.ToInt32(_intReadTimeout * Buffer / 1000);
}
set { _intReadTimeout = value; }
}
public override int WriteTimeout
{
get
{
return _intWriteTimeout * Buffer / 1000 > int.MaxValue ?
int.MaxValue : Convert.ToInt32(_intWriteTimeout * Buffer / 1000);
}
set { _intWriteTimeout = value; }
}
The ChunkByChunkStream nearly is finished. Just one important thing is missing. Due to the custom reading/writing, it is recommended to make the stream not seekable. If you do not disable it, ZipFile.Save() may try to seek in this stream.
public override bool CanSeek
{
get { return false; }
}
public override long Seek(long offset, SeekOrigin origin)
{
throw new NotSupportedException("Stream is not seekable");
}
5) Finally we have a closer look at the event handler in OntheflyZipStream. Remember, that we subscribed to events raised by ZipFile.Save(). At least we have to know when saving is complete to let the whole process end and return 0 in the Read() method (you already saw that above).
void OnSaveEvent(object sender, SaveProgressEventArgs e)
{
_oSaveStatus = e.EventType;
if (_oSaveStatus == ZipProgressEventType.Saving_Completed)
{
_oChunkByChunkStream.StopWriting(true);
}
}
Immediately stop the write-process of the ChunkByChunkStream when saving is complete. This lets the stream read out the rest of the data until the process finishes. I advise you to take a closer look at the SaveProgressEventArgs and the EventType. There are other very useful events you can react on.
Conclusion
We now have a cool streaming pipeline, which creates an archive with given file-sources. The great thing about it is the low memory-usage. This solution works great for me and I send more than 15 zip-files each being more than 300 MB in size (one is even 1.2 GB) at the same time. Performance is okay. There is no real impact from the read/write-throttling, because the actual sending (in my case via FTP) limits the performance per se. In the picture below, you can see the network-load while zipping and sending 78 MB with a buffersize of 10 MB. It shows you eight peaks, in which ChunkByChunkStream read data from the buffer. Between them are short interruptions, in which ChunkByChunkStream wrote the buffer.

Feel free to use this solution or even enhance it, but leave a comment. Maybe there are other ways to do streaming with on the fly zipping. I spent a whole weekend on this and found no other appropriate solution.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.





