Introduction
OK, your program works. You've tested everything in sight. It's time to ship it. So you make a release version.
And the world crumbles to dust.
You get memory access failures, dialogs don't come up, controls don't work, results come out incorrectly, or any or all of the above. Plus a few more problems that are specific to your application.
Now what?
That's what this essay is all about.
Some background
A bit of background: I have been working with optimizing compiler since 1969. My PhD dissertation (1975) was on the automatic generation of sophisticated optimizations for an optimizing compiler. My post-doctoral work involved the use of a highly optimizing compiler (Bliss-11) in the construction of a large (500K line source) operating system for a multiprocessor. After that, I was one of the architects of the PQCC (Production Quality Compiler-Compiler) effort at CMU, which was a research project to simplify the creation of sophisticated optimizing compilers. In 1981 I left the University to join Tartan Laboratories, a company that developed highly-optimizing compilers, where I was one of the major participants in the tooling development for the compilers. I've lived with, worked with, built, debugged, and survived optimizing compilers for over 30 years.
Compiler bugs
The usual first response is "the optimizer has bugs". While this can be true, it is actually a cause-of-last-resort. It is more likely that there is something else wrong with your program. We'll come back to the "compiler bugs" question a bit later. But the first assumption is that the compiler is correct, and you have a different problem. So we'll discuss those problems first.
Storage Allocator Issues
The debug version of the MFC runtime allocates storage differently than the release version. In particular, the debug version allocates some space at the beginning and end of each block of storage, so its allocation patterns are somewhat different. The changes in storage allocation can cause problems to appear that would not appear in the debug version--but almost always these are genuine problems, as in bugs in your program, which somehow managed to not be detected in the debug version. These are usually rare.
Why are they rare? Because the debug version of the MFC allocator initializes all storage to really bogus values, so an attempt to use a chunk of storage that you have failed to allocate will give you an immediate access fault in the debug version. Furthermore, when a block of storage is freed, it is initialized to another pattern, so that if you have retained any pointers to the storage and try to use the block after it is freed you will also see some immediately bogus behavior.
The debug allocator also checks the storage at the start and end of the block it allocated to see if it has been damaged in any way. The typical problem is that you have allocated a block of n values as an array and then accessed elements 0 through n, instead of 0 through n-1, thus overwriting the area at the end of the array. This condition will cause an assertion failure most of the time. But not all of the time. And this leads to a potential for failure.
Storage is allocated in quantized chunks, where the quantum is unspecified but is something like 16, or 32 bytes. Thus, if you allocated a DWORD array of six elements (size = 6 * sizeof(DWORD) bytes = 24 bytes) then the allocator will actually deliver 32 bytes (one 32-byte quantum or two 16-byte quanta). So if you write element [6] (the seventh element) you overwrite some of the "dead space" and the error is not detected. But in the release version, the quantum might be 8 bytes, and three 8-byte quanta would be allocated, and writing the [6] element of the array would overwrite a part of the storage allocator data structure that belongs to the next chunk. After that it is all downhill. There error might not even show up until the program exits! You can construct similar "boundary condition" situations for any size quantum. Because the quantum size is the same for both versions of the allocator, but the debug version of the allocator adds hidden space for its own purposes, you will get different storage allocation patterns in debug and release mode.
Uninitialized Local Variables
Perhaps the greatest single cause of release-vs-debug failures is the occurrence of uninitialized local variables. Consider a simple example:
thing * search(thing * something)
BOOL found;
for(int i = 0; i < whatever.GetSize(); i++)
{
if(whatever[i]->field == something->field)
{
found = TRUE;
break;
}
}
if(found)
return whatever[i];
else
return NULL;
}
Looks pretty straightforward, except for the failure to initialize the found variable to FALSE. But this bug was never seen in the debug version! But what happens in the release version is that the whatever array, which holds n elements, has whatever[n] returned, a clearly invalid value, which later causes some other part of the program to fail horribly. Why didn't this show up in the debug version? Because in the debug version, due entirely to a fortuitous accident, the value of found was always initially 0 (FALSE), so when the loop exited without finding anything, it was correctly reporting that nothing was found, and NULL was returned.
Why is the stack different? In the debug version, the frame pointer is always pushed onto the stack at routine entry, and variables are almost always assigned locations on the stack. But in the release version, optimizations of the compiler may detect that the frame pointer is not needed, or variable locations be inferred from the stack pointer (a technique we called frame pointer simulation in compilers I worked on), so the frame pointer is not pushed onto the stack. Furthermore, the compiler may detect that it is by far more efficient to assign a variable, such as i in the above example, to a register rather than use a value on the stack, so the initial value of a variable may depend on many factors (the variable i is clearly initially assigned, but what if found were the variable?
Other than careful reading of the code, and turning on high levels of compiler diagnostics, there is absolutely no way to detect uninitialized local variables without the aid of a static analysis tool. I am particularly fond of Gimpel Lint (see http://www.gimpel.com/), which is an excellent tool, and one I highly recommend.
Bounds Errors
There are many valid optimizations which uncover bugs that are masked in the debug version. Yes, sometimes it is a compiler bug, but 99% of the time it is a genuine logic error that just happens to be harmless in the absence of optimization, but fatal when it is in place. For example, if you have an off-by-one array access, consider code of the following general form
void func()
{
char buffer[10];
int counter;
lstrcpy(buffer, "abcdefghik");
...
In the debug version, the NULL byte at the end of the string overwrites the high-order byte of counter, but unless counter gets > 16M, this is harmless even if counter is active. But in the optimizing compiler, counter is moved to a register, and never appears on the stack. There is no space allocated for it. The NULL byte overwrites the data which follows buffer, which may be the return address from the function, causing an access error when the function returns.
Of course, this is sensitive to all sorts of incidental features of the layout. If instead the program had been
void func()
{
char buffer[10];
int counter;
char result[20];
wsprintf(result, _T("Result = %d"), counter);
lstrcpy(buffer, _T("abcdefghik"));
then the NUL byte, which used to overlap the high order byte of counter (which doesn't matter in this example because counter is obviously no longer needed after the line using it is printed) now overwrites the first byte of result, with the consequence that the string result now appears to be an empty string, with no explanation of why it is so. If result had been a char * variable or some other pointer you would be getting an access fault trying to access through it. Yet the program "worked in the debug version"! Well, it didn't, it was wrong, but the error was masked.
In such cases you will need to create a version of the executable with debug information, then use the break-on-value-changed feature to look for the bogus overwrite. Sometimes you have to get very creative to trap these errors.
Been there, done that. I once got a company award at the monthly company meeting for finding a fatal memory overwrite error that was a "seventh-level bug", that is, the pointer that was clobbered by overwriting it with another valid (but incorrect) pointer caused another pointer to be clobbered which caused an index to be computed incorrectly which caused...and seven levels of damage later it finally blew up with a fatal access error. In that system, it was impossible to generate a release version with symbols, so I spent 17 straight hours single-stepping instructions, working backward through the link map, and gradually tracking it down. I had two terminals, one running the debug version and one running the release version. It was obvious in the debug version what had gone wrong, after I found the error, but in the unoptimized code the phenomenon shown above masked the actual error.
Linkage Errors
Linkage Types
Certain functions require a specific linkage type, such as __stdcall. Other functions require correct parameter matching. Perhaps the most common errors are in using incorrect linkage types. When a function specifies a __stdcall linkage you must specify the __stdcall for the function you declare. If it does not specify __stdcall, you must not use the __stdcall linkage. Note that you rarely if ever see a "bare" __stdcall linkage declared as such. Instead, there are many linkage type macros, such as WINAPI, CALLBACK, IMAGEAPI, and even the hoary old (and distinctly obsolete) PASCAL which are macros which are all defined as __stdcall. For example, the top-level thread function for an AfxBeginThread function is defined as a function whose prototype uses the AFX_THREADPROC linkage type.
UINT (AFX_CDECL * AFX_THREADPROC)(LPVOID);
which you might guess as being a CDECL (that is, non-__stdcall) linkage. If you declared your thread function as
UINT CALLBACK MyThreadFunc(LPVOID value)
and started the thread as
AfxBeginThread((AFX_THREAD_PROC)MyThreadFunc, this);
then the explicit cast (often added to make a compiler warning go away!) would fool the compiler into generating code. This often results in the query "My thread function crashes the app when the thread completes, but only in release mode". Exactly why it doesn't do this in debug mode escapes me, but most of the time when we look at the problem it was a bad linkage type on the thread function. So when you see a crash like this, make sure that you have all the right linkages in place. Beware of using casts of function types; instead. write the function as
AfxBeginThread(MyThreadFunc, (LPVOID)this);
which will allow the compiler to check the linkage types and parameter counts.
Parameter counts
Using casts will also result in problems with parameter counts. Most of these should be fatal in debug mode, but for some reason some of them don't show up until the release build. In particular, any function with a __stdcall linkage in any of its guises must have the correct number of arguments. Usually this shows up instantly at compile time unless you have used a function-prototype cast (like the (AFX_THREADPROC) cast in the previous section) to override the compiler's judgment. This almost always results in a fatal error when the function returns.
The most common place this shows up is when user-defined messages are used. You have a message which doesn't use the WPARAM and LPARAM values, so you write
wnd->PostMessage(UWM_MY_MESSAGE);
to simply send the message. You then write a handler that looks like
afx_msg void OnMyMessage();
and the program crashes in release mode. Again, I've not investigated why this doesn't cause a problem in debug mode, but we've seen it happen all the time when the release build is created. The correct signature for a user-defined message is always, without exception,
afx_msg LRESULT OnMyMessage(WPARAM, LPARAM);
You must return a value, and you must have the parameters as specified (and you must use the types WPARAM and LPARAM if you want compatibility into the 64-bit world; the number of people who "knew" that WPARAM meant WORD and simply wrote (WORD, LONG) in their Win16 code paid the penalty when they went to Win32 where it is actually (UNSIGNED LONG, LONG), and it will be different again in Win64, so why do it wrong by trying to be cute?)
Note that if you don't use the parameter values, you don't provide a name for the parameters. So your handler for OnMyMessage is coded as
LRESULT CMyClass::OnMyMessage(WPARAM, LPARAM)
{
...do something here...
return 0;
}
Compiler "Bugs"
An optimizing compiler makes several assumptions about the reality it is dealing with. The problem is that the compiler's view of reality is based entirely on a set of assumptions which a C programmer can all too readily violate. The result of these misrepresentations of reality are that you can fool the compiler into generating "bad code". It isn't, really; it is perfectly valid code providing the assumptions the compiler made were correct. If you have lied to your compiler, either implicitly or explicitly, all bets are off.
Aliasing bugs
An alias to a location is an address to that location. Generally, a compiler assumes that unless otherwise instructed, aliasing exists (it is typical of C programs). You can get tighter code if you tell the compiler that it can assume no aliasing, and therefore, values that it has computed will remain constant across function calls. Consider the following example:
int n;
int array[100];
int main(int argc, char * argv)
{
n = somefunction();
array[0] = n;
for(int i = 1; i < 100; i++)
array[i] = f(i) + array[0];
}
This looks pretty easy; it computes a function of i, f(i), which at the moment we won't bother to define, and adds the array entry value to it. So a clever compiler says, "Look, array[0] isn't modified at all in the loop body, so we can change the code to store the value in a register and rearrange the code:
register int compiler_generated_temp_001 =somefunction();
n = compiler_generated_temp_001;
array[0] = compiler_generated_temp_001;
for(int i = 1; i < 100; i++)
array[i] = f(i) + compiler_generated_temp_001;
This optimization, which is a combination of loop invariant optimization and value propagation, works only if the assumption that array[0]is not modified by f(i). But if we later define
int f(int i)
{
array[0]++;
return i;
}
Note that we have now violated the assumption that array[0] is constant; there is an alias to the value. Now this alias is fairly easy to see, but when you have complex structures with complex pointers you can get exactly the same thing, but it is not detectable at compile time, or by static analysis of the program.
Note that the VC++ compiler, by default, assumes that aliasing exists. You have to take explicit action to override this assumption. It is a Bad Idea to do this except in very limited contexts; see the discussion of optimization pragmas.
These are attributes you can add to declarations. For variable declarations, the const declaration says "this never changes" and the volatile declaration says "this changes in ways you can't possibly guess". While these have very little impact when you compile in debug mode, they have a profound effect when you compile for release, and if you have failed to use them, or used them incorrectly, You Are Doomed.
The const attribute on a variable or function states that the value is constant. This allows the optimizing compiler to make certain assumptions about the value, and allows such optimizations as value propagation and constant propagation to be used. For example
int array[100];
void something(const int i)
{
... = array[i];
... = array[i];
}
The const declaration allows the compiler to assume that the value i is the same at points usage 1 and usage 2. Furthermore, since array is statically allocated, the address of array[i] need only be computed once; and the code can be generated as if it had been written:
int array[100];
void something(const int i)
{
int * compiler_generated_temp_001 = &array[i];
... = *compiler_generated_temp_001;
... = *compiler_generated_temp_001;
}
In fact, if we had the declaration
const int array[100] = {... }
the code could be generated as if it were
void something(const int i)
{
int compiler_generated_temp_001 = array[i];
... = compiler_generated_temp_001;
... = compiler_generated_temp_001;
}
Thus const not only gives you compile-time checking, but can allow the compiler to generate smaller, faster code. Note that you can force violations of const by explicit casts and various devious programming techniques.
The volatile declaration is similar, and says the direct opposite: that no assumption of the constancy of a value can be made. For example, the loop
int n;
count++;
}
will be readily transformed by an optimizing compiler as
if(n > 0)
for(;;)
count++;
and this is a perfectly valid translation. Because there is nothing in the loop that can change the value of n, there is no reason to ever test it again! This optimization is an example of a loop invariant computation, and an optimizing compiler will "pull this out" of the loop.
But what if the rest of the program looked like this:
registerMyThreadFlag(&n);
while(n > 0)
{
count++;
}
and the thread used the variable registered by the registerMyThreadFlag call to set the value of the variable whose address was passed in? It would fail utterly; the loop would never exit!
Thus, the way this would have to be declared is by adding the volatile attribute to the declaration of n:
volatile int n;
This informs the compiler that it does not have the freedom to make the assumption about constancy of the value. The compiler will generate code to test the value n on every iteration through the loop, because you've explicitly told it that it is not safe to assume the value n is loop-invariant.
ASSERT and VERIFY
Many programmers put ASSERT macros liberally throughout their code. This is usually a good idea. The nice thing about the ASSERT macro is that using it costs you nothing in the release version because the macro has an empty body. Simplistically, you can imagine the definition of the ASSERT macro as being
#ifdef _DEBUG
#define ASSERT(x) if( (x) == 0) report_assert_failure()
#else
#define ASSERT(x)
#endif
(The actual definition is more complex, but the details don't matter here). This works fine when you are doing something like
ASSERT(whatever != NULL);
which is pretty simple, and omitting the computation of the test from the release version doesn't hurt. But some people will write things like
ASSERT( (whatever = somefunction() ) != NULL);
which is going to fail utterly in the release version because the assignment is never done, because there is no code generated (we will defer the discussion of embedded assignments being fundamentally evil to some other essay yet to be written. Take it as given that if you write an assignment statement within an if-test or any other context you are committing a serious programming style sin!)
Another typical example is
ASSERT(SomeWindowsAPI(...));
which will cause an assertion failure if the API call fails. But in the release version of the system the call is never made!
That's what VERIFY is for. Imagine the definitions of VERIFYas being
#ifdef _DEBUG
#define VERIFY(x) if( (x) == 0) report_assert_failure()
#else
#define VERIFY(x) (x)
#endif
Note this is a very different definition. What is dropped out in the release version is the if-test, but the code is still executed. The correct forms of the above incorrect examples would be
VERIFY((whatever = somefunction() ) != NULL);
VERIFY(SomeWindowsAPI(...));
This code will work correctly in both the debug and release versions, but in the release version there will be no ASSERT failure if the test comes out FALSE. Note that I've also seen code that looks like
VERIFY( somevalue != NULL);
which is just silly. What it effectively means is that it will, in release mode, generate code to compute the expression but ignore the result. If you have optimizations turned on, the compiler is actually clever enough to determine that you are doing something that has no meaning and discard the code that would have been generated (but only if you have the Professional or Enterprise versions of the compiler!). But as we also discuss in this essay, you can create an unoptimized release version, in which case the preceding VERIFY would simply waste time and space.
Optimizing compilers are very sophisticated pieces of code. They are so complex that generally no one person understands all of the compiler. Furthermore, optimization decisions can interact in subtle and unexpected ways. Been There, Done That.
Microsoft has done a surprisingly good job of QA on their optimizing compilers. This is not to say that they are perfect, but they are actually very, very good. Much better than many commercial compilers I've used in the past (I once used a compiler that "optimized" a constant if-test by doing the else if the value was TRUE and the then if the value was FALSE, and they told us "We'll fix that in the next release, sometime next year". Actually, I think they went out of business before the next compiler release, which surprised no one who had ever been a customer).
But it is more likely that a "compiler bug" is the result of your violating the compiler assumptions rather than a genuine compiler bug. That's been my experience.
Furthermore, it may not even be a bug that affects your code. It might be in the MFC shared DLL, or the MFC statically-linked library, where a programmer committed an error that doesn't show up in the debug versions of these libraries but shows up in the release versions. Again, Microsoft has done a surprisingly good job of testing these, but no testing procedure is perfect.
Nonetheless, the Windows Developer's Journal (http://www.wdj.com/) has a monthly feature, "Bug++ of the Month", which features actual, genuine compiler optimization bugs.
How do you get around such bugs? The simplest technique is to turn off all the compiler optimizations (see below). There is an excellent chance that if you do this you will perceive no difference in the performance of your program. Optimization matters only when it matters. The rest of the time, it is a waste of effort (see my MVP Tips essay on this topic!). And in almost all cases, for almost all parts of almost all programs, classic optimization no longer matters!
DLL Hell
The phenomenon of inconsistent mixes of DLLs leads to a condition known affectionately as "DLL Hell". Even Microsoft calls it this. The problem is that if Microsoft DLL A requires Microsoft DLL B, it is essential that it have the correct version of DLL B. Of course, all of this stems from a desire to not rename the DLLs on every release with a name that includes the rev level and version number or other useful indicators, but the result is that life becomes quite unbearable.
Microsoft has a Web site that allows you to determine if you have a consistent mix of DLLs. Check out http://msdn.microsoft.com/library/techart/dlldanger1.htm for articles about this. One of the nice features is that much of this is going away in Win2K and WinXP. However, some of it is still with us. Sometimes the release version of your code will be done in by a mismatch whereas the debug version is more resilient, for all the reasons already given.
However, there is one other lurking problem: a mix of DLLs that use the shared MFC library, and are both debug and release. If you are using DLLs of your own, that use the shared MFC library, make certain that all your DLLs are either debug or release! This means you should never, ever, under any circumstances rely on PATH or the implicit search path to locate DLLs (I find the whole idea of search paths to be a ill-thought-out kludge which is guaranteed to induce this sort of behavior; I never rely on the DLL load path except to load the standard Microsoft DLLs from %SYSTEM32%, and if you are using any kind of search path beyond that you deserve whatever happens to you! Note also that you must not, ever, under any circumstances imaginable, ever, put a DLL of your own in the %SYSTEM32% directory. For one thing, Win2K and WinXP will delete it anyway, because of "System32 Lockdown", a good idea that should have been forcefully implemented a decade ago).
Do not think that doing "static linking" of the MFC library is going to solve this problem! In fact, it actually makes the problem much worse, because you can end up with n disjoint copies of the MFC runtime, each one of which thinks it owns the world. A DLL must therefore either use the shared MFC library or use no MFC at all (the number of problems that occur if you have a private copy of the MFC library are too horrible to mention in an otherwise G-rated Web page, and in the interest of preserving keyboards I won't describe them in case any of you are eating when you read this. Well, how about one: the MFC Window Handle Map. Do you really want two or more copies of a handle map, each one of which can have disjoint images of what the window handle mapping, and try to reconcile the behavior of your program? I thought not).
However, it is very important to not have a mix of debug and release DLLs using MFC (note that a "straight", non-MFC release DLL can be called from a debug version of an MFC program; this happens all the time with the standard Microsoft libraries for OLE, WinSock, multimedia, etc.). The debug and release DLLs also have sufficiently different interfaces to MFC (I've not looked in detail, but I've had reports about problems) that you will get LoadLibrary failures, access faults, etc.
Not A Pretty Sight.
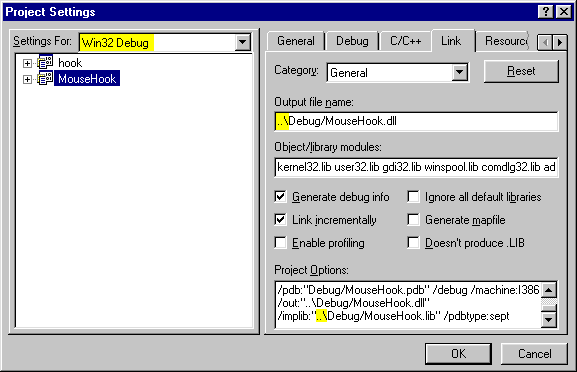
One way to avoid this is to have your DLL subprojects compile the DLLs into the main program's Debug and Release directories. The way I do this is to go into the DLL subproject, select Project Settings, select the Link tab, and put "..\" in front of the path that is there. You have to do this independently in the Debug and Release configurations (and any custom configurations you may have).
I also hand-edit the command line to put the "..\" in front of the path for the .lib file, making it easier to link as well.
Note the yellow areas highlighted in the image below. The top left shows the fact that I am working in the Debug configuration. The middle right shows the edit I made to the output file, and the lower right shows the hand-edit I made to redirect the .lib file.
Diagnostic Techniques
So the program fails, and you haven't a clue as to why. Well, there's some tricks you can try.
Turn off optimizations
One thing you can do is turn off all the optimizations in the release version. Go to the Project | Settings for the release version, choose the C/C++ tab, select Optimizations in the combo box, and simply turn off everything. Then do Build | Rebuild All and try again. If the bug went away, then you have a clue. No, you still don't know if it was an optimization bug in the strict sense, but you now know that the bug in your program is a consequence of an optimization transformation, which can be as simple as an uninitialized stack variable whose non-initialized value is sensitive to the optimization of the code. Not a lot of help, but you now know something more than you did before.
You can debug a release version of the program; just go into the C/C++ tab, select the General category, and select Program Database for Edit and Continue. You must also select the Link tab, and under the General category, check the Generate Debug Information box. In particular, if you have turned off optimization you have the same debugging environment that you had for the debug version, except you are running with the non-debug MFC shared library, so you can't single-step into the library functions. If you have not turned optimizations off, there are ways in which the debugger will lie to you about variable values, because the optimizations may make copies of variables in registers and not tell the debugger. Debugging optimized code can be hard, because you really can't be sure of what the debugger is telling you, but you can be further ahead with symbols (and line backtrace) than without them. Note that statements can be reordered, pulled out of loops, never computed, etc. in an optimized version, but the goal is that the code is semantically identical to the unoptimized version. You hope. But the rearrangement of the code makes it very difficult sometimes for the debugger to tell the exact line on which the error occurred. Be prepared for this. Generally, you'll find the errors are so blindingly obvious once you know more-or-less where to look that more detailed debugger information is not critical.
Enable/Disable Optimizations Selectively
You can use the Project | Settings to change the characteristics of a project selectively, on a file-by-file basis. My usual strategy is to disable all optimizations globally (in the release version), then selectively turn them back on only in those modules that matter, one at a time, until the problem reappears. At that point, you've got a good idea where the problem is. You can also apply pragmas to the project for very close optimization control.
Don't optimize
Here's a question to ask: does it matter? Here you are with a product to ship, a customer base, a deadline, and some really obscure bug that appears only in the release version! Why optimize at all? Does it really matter? If it doesn't, why are you wasting your time? Just turn off optimizations in the release version and recompile. Done. No fuss, no muss. A bit larger, a bit slower, but does it matter? Read my essay about optimization being your worst enemy.
Optimize only what counts
Generally, GUI code needs little or no optimization, for the reasons given in my essay. But as I point out in that essay, the inner loops really, really matter. Sometimes you can even selectively enable optimizations in the inner loop that you wouldn't dare enable globally in your program, such as telling a certain routine that no aliasing is possible. To do this, you can apply optimization pragmas around the routine.
For example, look in the compiler help under "pragmas", and the subtopic "affecting optimization". You will find a set of pointers into detailed discussions.
inline functions
You can cause any function to be expanded inline if the compiler judges this to have a suitable payoff. Just add the attribute inline to a function declaration. For C/C++, this requires that the function body be defined in the header file, e.g.,
class whatever {
public:
inline getPointer() { return p; }
protected:
something * p;
}
A function will normally not be compiled inline unless the compiler has been asked to compile inline functions inline, and it has decided it is OK to do so. Go read the discussion in the manual. The compiler switches which enable optimization of inline expansion are set from the Project | Settings, select the C/C++ tab, select the Optimizations category, and select the type of optimization under the Inline function expansion dropdown. Usually doing /Ob1 is sufficient for a release version. Note that if your bug comes back, you've got a really good idea where to look.
intrinsic functions
The compiler knows that certain functions can be directly expanded as code. Functions that are implicitly inlineable include the following
_lrotl, _lrotr, _rotl, _rotr, _strset, abs, fabs, labs, memcmp, memcpy, memset, strcat, strcmp, strcpy, and strlen
Note that there is very little advantage to implicitly expanding one of these to code unless it is already in a time-critical part of the program. Remember the essay: measure, measure, measure.
An intrinsic function often makes the code size larger, although the code is faster. If you need it, you can simply declare
#pragma intrinsic(strcmp)
and all invocations of strcmp which follow will be expanded as inline code. You can also use the /Oi compiler switch, which is set by Project | Settings, C/C++ tab, category Optimizations, and if you select Custom, select Generate Intrinsic Functions. You will probably never see a bug which occurs in optimized code because of intrinsic expansions.
Note that coding strcmp as a function call in your code can be a seriously losing idea anyway, if you ever think you might build a Unicode version of your app. You should be writing _tcscmp, which expands to strcmp in ANSI (8-bit character) applications and _wcscmp in Unicode (16-bit character) applications.
Really Tight Control
If you have a high-performance inner loop, you may want to tell the compiler that everything is safe. First, apply any const or volatile modifiers that would be necessary. Then turn on individual optimizations, such as
#pragma optimize("aw", on)
This tells the compiler that it can make a lot of deep assumptions about aliasing not being present. The result will be much faster, much tighter code. Do NOT tell the compiler, globally, to assume no aliasing! You are very likely to do yourself in because you have systematically violated this limitation all over the place (it is easy to do, and hard to find if you've done it). That's why you only want to do this sort of optimization in very restricted contexts, where you know you have total control over what is going on.
When I have to do this, I usually move the function to a file of its own, and only the function I want to optimize can therefore be affected.
Summary
This outlines some rationale and strategies for coping with the debug-vs-release problems that sometimes come up. The simplest one is often the best: just turn off all the optimizations in the release version. Then selectively turn on optimizations for that 1% of your code that might matter. Assuming there is that much of your code that matters. For a lot of the applications we write, so little code matters that you get virtually the same performance for optimized and unoptimized code.
Other References
Check out http://www.cygnus-software.com/papers/release_debugging.html for some additional useful insights by Bruce Dawson. A particularly nice point he makes here is that you should always generate debug symbol information with your release version, so you can actually debug problems in the product. I don't know why I never thought of this, but I didn't!
The views expressed in these essays are those of the author, and in no way represent, nor are they endorsed by, Microsoft.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





