Introduction
As a C# developer, I spend most of my day working in Visual Studio. So whenever I find some daily task that requires me to work in a different tool, I generally try to see if I can design a way to integrate it into VS.NET by creating an add-in. One of the things I like to do several times a week is read the various Blogs that the good people at Microsoft write (you can find a list of Microsoft blogs at http://blogs.gotdotnet.com). But as I became a reader of more and more blogs, it has become a hassle to manually look at each blog to see if the author has written anything new.
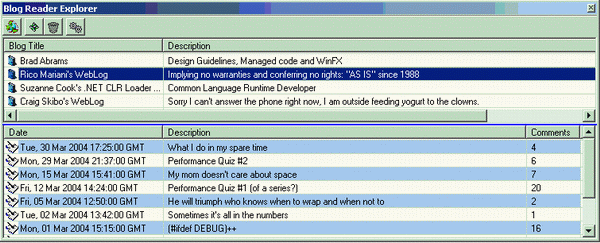
So what I decided to do was create a VS.NET add-in that would do it for me. When the add-in loads, it downloads the latest RSS feeds for all the blogs that I have subscribed to, and shows the title and publish date of each entry for each blog. The add-in stores the date of the last time you looked at an entry for each blog and highlights all new entries in red. You can look at the single blog entry by double clicking the entry, you can see all the comments for the entry by right clicking on the entry and clicking ‘View Entry Comments’, or you can open the blog’s home page by right clicking on the entry and clicking ‘View Whole Blog’. The UI for the add-in utilizes the Visual Studio .NET Window object so that I can get the docking and pinning functionality that other windows like the Command or Solution Explorer windows enjoy.
What is and isn’t covered in the article
The “How to create an Add-In” horse has been beat to death and is now dog food, so that’s not what I want to focus on with this article. First I’m going to cover the functionality and design of the tool. Then I’ll go into a brief overview of what RSS is and the XML format for RSS version 2.0. Then I’m going to talk about some of the more interesting areas of .NET that I used while writing the tool, including the IsolatedStorage namespace, downloading data from the internet, calling multiple asynchronous delegates (and the challenges of synchronizing them back up in a VS.NET add-in), and then some more advanced Visual Studio add-in features such as using the Globals objects for application setting storage, as well as creating your own window that integrates into VS.NET (like the Watch or Solution Explorer windows).
Blog Reader Design
The design of the Blog Reader tool is fairly simple. I’ve created two entity classes called Blog and BlogEntry, with a one-to-many relationship between them. These two classes, big surprise, represent a blog and an entry for a blog respectively. I have an ArrayList of Blog objects that the Add-In holds, and each Blog object has an ArrayList of BlogEntry objects. I’ve also written a helper class called BlogRetriever who’s sole purpose in life is to connect to the blog’s URL and download the RSS XML content.
The application startup process flow first reads each blog URL from an application data file (via IsolatedStorage). It then creates a connection to the Internet and downloads the RSS content for each blog, and parses the XML, creating and populating the Blog and BlogEntry objects, adding them to the appropriate ArrayList.
When I first wrote this tool, I added 10 different blogs to my list of subscribed blogs, but when I launched the add-in it took a really long time to load all the data and create the Blog and BlogEntry objects. So I thought I’d try to download and populate each blog with its own thread. I was able to do this via using an asynchronous delegate, which cut down the load time of the add-in significantly (I’ll cover the details of calling asynchronous delegates later).
So what is RSS?
RSS stands for “Really Simple Syndication”, and is an XML format that was originally mostly used for syndicating news content from news web sites, but has become a standard for many blogging web sites to publish their blog content. I’m not going to cover the complete (or anywhere near the complete) 2.0 specification of RSS. You can read that for yourself at http://blogs.law.harvard.edu/tech/rss. An example of an RSS feed is shown below.
The XML format for RSS is pretty simple to understand. There is a root <RSS> element that surrounds the entire document. Right under this element is one <CHANNEL> element, which contains sub elements that describe the topic of the entire document, such as title, link, and description, as well as other options sub elements.
Under the <CHANNEL> element, there are multiple <ITEM> elements, one for each entry or “story”. This element will contain several sub elements that describe that individual story, such as title, publish date, description, author, and comments among others.
The Blog Reader tool only looks for a necessary subset of elements contained within the <CHANNEL> and the <ITEM> elements in order to display the desired information.
Block of RSS from MSDN
<rss version="2.0">
<channel>
<title>MSDN: .NET Framework and CLR</title>
<link>http://msdn.microsoft.com/netframework/</link>
<description>The latest information for developers on
the Microsoft .NET Framework and Common Language Runtime
(CLR).</description>
<language>en-us</language>
<ttl>1440</ttl>
<item>
<title>Creating a Product Search Application Using the
eBay SDK and Visual Basic .NET</title>
<pubDate>Fri, 26 Mar 2004 08:00:00 GMT</pubDate>
<description>Learn how to create a .NET Windows
Forms application that searches eBay's product database
using the eBay SDK.</description>
<link>http://msdn.microsoft.com/vbasic/default.aspx?pull
=/library/en-us/dv_vstechart/html/ebaySearchBar.asp</link>
</item>
<item>
<title>.NET Enterprise Services Performance</title>
<pubDate>Fri, 26 Mar 2004 08:00:00 GMT</pubDate>
<description>See the performance of native COM+ and
.NET Enterprise Services components applied to different activation and
calling patterns, and get guidelines to make .NET Enterprise Services
components execute just as quickly as C++ COM+ components.</description>
<link>http://msdn.microsoft.com/netframework/default.aspx
?pull=/library/en-us/dncomser/html/entsvcperf.asp</link>
</item>
</channel>
</rss>
Downloading the RSS data
Downloading data from the Internet is fairly easy with .NET, and can be done with as little as 4 lines of code, as shown below.
HttpWebRequest webreq = (HttpWebRequest)WebRequest.Create(blog.Link);
webreq.Credentials = new NetworkCredential(
Settings.UserName, Settings.Password);
HttpWebResponse webresp = (HttpWebResponse)webreq.GetResponse();
StreamReader rss = new StreamReader(
webresp.GetResponseStream(), Encoding.ASCII);
if (rss != null)
{
blog.ParseRSS(rss.BaseStream);
rss.Close(); }
First start out by creating an HttpWebRequest object by calling the static WebRequest.Create() method. This method can either take a string of the URL you want to call, or an instance of a System.Uri class. If you sit behind a firewall and need to authenticate to get out to the Internet, you’ll also need to create an instance of the NetworkCredential class, and assign it to the HttpWebRequest.Credentials property. Next you call the HtteWebRequest.GetResponse() method, which will call the URL and return to you a WebResponse object, which you can cast to an HttpWebResponse. From this object you can call the HttpWebResponse.GetResponseStream() method to gain access to the data stream that you requested.
I usually use a StreamReader, which is a forward only, read only reader for the underlying stream (though you can access and fully manipulate the underlying stream through the StreamReader.BaseStream property). In this case, I pass the stream into each blog’s Blog.ParseRSS() method, which will pull the XML out of the stream and parse the RSS content (I’ll talk about in the next section).
Once you are finished with the HttpWebResponse’s stream, you should close it because if you don’t, you could cause your application to run out of http connections. To do this, you can either call HttpWebResponse.Close() or StreamReader.Close(). Since they both work with the same underlying stream instance it doesn’t matter which one you call. It can’t hurt to call both, but it’s not necessary.
If your server is behind a Proxy server then you might also need to provide proxy information for the HttpWebRequest object. This can be done in one of 3 ways. First, if you store proxy information in your IE Internet Options settings, then .NET by default should pick these settings up and use them. The way it does this is through the machine.config file. In the machine.config file there is a <proxy>element (shown below), which by default has the ‘usesystemdefault’ attribute set to true.
If you don’t store proxy information in your IE Internet Options, then you could set the ‘usesystemdefault’ attribute to false, then provide the optional ‘proxyaddress’ attribute and define the Uri to the proxy server, as shown below.
<defaultProxy>
<proxy usesystemdefault="false" proxyaddress="
http://myproxyserver:80" bypassonlocal="true"/>
</defaultProxy>
The final way to define proxy settings is to do it in the code. Just before you call HttpWebRequest.GetResponse(), you can set the HttpWebRequest.Proxy property with an instance of a WebProxy object, as shown below.
webreq.Proxy = new WebProxy("http://myproxyserver:80", true);
Parsing RSS XML
Once you have the RSS xml data you need to be able to parse through it and pull out the content data that you need. I played around with several different ways to parse through the RSS data; looping through the nodes via the DOM (XMLDocument), query each desired element with XPath, and reading the XML in a forward only stream with the XmlTextReader. Using the DOM is definitely the easiest to use, but definitely not the fastest. XPath was just a pain in the butt, and not too fast when you need to read most of the elements in an XML document. I finally settled on the XmlTextReader for its speed and relative ease of use. The XmlTextReader is a forward only, read only, stream based xml parser. Once the xml is loaded into the reader, you start reading by calling the XmlTextReader.Read() method. This will return a true if the next element in the document was successfully read. This makes it perfect to use as your condition for a while() loop, as shown below..
public void ParseRSS(Stream rss)
{
XmlTextReader xml = null;
xml = new XmlTextReader(rss);
while (xml.Read())
{ if (xml.Depth == 2 && xml.Name == "title" &&
xml.IsStartElement("title"))
{
xml.Read();
this.title = xml.Value;
continue;
}
if (xml.Depth == 2 && xml.Name == "description" &&
xml.IsStartElement("description"))
{
xml.Read();
this.description = xml.Value;
continue;
}
.
.
.
}
}
The XmlTextReader is a bit odd to get used to though. Each time you call the Read() method it moves forward to the next element, which sounds simple enough. Lets take the following XML block for example:
<one>
<two>something</two>
</one>
What I want to do is get the value “something” from between the opening and closing <two> tags. The first time Read() in called, the reader moves to the first element <one>. The next time Read() is called, the active element is <two>. You would think that now <two> is active you could just call the Value property of the reader, but if you do, you’ll just get an empty string. The thing to keep in mind with the XmlTextReader is that it literally moves to the next element. The opening and a closing tag are both elements, but the text in between these two tags is an element as well. So when <two> is the active element, you have to call Read() one more time in order to get the text “something”. Now, when you call Read() again, the active element title is <two> again. So when looking for the opening element you need to also check for the XmlTextReader.IsStartElement() method. If the element is the closing element, then this method will return false. You can see this in the code above, for each “if” statement.
Another thing to keep in mind is when you are looping through an XML document such as RSS, where it has multiple elements with the same names, such as <title>, but at different levels within the XML document. If you look at the example RSS XML at the beginning of the article, you’ll notice that both the “<channel>” and the “<item>” elements have sub elements called <title> and <description>.
The XmlTextReader won’t give you the fully qualified path of the element that you’re on, but it will give you the depth in the XML document. This is something else you’ll need to check for when trying to parse an RSS document. Otherwise, you might pull the wrong information at the wrong place. I demonstrate this as well in the code example above.
Storing Application Data: Isolated Storage
Most applications, at least good user-friendly applications, provide a way to store off data and user preference about the desired state of the application. There are many ways to do this, but Microsoft has written an entire little known namespace specifically for this task; its called System.IO.IsolatedStorage.
Isolated storage in an incredibly easy way to store application data and keep it isolated from other applications and their data files. You don’t have to worry about what directory the file is stored in because .NET takes care of all those nasty details for you. Isolated storage is, by default, based on the user’s identity and the assembly name. This means that if the same user has two different applications open, and each one reads and writes their own data file via isolated storage, then the two data files are isolated for each other because even though the two applications share the same user, they have different assembly names.
Isolated storage, currently, is based on a folder structure that is located under C:\Documents and Settings, but is a little different for each OS version. For example, on my Windows 2000 server the root isolation storage folder is located at:
C:\Documents and Settings\ME\Local Settings\Application Data\IsolatedStorage
When you create a file using Isolated Storage, then additional folders will be created below this root folder, each folder name based (probably) on a hash of the Isolated Storage scope (user name, AppDomain, assembly name, etc). For example, the full path to the data file that I create for the Blog Reader is:
C:\Documents and Settings\ME\Local Settings\Application Data\IsolatedStorage\fsaap1nt.yj0\wpdgvfj1.plj\ Url.rqiojpb01nxfmst5zbyphw4tyzj0qs5w\ AssemFiles\BlogReader.dat
What does each of these folders mean? I don’t know and I don’t need to know. That’s the beauty of isolated storage; you don’t have to worry about the details. Just create a file and write to it, and presto, that’s it!
So lets start with an example of creating and writing to Isolated Storage. The code below is how the Blog Reader loops through each of the saved blogs and stores the blog URL and last date checked to the isolated storage file.
using (IsolatedStorageFile file =
IsolatedStorageFile.GetUserStoreForAssembly())
{
using (StreamWriter stream = new StreamWriter(
new IsolatedStorageFileStream("BlogReader.dat",
FileMode.Create, file)))
{{
foreach (Blog blog in blogs)
{ stream.WriteLine(blog.Link + "|~|" + SerializeDateTime(blog.LastChecked));
}
stream.Flush();
stream.Close();
}}
}
We first start with creating an IsolatedStorageFile object. Remember I was talking about a file store based on the isolated file scope? Well, you can specify what scope you want to create the file under, or just use the statically defined scope of assembly and user that is returned by IsolatedStorageFile.GetUserStoreForAssembly().
Once we have the file object, we create an IsolatedStorageFileStream object, based on the IsolatedStorageFile. We give the file a name, “BlogReader.dat”, and then tell Isolated Storage to create a new file. If the file already exists, then isolated storage will just overwrite it with the new one. Then we create a StreamWriter for easy writing to the file stream.
Once we have the StreamWriter, we can just use the StreamWriter.WriteLine() method to write the blog url and the last date it was checked. After every blog url has been written to the stream, we flush the contents of the stream to the file, then close the stream.
Reading from Isolated Storage is just as easy. Below is how the Blog Reader reads the blog urls when it starts.
using (IsolatedStorageFile file =
IsolatedStorageFile.GetUserStoreForAssembly())
{
string[] files = file.GetFileNames("BlogReader.dat");
if (files.Length > 0 && files[0] == "BlogReader.dat"))
{
using (StreamReader stream = new StreamReader(
new IsolatedStorageFileStream("BlogReader.dat",
FileMode.Open, file)))
{ while (stream.Peek() > -1)
{
string line = stream.ReadLine();
int index = line.IndexOf("|~|");
Blog blog = new Blog(
line.Substring(0, index), UnSerializeDateTime(line.Substring(index + 3)));
blogs.Add(blog); }
}
}
}
First we start out by creating an instance of an IsolatedStorageFile, just like we did when we were saving the data. Now, before we open the data file, we need to check and see if it exists. This is where I think Isolated Storage falls a bit short. There isn’t a FileExists method or anything close. The closest thing Microsoft gave us is the IsolatedStorageFile.GetFileNames() method. So we first have to query Isolated Storage for any files that match our file name. If we find one, then we create an instance of IsolatedStorageFileStream, based on the file name, the file mode of FileMode.Open, and the instance of IsolatedStorageFile. Then we crate a StreamReader object based on the IsolatedStorageFileStream object, and loop through each line in the data file and create a Blog object.
Notice that I never had to specify a folder name? That’s what I like about Isolated Storage so much, it handles the file path for you, and stores the data files in a fairly out of the way place. Now keep one thing in mind. Just because one application can’t read another applications Isolated Storage file by using the Isolated Storage API, that doesn’t mean you cant just navigate to it through Windows Explorer and open the file with Notepad. So if you are going to store any ‘sensitive’ information, you still need to encrypt it, just like you would with any other data store.
Storing add-in preferences via Globals object
Isolated Storage is great, but if you need to store off small chunks of data like user preferences for a Visual Studio add-in, then the Visual Studio automation model provides a built in way to handle this: the Globals object. The Globals object provides a way to persist user information, between Visual Studio sessions, at the Project, Solution, or IDE level.
This can be useful you write an add-in that has user preferences that differ based in each separate project or solution. The Solution.Globals property exposes a Globals object that will store off data in the .sln file. And the Project.Globals property exposes a Globals object that will store off data in the .csproj file.
But if you want your add-in to store off data that is global to all projects and solutions, then the DTE.Globals object is the way to go. Data that is written to this object are stored in a file called ExtGlobals.dat, which is easily readable with notepad, and can be located at:
C:\Documents and Settings\ME\Application Data\Microsoft\VisualStudio\7.1\ExtGlobals.dat
Writing and reading to the Globals object is much easier than to Isolated Storage. Its best to think about the Globals object as a hashtable. You read and write a variable through its indexer, using the same key / value pattern used by the hashtable class. The only thing that you must remember is if you create a new variable in the Globals object, you must follow it with the Globals.set_VariablePersists(“variable name”, true) method. This will tell Visual Studio to persist the variable to the file. Below is an example of storing three variables using the DTE.Globals object
vsObj.Globals["PW"] = Settings.Password;
vsObj.Globals["UN"] = Settings.UserName;
vsObj.Globals["OPEN"] = Settings.OpenBrowserInNewWindow.ToString();
vsObj.Globals.set_VariablePersists("PW", true);
vsObj.Globals.set_VariablePersists("UN", true);
vsObj.Globals.set_VariablePersists("OPEN", true);
Reading from the Globals object is just as easy. The only thing to remember is to check to see if the Globals object contains the variable you are requesting, before you actually try to access it (otherwise it’ll throw an exception). Below is an example of reading three variables out of the Globals object.
if (vsObj.Globals.get_VariableExists("PW"))
Settings.Password = vsObj.Globals["PW"].ToString();
if (vsObj.Globals.get_VariableExists("UN"))
Settings.UserName = vsObj.Globals["UN"].ToString();
if (vsObj.Globals.get_VariableExists("OPEN"))
Settings.OpenBrowserInNewWindow =
bool.Parse(vsObj.Globals["OPEN"].ToString());
Again, a security note. Above I show code that saves user names and passwords with the Globals object for demonstration purposes only. But the solution, project, and ExtGlobals.dat files are easy to read and understand. In real life I wouldn’t store anything this valuable without encrypting it first.
Using asynchronous delegates with add-ins
At the beginning of the article, I mentioned that in order to get a decent load time for the add-in, I needed to kick off several threads that download each of the RSS feeds asynchronously. Calling delegates asynchronously is a great method to use if you have several independent steps in a process that must be completed before you can continue on with the program. The following diagram demonstrates what I mean.

One thing to keep in mind though, if your server only has a single processor, creating background threads to process multiple steps asynchronously wont really make your app run faster if you have to synch back up before the program can continue. This is because all threads will have to share the same processor, so in effect, the same amount of work needs to complete on the processor before the program can continue. And most likely, the program will actually run slower because of the overhead of calling the multiple delegates, creating new threads (if needed, asynchronous delegates get their threads from the ThreadPool), all the extra context switching that goes on switching between threads, as well as the effort to synch back up.
I’m going to assume that you know the basics of how to use a delegate in a synchronous manner. Calling a delegate asynchronously is just as easy. Once you have your delegate instance, invoke it by calling its myDelegate.BeginInvoke() method. There are several ways to go about kicking off your asynchronous delegate and then synching back up. If your program needs a ‘fire and forget’ model, then just call BeginInvoke() and continue on as normal. A thread will be pulled from the ThreadPool to execute the delegate and then be returned to the pool when the method your delegate calls is finished.
If you need to collect the return value from the method your delegate called, then there are two main ways to do this. The first method is to provide an instance of an AsyncCallback delegate as the second to last parameter of the BeginInvoke() method. This callback delegate will be called when the asynchronous delegate thread is finished executing. You’ll also need to pass in a ‘state’ object as the last parameter to the BeginInvoke() method. This ‘state’ object will get stored in the instance of the IAsyncResult that is returned from the BeginInvoke() method. This ‘state’ object will also be stored by the runtime so when you call the delegate’s EndInvoke() method, it can return the correct object.
Lets give an example. Lets say your program kicks of 3 different asynchronous delegate calls, each call based on the same delegate class, which has a return type of string. When the delegate that finishes executing first completes, and the callback method gets called, the runtime passes to the callback method the same instance of the IAsyncResult object that was returned when BeginInvoke() was called. You then call the delegate’s EndInvoke() method, passing in the IAsyncResult instance. The runtime uses the state object that is stored in the IAsyncResult to figure out which string to return. I demonstrate this below.
private delegate string DoStuffEventHandler(int one, int two);
DoStuffEventHandler do1, do2, do3;
private void DoAsyncDelegate()
{
do1 = new DoStuffEventHandler(DoStuff);
do2 = new DoStuffEventHandler(DoStuff);
do3 = new DoStuffEventHandler(DoStuff);
IAsyncResult result1 = do1.BeginInvoke(1, 2,
new AsyncCallback(DoStuffCallback), "first");
IAsyncResult result2 = do2.BeginInvoke(3, 4,
new AsyncCallback(DoStuffCallback), "second");
IAsyncResult result3 = do3.BeginInvoke(5, 6,
new AsyncCallback(DoStuffCallback), "third");
}
private string DoStuff(int one, int two)
{
return ((int)(one + two)).ToString();
}
private void DoStuffCallback(IAsyncResult result)
{
switch (result.AsyncState.ToString())
{
case "first":
textBox1.Text = do1.EndInvoke(result);
break;
case "second":
textBox2.Text = do2.EndInvoke(result);
break;
case "third":
textBox3.Text = do3.EndInvoke(result);
break;
}
}
The second way to get a result back from an asynchronous delegate call is to use the IAsyncResult.WaitHandle property that is returned from BeginInvoke(), and use either the instance method WaitHandle.WaitOne() for each IAsyncResult or the static method WaitHandle.Wait.All() on an array of all the IAsyncResult.WaitHandle objects. Then, when the process returns from the WaitOne() or WaitAll() method calls, you are safe to call the delegate’s EndInvoke, following the same pattern I layout above.
There is one other way to get the return type of an asynchronous delegate call. You can also check the IAsyncResult.IsCompleted property in a loop to see if the asynchronous call has finished. Once IsCompleted returns a true, you could then call EndInvoke() to get the return value. This is generally discouraged because it’s heavier on the processor and is considered really poor design.
In the case of the BlogReader, I pass in an instance of the Blog class to the delegate, and all changes that the new thread does are done to the Blog instance. Because what I’m passing to the delegate is nothing but a reference to an existing object, I don’t need to worry about the delegate returning anything to me via a callback method. Another reference to the Blog instance is stored in my ArrayList of blogs, which is why I don’t need a callback to return the populated Blog back to the main UI thread.
Because the next step in the application, after downloading the RSS data and building my Blog object graph, is to display the contents of the Blog objects, I have to wait until all threads have finished working. Otherwise, I wont have anything to display to the user. Remember I talked about the return type of a BeginInvoke() being an object of type IAsyncResult? Well, to do what we want, we need to collect each IAsyncResult.WaitHandle object from each BeginInvoke(), and load them into an array. Once we have this array if WaitHandles, normally we could call the static WaitHandle.WaitAll(arrayOfWaitHandles) and that would block the calling thread until all the asynchronous delegate threads were finished working. But Visual Studio.NET is a STA (single threaded apartment) threading model, which does not support the WaitHandle.WaitAll() functionality. So what I had to do was loop through each of the WaitHandle objects in the array and call the WaitHandle.WaitOne() instance method for each one. The first WaitHandle in the array that calls WaitOne() will cause the Main UI thread to pause for a second or two because its still executing, but the rest of the WaitOne() method calls will return quickly because by that point in time they should have already finished executing. This is shown below.
WaitHandle[] handles = new WaitHandle[blogs.Count];
int count = 0;
foreach (Blog blog in blogs)
{
BlogRetriever blogGet = new BlogRetriever();
GetBlogDataEventHandler blogDelegate =
new GetBlogDataEventHandler(blogGet.GetBlogData);
handles[count++] = blogDelegate.BeginInvoke(
blog, null, null).AsyncWaitHandle;
}
foreach (WaitHandle handle in handles)
handle.WaitOne();
Shim control to create a window in Visual Studio .NET
Creating your own form in an add-in is a simple way to create a tool that integrates into Visual Studio, but doesn’t have a very ‘professional’ look to it. Most professional add-ins use Visual Studio Window objects to house their tools. A Window object is used for such floating / docking Visual Studio windows such as Class View, Solution Explorer, Watch window, Breakpoints window, Task List. These are all Visual Studio Window objects.
The Visual Studio Window object itself doesn’t do very much. It just hosts an ActiveX control, which is what you are using with you use VS tools like the Command or Class View window. The problem with creating your own tool window in C# is that a Window object can only host an ActiveX control. And as far as I know, you can’t create an ActiveX control with C# or VB.NET. But lucky for me, someone decided to create a C++ ActiveX control that can host a .NET User Control. There is a free control, called a ‘shim’ control, that you can download from the Yahoo Visual Studio Add-In news group at http://groups.yahoo.com/group/vsnetaddin/. You’ll have to sign up for the group, but once in, go to the Files / Visual Studio Shim Controls section. There are two shim controls for you to choose from, both unsupported. One is from Microsoft and the other written by Xtreme Simplicity. For this tool and article I chose to use the one by Xtreme Simplicity.
The API for creating a new tool window is the method Windows.CreateToolWindow(). The parameters are shown below. The first parameter is the instance of the add-in that is running. This object in passed into the add-in’s OnConnection method, and you should store it off in a class level variable so it can be used here. The second parameter is the ProgID of the ActiveX shim control that you are using. The third parameter is the caption of the tool window. The forth parameter is a Guid that you create manually, and it becomes the unique identifier for the new window in the DTE.Windows collection. The forth parameter, normally, would be the instance the ActiveX control that the window will host. But with the shim control, you just pass in a reference to a null object..
public Window CreateToolWindow(
AddIn AddInInst,
string ProgID,
string Caption,
string GuidPosition,
ref object DocObj
);
My assumption is that if the fifth parameter is null, then Visual Studio will create a new instance of the ActiveX control, because after you pass in the null object into CreateToolWindow(), it suddenly is an object of type System.__ComObject, which is what .NET tells you most COM VS automation objects are.
After you call CreateToolWindow(), you then use reflection on the fifth parameter (the newly created ActiveX shim control instance) to invoke it’s method HostUserControl(). The code for all this is shown below. Notice the last parameter of the InvokeMember method. When you call HostUserControl, you pass in an object array that only contains the .NET user control that you created. The ActiveX shim control will take this .NET user control, and display the .NET user control inside the ActiveX control.
object obj = null;
Window window = vsObj.Windows.CreateToolWindow(addIn,
"CSUserControlHost.CSUserControlHostCtl", caption, guid, ref obj);
window.Visible = true;
obj.GetType().InvokeMember("HostUserControl",
BindingFlags.InvokeMethod, null, obj, new object[]
{yourWindowToolDotNetControl});
This is how the Blog Reader tool displays its user interface, via the shim control hosting my user control. To see all the code on how to do this look at Connect.CreateToolWindow() in the source.
The finished product with the window floating
The finished product with the window docked to the bottom
Add-in startup and shutdown patterns
Like I said at the beginning of the article, the ‘How to create an add-in’ article has been beat to death and then some. So I don’t plan to continue the punishment. But there is one aspect about add-in creation that is often left out. Many articles or sample add-ins will create a new CommandBar and Menu items (Command objects) when they startup. But they don’t do any teardown actions when you unload the add-in. A well-behaved add-in should clean itself up graphically when it gets unloaded, otherwise you get orphaned menu items loitering about, with no functionality behind them. This, as you can imagine, can get fairly annoying after the fifth sample add-in that you’ve installed and then uninstalled.
The problem is that the VS.NET will keep any new menus that you programmatically create, even if you shut down VS. So if your add-in doesn’t manually remove CommandBars or menus from VS when you unload the add-in, you are left with menu items that don’t do anything.
There is a common pattern that I implement into all my add-ins’ Connect classes (I should make an interface called IGoodBehavinAddIn shouldn’t I). I’m wont go the code explicitly, just describe the pattern. You can read through the Connect class to see exactly how I implement this pattern. The main point is I want people to keep in mind that an add-ins’ teardown code is just as important as setup code.
When the Blog Reader add-in starts up, it first checks to see if the ‘Blog Reader’ menu item command exists in VS. If it does still exist, it won’t try to create a new one, which will help speed up the add-ins’ load time (as well as keep VS from having 10 ‘Blog Reader’ menu items). If your add-in creates several Command and / or CommandBar objects, you should just have to check for one object. If it still exists in VS then you can be 99% sure that the rest of them exist. If they don’t exist, then you have to programmatically create them.
When VS is closed, your add-ins’ OnDisconnection method will be called and a disconnection mode enum will be passed in. What I like to do is only remove the add-in from Visual Studio if the user has manually unloaded the add-in via the ‘Add-In Manager’. You can determine this by checking for the disconnection mode of ext_dm_UserClosed. If OnDisconnection is called for any other reason, I leave the add-in loaded as is.
One final note to keep in mind when creating add-ins. By default the MSI project that is created for you when you use Visual Studio’s Add-In wizard has several of the COM dll dependencies marked as ‘Excluded = false’ in the property window for each dll. This means that the MSI package will install and register the COM dll with the MSI is run, and it will unregister and remove the COM dll when the add-in is uninstalled. This can be very bad! If these dll’s are removed from a server that has Visual Studio .NET installed on it, Visual Studio .NET will cease to work. This is why you always should set the Exclude property to true for every dll that the wizard automatically adds to the MSI package.
I have been a professional developer since 1996. My experience comes from many different industries; Data Mining Software, Consulting, E-Commerce, Wholesale Operations, Clinical Software, Insurance, Energy.
I started programming in the military, trying to find better ways to analyze database data, eventually automating my entire job. Later, in college, I automated my way out of another job. This gave me the great idea to switch majors to the only thing that seemed natural…Programming!


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 










