Introduction
When I
started developing, change handling was easy. "Never change a running
system" worked as a guideline that made sure we developers would release
only at specified times (like once a year) to make the release as smooth and
easy as possible. Well, unfortunately it hardly ever was that smooth.
Having only
a single release a year made it really important to finish your feature until
then. If it wasn't 100% complete, well, you had to hope nobody would notice.
You'd try to get it out anyway.
As a result,
these big bangs were devastating. There were releases where the platform was
offline days after the big bang, and we tried to integrate bugfixes for all the
things that only showed up on live and were not reproducible on our dev-machines.
A first
thing we noticed even back then was, that the bugfix-releases where less
chaotic, faster and better then the first big bang release. At the end of a
big-bang session, usually after two weeks of pizza, coke and no sleep, we might
have released 5-6 times, and each time it went smoother than before.
We ignored
that enhancement at first. We needed sleep, some time with our families, and decided that
releasing is stupid because it makes us work hard.
Fortunately
enough, smarter people than your humble writer, like Jez Humble and David
Farley for instance, decided that this is a stupid way to go. They had a new
way: Continuous Delivery.
Continuous
Delivery (to quote Jez and David on this) “is the practice of releasing
every good build to users”<w:sdt id="-900829453" citation="t"> (Humble & Farley, 2010), which means that if
you want to go live only once a year, you’d have to either violate your coding
guidelines (which usually states something like "deliver good code"), or never commit to the trunk.
It was closely followed by another friend with the word “continuous” in it – Continuous Integration. This requires
the dev to (to quote the mastermind of the internet, Wikipedia, on that one) “merge all developer copies with the
mainline several times a day”.
Doing this,
and having a Continuous Integration pipeline in place, makes it really easy for
you to see if a build is good, because it turns green. From releasing once a
year, it seems like you are at a point where you’d release a dozen times a day. At
least in theory.
In practice
you are working on features, and features are hardly ever finished after 10min,
but usually after weeks. If you regularly commit all changes for a feature that is not complete to the mainline, your fellow devs, QAs, and
automated test suites will most probably hang you for breaking the build all
the time.
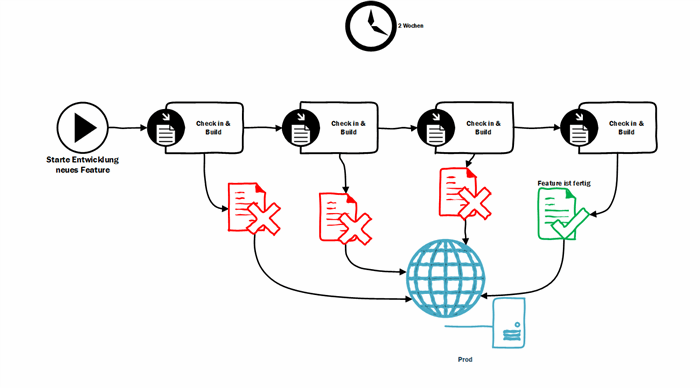
Figure 1: Some features just don't like to be finished in minutes
In the end,
you would not get any faster. When working with multiple teams, it might even
prevent releasing anything at all, because when multiple teams are working on
multiple features, at least one of the features might be in an unstable state.
So let’s
take a look into the solutions to this dilemma.
Release
in Small Little Steps
This is the
best practice solution. You try to plan your story around tasks, which takes at
most one day to finish, and show them to the customer immediately. It’s a
perfect solution, that in my experience does not work very well for a lot of scenarios
in the day-to-day business.

Figure 2: I told her to release in small steps, but she
just wouldn't listen | (source: Office Royality Free Images)
When
working with a product, you will have constraints – dependencies to other teams,
upstream/downstream dependencies for which you must wait, marketing stunts for
new features that require you to show the new feature at a specific date, or the
requirement to test the new feature on a selected group before showing it to
everybody.
Branch By
Abstraction
Branch by
Abstraction is the application pattern with the stupidest name ever, because it
might lead to the idea of branches in your version-control which it is not.
The idea
behind it is easy – identify your concern, add an abstraction layer between
your application and the old stuff that is handling this concern, and implement
your new way for this abstraction. Once your new way is implemented, just throw
the lever and the new thing is working.
The branch
by abstraction pattern is very similar to the Strategy Design Pattern, so you
might already have an idea of how to implement it. It is an excellent choice if you have to replace parts of the application, like switching to a new database, moving to
the cloud (which might require you to rethink all your local storage thingies)
and stuff like that.
The good
thing – while you were working on the new implementation, the build was good
all the time, even though you integrated to the mainline all the time.
Furthermore,
this approach gives you the possibility to release in small steps in some
scenarios, thus routing all requests that are already implemented by the new
approach.
This
abstraction layer can help you to enhance your code, by separating concerns and
thus introducing a lower coupling and a stronger cohesion.
In most cases however, this
additional layer will introduce some unnecessary complexity. If you have
no reason to keep this layer (because this part may change again in the future)
it is generally a good practice to remove it after the implementation, and
directly use the new way. Your code will most probably still be prettier than before, because you had to identify a concern and decouple it.
Feature
Branches
Now we are
at a point where we actually branch. Feature Branches evolve around the idea
that each functional implementation is done in its own branch. The branches are
pushed to the central repository, so each feature branch is available for each
developer.
Once the implementation
is done, the developer starts a pull-request, and the changes are discussed in
the team and merged to the master.
Figure 3: Feature Branches - They look simple as long
as fewer than 200 people are doing it in parallel on one class
This has a
lot of advantages – code you are working on does not influence the master, so
you can work independently. Additionally, if you are working with a client application,
where the binaries are delivered to the customer, this is a very cheap way to
ensure the code cannot be activated by the client.
Though you
have to make sure that feature-branches are not long-lived. If they are
long-lived, and you have a lot of devs/teams with a lot of branches, you
may run into a big scary merge again.
As I favor
pairing over reviews, I consider the communication required at a pull request as
overhead.
Furthermore,
and this my personal opinion, it does not automatically force you to decouple
your functionality. And enforcing low coupling – high cohesion is something I
love.
Feature
Toggles
Feature
Toggles are basically boolean values for a specified feature-state. What you do
is wrapping your new logic into an if-statement, and the old block into the
else. It might look like something like this:
if (Feature.IsEnabled(„KillerFeature")) {
// awesome!
} else {
// boring…
}
To be
honest, this does not look very nice. It seems to cries out: “technical debt”,
“testing complexity” and “broken code”.
Now let’s
pick the technical debt first. It’s
true that by this simple if/else, you create a whole region that is not used
by your application. It’s basically unused code, that’s still compiled and
shipped.
But it
helps you – once the feature is completed – to simply remove everything inside
the else (and all the dependencies that were only used inside the else). Thus, code zombies may actually become less in a feature toggled environment - at least in my experience. The technical depth therefore is more a “technical debt credit”
you take before starting with the feature, and that you pay back at the end of
the feature, with an “all unused code easy to remove” interest earned.
Furthermore,
this technical depth allows us to role forward when something went wrong on
live, we can just set the feature to false again.
Broken code, the fear that a half-implemented feature would
break your productive system, is very real. You need to have tests in place,
from Unit over Acceptance to Regression, to make sure no change will ever bring
down your system.
However, this is true for every other change you do in code.
The testing complexity was nicely overcome in our
first approach to feature toggles: The state of the Feature at
AutoScout24, where I first worked with feature toggles, was set in the
configuration. This resulted in the following scenario: A feature is on or off, but never
both. Which allowed us to limit the impact of the toggle – only one state had to
be tested.
The
workflow for this setup is like that:
Figure 4: It's a nice feeling to block others only for
a short time instead of forever
You push code
with the toggle value set to true, try to get it through your pipeline, and if
it fails you toggle the toggle and won’t block anybody else.
Probably
the biggest Pro for Feature Toggles in my opinion is something you can enforce:
allow a single feature to be toggled only at one location.
Now why is
that a pro? It requires you to question your design, and to separate the
concerns to a very explicit level. If you can’t toggle a feature at only one
point, the feature is either not a very good user story, or your code has a certain smell to it.
While in
the first case, it’s probably too late (because trying to toggle your code means
planning is done and you are already doing it), but in the second case you can start refactoring. The
strategy pattern is usually a good starting point.
One of the
downsides might be that in a client application, you deploy
every code to the client, and the client would be able to switch it on or off
if he’d ever look into the config. Which might not be what you want for very
immature features.
Another
downside of featuretoggles is the danger of nesting – you might accidently nest
one feature in another one, which introduces a lot of problems and even more complexity; for one, you
need to toggle a toggle to see another feature that has nothing to do with it,
and testing such a scenario is nasty, I can tell you so much.
In
my opinion however, it is worth all the hassle, due to the fact that you can really do
continuous integration (by committing every change to the master), continuous
delivery (by not breaking everything all the time) and keep your code nice.
Feature
Bee
While having
our feature state in the configuration was a very safe and convenient way of
releasing our features, we found that we had two smells with this configuration:
- No Separation of Concerns – SoC: we were doing it wrong. Releasing both code and features with one
deployment made us slow. Each time we toggled a toggle, our live-release took
longer because a lot of manual work in the form of the acceptance was involved.
Furthermore, this tight coupling prevented an automatic deployment to our
Production.
Also, setting up the feature toggles and transforming the configuration was included
in our build-pipeline, and also into our regression tests. - PO was not able to do his job – The configuration was with the source code,
and while it was only a yaml file, not every PO in the company was consent to
edit files in the source repository.
- Condition/Claim-Based releases where tricky – AutoScout24 is an international
company, with marketplaces in multiple countries – but with one shared codebase
(which, by itself is kind of a smell, but that’s another topic).
Some features are released in smaller countries to a percentage of the users first
to test the impact. This is done by Optimizely, which would work with Frontends
only. Backend changes, like changing the search indexer, always required manual
coding effort.
To overcome
these issues, we had to change our approach to a different setup – together with Philipp, another developer at AutoScout24,
I started a new Project called FeatureBee. This project aims to fix the three
issues.
In a
nutshell, FeatureBee is a single button to release a feature.
Figure 6: A button – the Idea behind FeatureBee
In more
detail: it’s a Server with an API and a UI, and a lot of clients who ask the
server for the status.
Installing
the Client in a .NET Application is quite simple – call
Install-Package FeatureBee
in your nuGet
console, set the server URL in your configuration and add
FeatureBeeBuilder.ForWebApp().UseConfig();
in your
global.asax.cs. A more complete documentation can be found in the github wiki
for the project.
The application
itself is very intuitive to use – it’s a Board with Post-Its on it:
Figure 7: If you ever succeeded in moving a Post-It,
you are ready to use FeatureBee
With this
simple UI, we introduced a major change in the way we work: While with the
configuration, where each environment may have a different feature state, each
environment has the same feature state. A second after you move your
post-it, the feature is live. A lot of people complained that this is an awfully short period for
testing new features.
At first, we
thought about simply releasing the feature automatically for all people inside
the company, ignoring the state on the board. But then we would have
introduced another problem – by decoupling code and feature releases, we would
have to validate that each possible feature state is tested – So this required us
to think of a way to allow PO, QAs and the automatic tests to switch feature on
and off for only themselves to test the feature before switching it on.
We solved
this by adding a tray to each of our pages. This tray shows all the features currently
available, their state and a button to switch them on or off:
Figure 8: Buttons are PO's best friends
This simple
implementation changed another thing: we are now discussing if we really need
a QA – Environment, because with this tray everybody can do the acceptance on
the live system.
Already though
it helps us to introduce automatic live-deployments, and thus a more mature continuous
deployment.
Bottom
Line
At
AutoScout24, we are currently using all the approaches presented above, and we
try to find the most pragmatic solution for each scenario.
While
Feature-Branches allow us to quickly work and share states that are too simple
to be toggled, but too complex to be implemented in an hour, we use
FeatureToggles/FeatureBee as soon as acceptance is required, we use Branch By
Abstraction for every bigger change, and add a toggle for the place where we
switch implementations, and “release in small bits” whenever possible.
Join the
FeatureBee Team
Feature Bee
is the only centralized .NET FeatureToggle Solution we know of. It’s been used
in an international organization, and thus is able to handle millions of
pageviews per day.
We at
AutoScout24 have come to think that a project like this may be interesting for
other developers and companies as well, so we added a MIT Licence and put it on gitHub.
Fork it,
make your changes, and send pull requests, and we’ll love to take it.
See you when
we switch your feature on. ;)
Copyright
Pictures not marked explicitly are created by the author and licensed under MIT.
Born, raised and killed by skynet I stopped worrying and started to code my own skynet whose sole purpose it will be to revenge my death by running over the terminator with a bobby car


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 









{kind=link}