Introduction
NTFS - "New Technology File System" is the preferred native file system for Windows NT series. It is a more sophisticated, powerful and complicated file system than FAT file system. It is much efficient for larger disks. There are many tools out in Internet for recovering deleted files from NTFS, but I couldn't find one with source, by now. I created this tool to satisfy my curiosity, and I'm presenting to all of you having the same interest. Here is the tool with source. Have fun.
In this article, I shall explain:
- A few details of NTFS. I'm not explaining from scratch. This explanation looks kind of an additional patch work for documentations available on the net.
- The tool design.
- The class usage and lacking features.
NTFS
Microsoft says NTFS is a fast performing and journaling file system. It is a fast performing and sophisticated file system. Journaling file system means it can recover from sudden crashes (may be, Microsoft knows long before, their OS will crash more often :)) ). For explanation of journaling, see the LogFile section below. NTFS provides several things to Windows than the FAT, for example: Security, Large storage, etc.
NTFS starts with MFT (Master File Table). It is a lookup table like FAT (File Allocation Table) in FAT file system. NTFS boot sector points to this table. Therefore, whenever system boots up, it reads the boot sector, finds the MFT, and loads it before any file operation. Unlike FAT, it can reside any where in the disk. Like FAT, there are two MFT for each NTFS file system. Normally, the first resides in the beginning, and second MFT, called mirror MFT, resides in the middle part of NTFS disk.
The following figure illustrates the layout of an NTFS volume when formatting has finished.

MFT
All the files in the NTFS have a record in representing MFT. What I mean file is system files, directories, normal files, hidden files, etc. Even MFT and mirror MFT have a record in them. The first and second records in the MFT are MFT itself and mirror MFT respectively. First 16 records in MFT are reserved for system files. Every record in MFT is of the same size. A record of MFT normally spans up to 1024 bytes. MFT record size can vary. The size in bytes per MFT record is indicated in the boot sector (i.e., in BPB). The figure below shows the overall picture of how MFT and system files are organized.
- $LogFile: Log file is to make the file system recoverable. The log file is a system file so that it can be found early in the boot process and used to recover the volume. All the transactions will be logged before it is performed on the disk. On system failure in the transaction, the part that has been completed must be undone or rolled back. The rollback operation returns the file system to a previously known and consistent state, as if the transaction had never occurred. (This will never recover your unsaved data :) )
- $Volume: The volume name, NTFS version, and other information about the volume.
- $AttrDef: A table of attribute names, numbers, and descriptions. MFT attributes are defined here, allowing extensibility.
- $: It is for the root folder. All the folders and files listing (only listing) come under this.
- $Bitmap: It is a record of bits. Each bit represents a block in the file system, which indicates if that block is free or not.
- $Boot: This record contains the bootstrap code for the volume, if this is a bootable volume.
- $BadClus: Record contains the bad sector location in the volume.
- $Quota: Disk quota usage for each user on a volume.
- $Upcase: Used for converting lowercase characters to the matching Unicode uppercase characters. This is very useful when searching the file system.
Under NTFS, all information is organized into attributes of header and data parts. Even the above system files also build with attributes. The difference from normal file/folder to system file is the file name and the functionality. System files always start with dollar sign ($). See the following figure. It depicts a simple file extraction from its corresponding record in MFT. Every record consists of attributes. To do the file processing, first, its corresponding record should be located in the MFT. Then the attributes within that record should be processed to retrieve the information about the file. After that only, it is possible to do any processing on that file.
Any attributes in record in MFT can be classified into two categories.
- Resident attribute: This category of attribute contains its data within the record itself. When the file is very small, it can be fitted within the record. Therefore, when the system reads this record, it reads the data also. For this file, OS doesn't have to access the disk again, once after reading the record. Here, as soon as you look up the file, it's there for you to use.
- Non-resident attribute: The attributes of larger size than the MFT record are put in to this category. This category holds the actual data of the attribute some where in the disk. This data may be fragmented. Even the data runs may be in different places. Attribute's header holds only the data run pointer not the data itself. Once after reading this record, OS needs to access the disk again to retrieve the data.
The following figure shows the method to extract data from non-resident attributes by reading data runs.
Attribute Types
Once after reading and extracting the data from the disk, by following the data run, it should be processed according to the Attribute Type. There are many attributes available. Here I'm explaining a few of them.
- Standard Information attribute: This attribute contains DOS File Permissions (file attributes) and the file times. Windows 2000 introduced four new fields which are used to reference Quota, Security, File Size and Logging information.
- Filename attribute: As its name suggests, this not only contains name, it also contains DOS File Permissions (file attributes), file times, Unicode long file name/short file name, allocated size, and real size of the file. It is a repeatable attribute for both long and short filenames. The long name of the file can be up to 255 Unicode characters. The short name is the MS-DOS- readable, eight-plus-three, case-insensitive name for this file.
- Security Descriptor attribute: This contains ACLs and SIDs for security. Shows information about who can access the file, who owns the file, and so on. This is obsolete from Window 2000. The Windows 2000 version of NTFS stores all security descriptors in the $Secure metadata file, sharing descriptors among files and directories that have the same settings. Previous versions of NTFS stored private security descriptor information with each file and directory.
- Attribute List attribute: This specifies the location detail of additional MFT records, if needed.
- Bitmap attribute: This file attribute is a sequence of bits, each of which represents the status of an entity. Provides a map representing records in-use on the MFT or folder. Mostly used by large directories.
- Extended Attributes and Extended Attribute Information: Extended attributes aren't actively used but are provided for backward compatibility with OS/2 applications.
- Index root and Index allocation attribute: Directories are very much like files in NTFS. If the directory is small enough, the index to the files to which it points can fit in the MFT record in an attribute called the Index Root attribute. If enough entries are present, NTFS will create a new extent with a non-resident attribute called an index buffer. In such directories, the index buffers contain what is called a “b+ tree”, which is a data structure designed to minimize the number of comparisons needed in order to find a particular file entry. A b+ tree stores information (or indexes to that information) in a sorted order. At points in the directory, NTFS stores sorted groups of entries and pointers to entries that fall below those entries in the sort. This has many advantages over storing entries in whatever order they happen to fall. For example, if you want a sorted list of the entries in the directory, your request is satisfied quickly because that is the order of storage in the index buffer. If you want to look up a particular entry, the lookup is quick because the trees tend to get wide, rather than deep, which minimizes the number of accesses necessary to reach a particular point in the tree.
How to Undelete?
This is simple in NTFS when you know the file structure and the way to read them. When you get the record of any file from the MFT, on its header, you can see a field saying flags (wFlags). If this flag has bit one set, it means that the file is in-use, else it is deleted. On deleted file ignoring this bit, if you continue the data run, you can get the file content. That's it. Create a new file and write that on to it. File recovered. You don't need special mechanism to read any deleted file unless it's been over written.
Tool design
Mainly, this tool is made up of two classes. These classes are very useful to read the NTFS files. Those classes are:
CMFTRecord class: This is the lowest class which does the file reading and attribute extraction.CNTFSDrive class: This class loads the MFT table and manipulates the file according to the user request.
See the following class diagram for more detail on each of these classes.
The following figure depicts how CNTFSDrive handles the CMFTRecord class for file extraction.
Usage of CNTFSDrive class
This class should be initialized with the starting sector of NTFS. I.e., the boot sector of the NTFS. In this tool, to pass that, I got a small part of code from the Forensic article by Vinoj Kumar, in CodeGuru. Sufficient modification I did on this code, and took only the part which reads the partition table and passes the starting sector relative to the beginning of the physical disk. It is necessary to set properties: Dive Handle and NTFS starting sector before Initialize, because on Initialize, the class loads the MFT into the memory. Here is the summarized usage of CNTFSDrive class to extract a file from NTFS:
CNTFSDrive::ST_FILEINFO stFInfo;
BYTE *pData;
DWORD dwBytes =0;
DWORD dwLen;
...
...
...
m_hDrive = CreateFile("\\\\.\\PhysicalDrive0",
GENERIC_READ,
FILE_SHARE_READ|FILE_SHARE_WRITE,
0,
OPEN_EXISTING,
0,
NULL);
m_cNTFS.SetDriveHandle(pDlg->m_hDrive);
m_cNTFS.SetStartSector(StartingRelativeSector,512);
nRet = m_cNTFS.Initialize();
if(nRet)
{
... error...
}
nRet = m_cNTFS.GetFileDetail(100,stFInfo);
if(nRet)
{
... error...
}
...
stFInfo,szFilename;
stFInfo,n64Create;
stFInfo,n64Modify;
stFInfo,n64Modfil;
stFInfo,n64Access;
stFInfo,dwAttributes;
stFInfo,n64Size;
stFInfo,bDeleted;
...
nRet = m_cNTFS.Read_File(100,pData,dwLen);
if(nRet)
{
...error...
}
HANDLE hNewFile = CreateFile( stFInfo,szFilename,
GENERIC_WRITE,
0,
NULL,
CREATE_ALWAYS,
stFInfo.dwAttributes,
0);
nRet = WriteFile(hNewFile,pData,dwLen,&dwBytes,NULL);
if(!nRet)
{
... error...
}
CloseHandle(hNewFile);
CloseHandle(m_hDrive);
...
...
Using the tool:
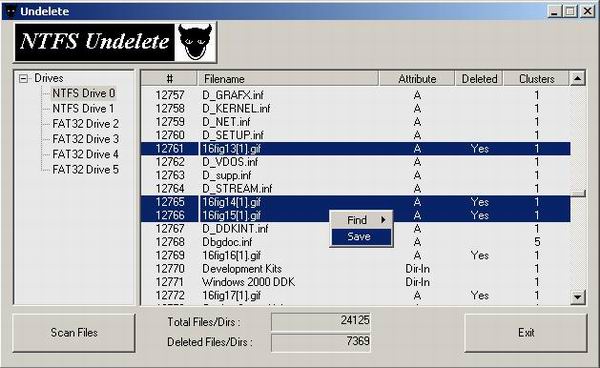
First, you must select a NTFS drive. This is not capable to scan FAT drives. Then click "Scan Files". Scanning may take a few minutes depending on your drive size. Now on the displayed list, right click and save the file. Deleted files are marked "Yes" under the "Deleted" column.
Features missing
Until now, this class is incomplete. For example, features like reading a compressed file is missing in this version. I thought of implementing it. May be when I have time in the future. Following were the features in my initial plan. :)
- Encrypted file reading and extracting
- Compressed file reading and extracting
- Distinguishing directory in display and extracting whole files in a directory in a single click
- FAT12, FAT16 and FAT32 undelete
Conclusion
Certainly, NTFS is a perfect file system available for modern operation systems, but there is little good documentation available on Internet. Here are the few sites you can find more information about NTFS than in MSDN:
I tested this tool on NTFS 3.0 and I hope this will work on NTFS 3.1.
That's all for now. Hope you enjoyed my article. Thanks for your patience ;).
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






