Table of Contents
Introduction
This article describes the development of the library for performing text search based on Boolean search queries. Boolean search query contains a list of search terms combined with the operators of Boolean logic (AND, OR , NOT). Examples:
"test"
"foo AND bar"
"foo AND (bar OR test)"
"foo AND NOT bar"
For example, this approach is used in the web search engines. The purpose of our library is to determine if given text matches given search query. Also, information about positions of found terms in input text may be useful.
Before evaluating search query, we must find all occurrences of search terms in input text. There are several algorithms for string matching. The next section of this article is dedicated to choosing an appropriate algorithm for our library.
Choosing String Matching Algorithm
Simple String Matching
First, let’s consider the simplest possible algorithm for string matching. Let’s assume, we have a string S and a sought string (or pattern) M. The simplest string matching algorithm works as follows:
For each possible offset k within a string S (k is a number in range from 0 to len(S) - len(M)) compare characters S[k] .. S[k + len(M) - 1] with corresponding characters from the sought string (M[0] .. M[len(M) - 1] ).
This algorithm is illustrated in the following picture.
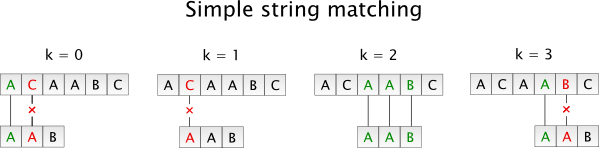
The running time of simple string matching is O(len(M) * (len(S) - len(M) - 1)).
The major problem with the described algorithm is that it discards the information that was acquired for previous values of k. For example, if we are searching for the substring M = “aaab” and we have found a match at offset k = 0, there certainly cannot be any match at offsets 1, 2, 3 becauseS[4] = ‘b’.
There are several effective string matching algorithms that use the information about previous matches. All of them perform some kind of pre-processing of the sought string before the search phase.
Knuth-Morris-Pratt algorithm (KMP Algorithm)
Knuth-Morris-Pratt algorithm is one of the most popular effective string matching algorithms. To use the information about previous matches, KMP algorithm uses a prefix function. Prefix function stores the information about how sought pattern matches itself after the shift. This information can be used to skip unnecessary comparisons.
Prefix function f(q) for the pattern M defines the longest proper prefix of string M[0..q-1] which matches its suffix.
Prefix function for string “ABABAA”:
| q | 1
| 2
| 3
| 4
| 5
| 6
|
f(q)
| 0
| 0
| 1
| 2
| 3
| 1
|
The following picture illustrates how prefix function is used to accelerate string matching:

As shown in the picture, q = 5 characters from the pattern were matched at offset s = 4, but the 6-th character wasn’t matched. Knowing that q characters were matched, we can skip offsets which are certainly invalid. For example, offset s + 1 is certainly invalid, because we already know that character at offset s + 1 matches with second pattern character and it won’t match with the first pattern character. On the other hand, we cannot skip offset s + 2, because first 3 pattern characters match with 3 last checked characters from previous offset.
If q symbols were matched at offset k and (q + 1)-th symbol wasn’t matched, then the next possible valid offset is k + (q - f(q)), where f is a prefix function.
Knuth-Moriss-Pratt algorithm can be represented as a finite state machine:
State 0 is an initial state, state 6 is an acceptance state (which corresponds to the discovery of the sought string). When k-th pattern character is matched, transition to state k + 1 occurs (green arrows).When k-th pattern character isn’t matched, the prefix function determines the next state (red arrows). The function used to determine the next state after the failed match is sometimes called failure function.
Performance:
- Computing prefix function - O(len(M)), where M is a sought string.
- Searching - O(len(S)) where S is an input string.
Aho-Corasick Algorithm
Aho-Corasick algorithm is a generalization of Knuth-Morris-Pratt algorithm for searching multiple patterns in input string. The algorithm uses a finite state machine, which is based on the data structure called prefix tree (ot trie).
Prefix tree for a set of strings contains a node for each string that is a prefix for some string from that set. All children of a particular node have a common prefix of the string associated with that node.
Failure function for Aho-Corasick algorithm is defined as the longest suffix that is also a prefix of any string from a prefix tree. The next picture shows the prefix tree for strings “hers”, “his”, “she”. Red arrows represent failure transitions.
Performance:
- Computing failure function - O(n), where n is the sum of lengths of sought words
- Searching - O(len(S)) where S is an input string
Aho-Corasick algorithm effectively solves the problem of the multiple strings searching. It will be used in our library.
Implementation
Searching consists of 3 stages:
- Building an expression tree from a search query. This tree is used for extracting search terms and for evaluating query result
- Scanning input text for occurrences of search terms
- Evaluation of a search query
Expression Tree
Each node of the expression tree represents the sub-expression or individual search term.
Expression (defined in expressions.hpp) is the base abstract class for all expression tree nodes. It defines several methods and the most important of them are:
evaluate() - This method checks if the expression, which corresponds to this node, is truechildrenCount(), child() – These methods give access to node’s child nodes.
There are several classes which inherit Expression:
SoughtExpression – represents a node which corresponds to individual search term. All leaf nodes in expression tree are instances of SoughtExpression. SoughtExpression contains a list of positions where corresponding search term was found in the input text. This list is filled during the text scanning stage. SoughtExpression::evaluate() returns true if match list isn’t empty.
AndExpression, OrExpression, NotExpression – represent the nodes which correspond to the logical operators. Their evaluate() method calls evaluate() for all child nodes and combines them with a corresponding logical function.NearExpression – checks if offsets for their sub-expressions is close enough.
Expression Parser
The purpose of Expression Parser class is to build an expression tree from a given query string. It uses parser automatically generated by bison++ tool from the grammar definition (parser_impl.y). bison++ is an extension to GNU bison tool that can generate parser in C++ class. You can download bison++ for win32 here: http://www.kohsuke.org/flex++bison++/. The generated parser code is located in parser_impl.hpp and parser_impl.cpp files.
Search query language specification:
Supported operators:
| a AND b | Search terms a and b are present in input text |
| a OR b | At least one search term is present in input text |
| NOT a | Search term a isn’t present in input text |
| a NEAR /n b | a and b are both present in input text and distance between them is not greater than n |
| |
Operator priority:
- NOT
- AND
- NEAR
- OR
Other:
- Brackets “()” can be used to define priorities
- Quotation marks are used to define the expression that should be found exactly as it is
- Backslash is used to quote special symbols
String Matcher Implementation
Aho-Corasick pattern matching algorithm implementation consists of 2 classes:
typedef std::pair< std::wstring, Expression* > Match;
typedef std::set< Match > MatchList;
typedef stdext::hash_map< wchar_t, ACPMMachineState* > StatesHash;
typedef std::queue< ACPMMachineState* > StatesQueue;
struct ACPMMachineState {
ACPMMachineState();
ACPMMachineState( const ACPMMachineState* parent, wchar_t character );
wchar_t character_;
StatesHash transitions_;
MatchList output_;
const ACPMMachineState* parent_;
ACPMMachineState* failure_;
};
class ACPMMachine {
public:
ACPMMachine();
~ACPMMachine();
void addPattern( const std::wstring& pattern, Expression* associatedObject );
void computeStates();
bool feedCharacter( wchar_t );
const MatchList& getCurrentMatch() const;
void reset();
private:
ACPMMachine( const ACPMMachine& );
ACPMMachine& operator= ( const ACPMMachine& );
private:
static ACPMMachineState* FindTransition ( ACPMMachineState* state, wchar_t character );
static void AddTransition ( ACPMMachineState* from, ACPMMachineState* to );
private:
ACPMMachineState* currentState_;
ACPMMachineState* root_;
};
BooleanMatcher
BooleanMatcher connects pattern matcher with expression tree. Each time a match is found, it updates corresponding expression tree node. Also, it acts as a facade to represent the library interface. The following sequence diagram shows how BooleanMatcher interacts with other classes:
Usage
#include <cstdio>
#include "matcher.hpp"
int main(int argc, char** argv)
{
const wchar_t query[] = L"foo AND ( bar OR quux )";
ExpressionParser parser(query, wcslen(query), false);
BooleanMatcher matcher(parser, false);
const wchar_t text[] = L"jdfhgusdhfgjksdghrfjhiodfjgbkldfhfootuxcklnvsdh
sduibarrgysiudfhguisdhrt iv";
const wchar_t* ptr = text;
while (*ptr++)
{
matcher.feedCharacter(*ptr);
}
if (matcher.evaluate())
{
printf("evaluate() == true\n");
MatchType res;
matcher.match(res);
printf("Match positions:\n");
for(int i = 0; i < res.size(); i++)
{
printf("offset - %I64d, size - %d\n", res[i]._pos, res[i]._size);
}
}
else
{
printf("evaluate() == false\n");
}
}
References
- Thomas H. Cormen; Charles E. Leiserson, Ronald L. Rivest, Clifford Stein (2001). Introduction to Algorithms
- Aho, Alfred V.; Sethi, Ravi; and Ullman, Jeffrey D., Compilers: Principles, Techniques and Tools
- bison++ tutorial http://www.mario-konrad.ch/index.php?page=20024
ApriorIT is a software research and development company specializing in cybersecurity and data management technology engineering. We work for a broad range of clients from Fortune 500 technology leaders to small innovative startups building unique solutions.
As Apriorit offers integrated research&development services for the software projects in such areas as endpoint security, network security, data security, embedded Systems, and virtualization, we have strong kernel and driver development skills, huge system programming expertise, and are reals fans of research projects.
Our specialty is reverse engineering, we apply it for security testing and security-related projects.
A separate department of Apriorit works on large-scale business SaaS solutions, handling tasks from business analysis, data architecture design, and web development to performance optimization and DevOps.
Official site: https://www.apriorit.com
Clutch profile: https://clutch.co/profile/apriorit


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





