Introduction
Tagging is fairly commonplace on the internet, especially on blogging sites. It eliminates things like "Which folder should this go into?", and makes it possible to search for pictures, video, blogs, hideous monsters, music, and other useful data in a fairly quick and efficient manner.
However, on desktop computers, it's less common. Certain file formats, like JPEG and MP3, support tags natively, but not all file formats do, meaning that, if you wanted to tag all of your pictures of Cookie Monster (Don't lie, I know you have some), you would be forced to make sure that every single picture was "Cookie Monster.jpg", not "Cookie Monster.png".
I imagine most people don't do this; which means that in order to find their pictures, they put them into relevant folders; "Cookie Monster", "Elmo", "Big Bird", etc. This is where the horrible, horrible, 1st-world problem comes in: "Wait! What happens if I have a picture with Cookie Monster and Elmo? What do I do then?".
So, under threat of having a messy pictures folder, I fired up Visual Studio, and wrote ASH, a program which manages a database of all of the pictures in a given folder, and assigns tags per-image. Why is it called "ASH"? Because I was watching Evil Dead II at the time and Ash's name seemed arbitrary enough to be used for a program. And I forgot to turn off the caps-lock key. And it sounds kind of mysterious. Yeah...
ASH has support for adding, removing, modifying, and searching images from its database, meaning that you can find your pictures of Cookie Monster relatively efficiently simply by searching "blue monster".
Why not [Insert Superior Database Software Here]?
A couple of reasons, none of them really rational (or even good):
- [ISDBSH] is for boring office people
- The developers of [ISDBSH] (falsely) believe that the Evil Dead Trilogy was really, really lame and under-budget
- [ISDBSH] doesn't understand the importance of Sesame Street, and regards Bert and Ernie as "just an entry in the database" (Not that ASH understands either [YET], but it's something to think about.)
Background
The initial development of ASH took place over about 2 weeks, mostly at one in the morning, with a whole bunch of breaks during for Mountain Dew and general procrastination. Its structure was ripped-off of modeled after Booru sites (or, at least, how I guessed a Booru site might work), so from the very start I built it to work as a sort of server-type-thing rather than a standalone-type-thing.
At its heart, ASH is based off of a custom database format, which consists of a 9-byte header followed by 1 kilobyte "blocks". Each block contains a 260-byte path, an 8-byte timestamp, and 756 bytes' worth of tags. (I'm incapable of counting, so that's probably wrong, but whatever). On file, any unused data is set to 0, but obviously it would be a giant waste to load a full kilobyte of data if only a hundred or so bytes are actually going to be used, so in RAM, the data is written into a Block object:
class Block
{
public:
private:
bool pending;
int block_number;
unsigned long long time_stamp;
char * fl_path;
Tag fl_tags;
};
Two things in particular are not directly encoded in the file, pending and block_number; the first is just to keep track of what Blocks actually need to be written to disk, and block_number is where to write the information (The byte offset itself is derived from this by multiplying block_number by 1024, then adding 9; one of those linear-equation-thingies I wasn't paying attention to in math class) time_stamp is loaded and written as-is (though with some small code to ensure the bytes are read out in the right order). fl_path similarly is handled exactly as one might expect; a buffer is allocated, and it gets dumped into RAM, just without the extra zero's.
fl_tags on the other hand, is handled quite a bit differently.
Dr. Strangelove or: How I Learned to Stop Worrying and Love the Bomb
If you go to any blog ever ever, you will probably notice (aside from, you know, the blog) that it has a tag cloud; that little box off to one side of the screen with a whole bunch of words in it. Of course, when developing ASH, I wanted to include something similar, but I also wanted to make sure that searching through those tags was quick and efficient.
In walks the C++ Standard Template Library, and it's std::map<> template class.
At a first glance, I thought "Oh, wow! This is exactly what I need! An object that maps keys to their values!". I began integrating std::map into ASH, and wrote loading code to parse individual tags and add them in. Every tag would, from there, link to a Block. The whole time, of course, I seriously thought that it would work perfectly and drastically reduce the time needed to search for images.
Then I actually ran it.
It was slow. Like, loading 500KB took a full 10 seconds slow. Now, admittedly, this probably wasn't the std::map's fault, and I'm sure there's a couple million different boring, mathematical reasons as to why this approach crippled ASH, but math is stupid. The important thing was that it was slow, and using std::map made it exceedingly difficult to do partial matches. Thus, I came to embrace the bomb delete key and violently dismantle ASH's shiny new ugly old code.
Episode IV: A New Hope
A few seconds hours later, it was time to start rebuilding the tagging system, and maybe throw in a few new, superfluous features, like "searching" and "updating tags".
I watched Army of Darkness instead.
After watching Ash heroically triumph over the Deadites, bravely keeping them from acquiring the Necronomicon, I realized something super important. If I don't finish this, the deadites will win (It was four in the morning, and I drank too much Mountain Dew. Don't judge me). I immediately began redesigning the tagging system. At first I thought I should just completely replace std::map with some sort of dictionary... But I suck at math, and the algorithm I came up with seemingly would've taken a couple more gigabytes of RAM than I was comfortable with (I really suck at math). Which meant I had to completely remove the entire thing. Around this time, I started a new section in my (paper) notebook entitled "New World Order", and started working out the specifics of the new tag system.
The result was ASH's current Tag objects:
class Tag
{
public:
int match(const Tag& t) const;
int match(const char* t, long len=0) const;
private:
long length;
IAllocate* allocator;
};
The new tagging system is better in a couple of ways. Firstly, and possibly most importantly, the tags don't have to be broken up after loading; in fact they never have to be broken up, unless you're a horrible, nasty person and you like destroying their lives.
The tree structure is now gone, and has been replaced with an array; not exactly amazing, but it is faster. Also, Tags support partial matches, and matching against multiple tags simultaneously.
Tags are more-or-less glorified strings with automatic cleanup. length is the actual number of bytes the tags occupy, and allocator simply manages the memory for it. A little bloaty, but it works.
The most important feature Tag brings to the table is its match methods, which return the number of matches with the input tag, like this (Please excuse my MS Paint "skills"):
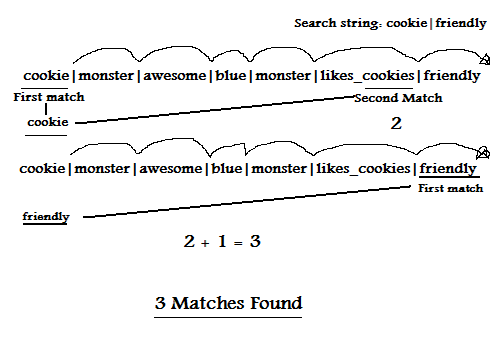
In order to save processing time and memory, the entire operation is done in-place, without recursion (this diagram isn't entirely accurate). For now the matching methods are two separate functions that do almost exactly the same thing, mainly because my goal of stopping the Deadites from winning faded slightly after sleeping for a few hours (Don't judge me!).
When appending tags, a similar, though slightly more complicated, process is used to ensure that only unique tags are appended. The rest are ignored.
The Others
At some point it became apparent that in addition to completely mangling ASH in the name of science, I would also have to write custom allocators. Why? Because I could (though also because I wanted to keep the number of re-sizes as low as possible):
class DefAllocator: public IAllocate
{
public:
void alloc(long s);
void alloc_exact(long s);
private:
long sz, rz;
byte * data;
};
The default allocator re-sizes data based on the amount of space requesteds) and the number of re-sizes (rz):
long size = ((s*(++rz)*rz) >> 1);
if(size < s) size = (s + rz) + 1;
The theory being that it's better to waste RAM than it is to waste CPU.
Lists, lists, lists, and... Cranberry Juice?!
Ash::lists were intended to be really, really bloated versions of std::vector (but in the best way possible, I assure you). Much along the same lines as Ash::DefAllocator, list allocates increasingly more memory in order to reduce the number of resizing operations. Because I was trying to make as few changes as possible following the horrible bombing refactoring incident with the tagging system, lists tend to come off as a gigantic rip-off of vectors:
template<typename item>
class list
{
public:
private:
long size, mem_count;
long resizes;
item* members;
SizeType st;
};
The only particularly unique thing about lists is that they allow you to change how they size (the SizeType), so that you can prevent infrequently sized lists from growing out-of-control.
Pipes, RNGs, and GNU/Linux
If you were to skim ASH's source code, you would probably notice several references to GNU/Linux and GCC, and then, several minutes later, begin to smash your monitor/keyboard/mouse/whatever in frustration as you discover that ASH doesn't (or rather, no longer) compiles under *nix systems. This is pure laziness. I have yet to write the code for it.
However, what this means is that the parts of ASH which can't be implemented using only the Standard Libraries have interfaces; in particular IPipeServer and IRandomProvider (IAllocate is also an interface but it doesn't count because it isn't implemented like that for cross-platform reasons [don't ask]).
IPipeServer is basically just a wrapper for the relevant system calls. IRandomProvider is slightly different, as it has three separate implementations. The first is DefRandomProvider, which is in fact wrapper for the Standard srand() and rand() functions; this is a bit useless since the Standard libraries are already cross-platform. The other two are WinRandomProvider and NixRandomProvider, which provide more cryptographically secure methods than DefRandomProvider. On Windows, this is a wrapper for CryptGenRandom(), and handles important junk like acquiring the cryptographic context and throwing flagrant exceptions. On *nix systems, a seed is read from /dev/random, and from there random numbers are generated (because taking 15 minutes for a couple KB's of data is actually quite ridiculous).
Facism
As yet another experiment, I added in AccessControls to manage logins:
class AccessControl
{
public:
void generateLogin(Token& out);
bool isLoggedIn(const Token& in) const;
bool logoutUser(const Token& in);
private:
IRandomProvider * irp;
list<Token> logins;
};
AccessControl generates 32-byte session tokens which can, most likely, be used to manage individual sessions (I admit, this is technically untested...). I'm sure this is important for something somewhere along the line.
Putting It All Together
I couldn't figure out a way to incorporate The Sound of Music into this section, sadly. Sorry.
As you have probably suspected by now, Blocks do not act of their own accord. They are managed by
a single File object:
class File
{
public:
private:
int header_sz;
std::fstream file_obj;
list<Block> file_blocks;
};
header_sz is the size of the ASH header. Remember how I said it was 9 bytes? Yeah... I was lying (slightly). The first byte in an ASH database is the total size of the header, excluding the first byte. As of the current version of ASH, the first byte is always equal to 8; though you could actually make your own file with a hex editor and change it to whatever you wanted. When writing a block to the disk the byte offset is calculated as
offset = header_sz + (block_sz * block_number)
Currently, the extra available header data is unused; this is just for future expansion.
file_obj, if you haven't guessed, is the file-thingy for the database file itself. It persists throughout the program's execution to keep the database file locked to outside processes, though otherwise does nothing for most of the program.
file_blocks is the list of Blocks loaded from the database file. For the time being, ASH searches blocks directly.
Using the code
Compiled as-is, ASH is run on the command line. First, it asks the user (you?) to specify the full path to the ASH database:

If the file doesn't exist, ASH will just create it (And yes, it has to be ".ash", otherwise the one standing behind you might get angry. No, seriously. Don't. Turn. Around.). From there, you can type in commands for ASH to execute, specifically: "add", "remove", "find", "find_path", "tag", and "path" (without quotes, of course). Arguments are separated by spaces; if any single argument needs to have spaces (i.e. a file path), put it in quotes.
- "add [file path] [tags]" adds an entry to the ASH database, with the specified file name and tags. If the specified file name already exists, it will merge the specified tags with the existing entry. Tags should be separated by spaces.
- "remove [file path]" deletes an entry from the database.
- "find [tags]" returns a list of all the entries in the database which match the specified tags, in order of most hits to least hits. Due to a rather annoying problem that I don't feel like fixing right now, tags should be separated|by|pipes.
- "find_path [file path]" finds the entry with the specified file path and returns its tags.
- "tag [file_path] [tags]" tags an existing entry with the specified tags; this differs from "add" in that "tag" will not add an entry if one does not exist. Tags should be separated by spaces.
- "path" takes no arguments and returns the path (but not file name) to the database.
A Series of Tubes Pipes
Once ASH establishes a database, it opens a named pipe ("AshPipes") to receive commands from external processes:
In this case, Experiment #735 (don't ask where the numbering comes from otherwise the scary one will come back) is a .NET process which acts as a GUI-wrapper-thingy for ASH. When a user clicks something, say "Add Image", it creates a String containing the "add" command, along with its arguments, and sends it:
private String sendString(String output)
{
StreamWriter sw = new StreamWriter(npcs);
sw.Write(output);
sw.Flush();
String response = "";
StreamReader sr = new StreamReader(npcs);
char[] buffer = new char[1024];
Int32 count = 0;
while ((count = sr.Read(buffer, 0, 1024)) > 0)
{
response += new String(buffer, 0, count);
if (count < 1024) break;
}
return response;
}
If the command fails for any reason, response is "fail".
When the command succeeds, response is different depending on the command sent; "add", "remove", and "tag" all return "success". "find" is possibly the biggest operation and returns the entire list of matches (which can easily number in the thousands). "find_path" returns all of the tags for a single block and is unlikely to be larger than 756 bytes. "path" returns the path to the database and should not be expected to be larger than 260 bytes.
ASH will only do one command at a time per connected process (plus one at a time for the ASH server process itself).
But I don't wanna!
So assuming you have some sort of aversion to the included "main.cc" (which will totally summon the scary one behind you), you'll have to set everything up yourself, starting with the database:
try{
db = new Ash::File(path);
if(db != nullptr){ db->loadDataBase(); }
else throw Ash::ae_memfail;
}catch(Ash::ash_error e){
cout << Ash::parse_error(e) << endl << endl;
try{
db = Ash::File::createDataBase(path);
if(db != nullptr) { db->loadDataBase(); }
}catch(Ash::ash_error e){cout << Ash::parse_error(e) << endl;}
}catch(...){
cout << "Unspecified error!" << endl;
cout << "Program cannot continue; please try again." << endl << endl;
return -1;
}
The first try attempts to open an existing database; Ash::File will not create one on its own, so if it fails to open the database, it throws an exception (specifically, Ash::ash_error::ae_iofail), in this case we attempt to initialize a database at path; ASH is unbelievably gullible and simply assumes all paths are valid.
Once the Ash::File object is created, we call loadDataBase() to load it into RAM.
File defines the following methods:
class File
{
public:
bool removeBlock(const std::string& path);
void addBlock(const std::string& path, const std::string& tags);
void flush();
void loadDataBase();
list<std::pair<Block*, int>> find(const std::string& search_str);
Block* findBlockNumber(int bn);
Block* findPath(const std::string& search_str);
static bool isVersionCompatible(const unsigned char* version_buffer);
static File* createDataBase(const std::string& path);
private:
};
Adding and removing Blocks is somewhat self-explanatory; just keep in mind that addBlock() doesn't check for duplicates.
Call flush() to write pending changes to disk; File objects do this automatically on destruction, but this way you can assert any preexisting psychological need to micromanage.
As mentioned somewhere above, find() returns a list of results and the number of hits per result, in descending order. findBlockNumber() returns a pointer to a single Block with the number bn. findPath() returns a pointer to a single Block with a path matching search_str (using the std::string::operator=()).
isVersionCompatible() is used internally to check compatibility with the ASH database to-be-loaded. It expects a buffer size of 9 bytes and sometimes causes really, really, really dramatic Blue Screens (not really).
Blocks
Ash::File handles absolutely everything on its own, assuming you don't modify any of the Blocks or update tags or do anything at all. In one of those crazy, impossible situations where you might actually want to modify existing data, you'll have to work with the Block in question directly:
class Block
{
public:
int getBlockLocation() const;
long long getTimeStamp() const;
char* getPath() const;
std::string getTags() const;
void setPath(const char* nPath);
void setTags(const char* nTags);
Tag& modTags();
void killBlock();
void writeBlock(std::fstream& output, int header_sz) const;
private:
};
The setters and getters behave exactly as expected; they set and get data (surprise!). killBlock() marks the Block for deletion (i.e. when the database is flushed, this particular region is written as zeros). writeBlock() is used internally by Ash::File when writing the file to, well, write the file. You are, of course, welcome to use writeBlock() for your own nefarious purposes, just remember that it writes the block at the block's offset, not your evil location of evil. modTags() returns a reference to the Block's Tag object so that you can do twisted medical experiments on it.
Tags
Tags look something like this:
class Tag
{
public:
void setTags(const char* t, long len = 0);
void trim();
void writeTags(char* out, long max) const;
long getTagCount() const;
std::string getTags() const;
char* getTagPtr() const;
int match(const Tag& t) const;
int match(const char* t, long len=0) const;
private:
};
As you can see, Tags provide all sorts of useless nifty functionality.
setTags() effectively skips over the normal stuff and completely changes all of the tags; use this when just appending tags becomes too difficult. trim() resizes the internal buffer so that there are no unused bytes, which probably helps if you're porting ASH to a Z80 or something. In practice, trimming the buffer really only serves to slow ASH down; however it may be helpful if A.) You really are running this on a Z80 with 1K of memory or B.) You have some way of guaranteeing that the tags won't be modified very often, and need the RAM for something more important such as Hello Kitty Island Adventure, Part II: The Fluffening. writeTags() copies the internal buffer to out. I'm positive that you can find a use for that one on your own. If not, just recompile it without it or something. See if I care (I really, really do! Don't make me cry!). getTagCount() returns the number of tags in the Tag object; tags are separated by pipes; you do the math. You may also notice that Tag has one of those (not-included above) square-operator-reference-thingies (operator[]()), which returns a string containing the tag at the specified index. Believe it or not, these two are in fact related. Now, you may be tempted to do something like:
string a;
for ( long i = 0; i < getTagCount(); i++ ){
a = my_tag[i];
}
Technically speaking, the above will compile. But it's wrong. So don't do it. That's bad. Seriously. Don't. If you do, the one behind you might get angry again. It's inefficient. All those nasty C programmers will use you as a poster child for why-C++-sucks-so-badly-and-why-we-should-do-everything-in-C. Really. (Try it anyway!)
getTags() returns all the internal tags as an std::string, and is for the express purpose of getting all the internal tags in a more editing-friendly form. For instance, if you have a particularly complex operation that Tags currently have no support for whatsoever (see: regular expressions), you can do something like this:
string some_tags = my_tag.getTags();
some_regex_function(some_tags, some_input);
my_tag.setTags(my_tag.c_str(), my_tag.length());
getTagPtr() directly returns a pointer to the Tag's internal buffer; so don't do anything bad to it.
The match() methods are, as their names imply, for matching tags:
Tag my_tag;
my_tag.setTags("the_ramones|awesome|punk|blitzkrieg_bop|multiple_bops");
int matches = my_tag.match("blitz");
cout << "Matches: " << matches << endl;
matches = my_tag.match("bop");
cout << "Matches: " << matches << endl;
In case you skipped it, the Background section has a more detailed explanation of how this actually works (I can't blame you, I would've skipped it too).
Tag also includes several operators which are fairly important since all of ASH would (possibly) be crippled without them:
class Tag
{
public:
Tag& operator=(const Tag& t);
Tag& operator=(Tag&& t);
Tag& operator+=(const Tag& t);
bool operator==(const Tag& t) const;
std::string operator[](long i) const;
private:
};
The assignment operators are, in fact, really, really, really generic. They do exactly what one might expect; and sadly don't even possess any odd behaviors (that I'm aware of) that might crash entire networks if not taken into account. operator+=() is slightly different in that it is somewhat picky about what it actually adds to the Tag's tags (as briefly mentioned somewhere above), since I thought a normal appending-operator would be plain silly. Basically, it only adds unique tags, rather than appending all tags:
Tag my_tag;
my_tag.setTags("the_ramones|awesome|punk|blitzkrieg_bop|multiple_bops");
Tag my_other_tag;
my_other_tag.setTags("the_ramones|punk|blitz");
my_tag += my_other_tag;
cout << my_tag.getTags() << endl;
Like everything else that is ASH, this operator thoroughly believes that speed is more important than space efficiency, and therefore uses more RAM than is actually used (Yes, that does make sense). The more unique tags added, the less space is wasted.
The comparison operator is very much literal, and only returns true if the two Tags are identical; for fuzzier comparisons, I highly recommend using the match() functions (no that isn't biased!). The square-operator-thingy (operator[]()), as mentioned above, returns the tag at the specified index:
Tag my_tag;
my_tag.setTags("the_ramones|awesome|punk|blitzkrieg_bop|multiple_bops");
cout << my_tag[3] << endl;
cout << my_tag[105] << endl;
Known Issues
1) It doesn't compile to my Linuxuuu!
Actually it technically does if you remove the multi-threaded/pipe-handling bits from main.cc, but I see your point, Angry GNU/Linux User. I'm sure I'll completely ignore the entire GNU/Linux community and never work on it ever, ever get to it eventually. (See what I did there? Now there's all sorts of suspense. "Was he just joking about that? Or will he ignore our plight?") Though I do want ASH to be cross-platform, there are a couple of what I consider to be very serious (more serious than Cookie Monster and Evil Dead II combined), earth-shattering problems (though are completely transparent to the user and are too numerous to list here) which take priority (You'll never guess what those are!). Obviously you can patch this yourself, though new versions of ASH will probably break compatibility with old ones (so you might end up having to re-patch every new release until I get around to *official* support for GNU/Linux). As it stands, if you compile ASH for GNU/Linux, it can do everything the Windows version can do except for connecting to external processes (so you won't be able to create a GUI for it without modifying the code first).
2) Experiment #735 is bricked!
I attribute this mostly to my inexperience with .NET; there are two particular instances where Experiment #735 will completely stop responding. First is when adding a very large folder to the ASH DB; this is not a bug, I was just too lazy to add in a progress bar; in these cases, you'll just have to wait it out. The reason it's so terribly slow is that Experiment #735 adds the images one at a time, and each time has to create a new String, send it, wait for a response, then move on to the next one. Inefficient, I know, but Experiment #735 was intended to be more of a testing-type-thing rather than a practical-type-thing. The second instance is an actual problem. When Experiment #735 does a search, and ASH returns more than around 600 results, the pipe apparently gets clogged, and Experiment #735 stays frozen until ASH is closed. So far this behavior is consistent on both Windows 7 and Vista, on two separate computers, so I'm guessing I seriously messed something up here. Rather than responsibly dealing with the problem, I'm probably just going to use intermediate files or something.
3) Experiment #735 suddenly dramatically crashed!
Now, I can't be completely certain, but I'm pretty sure this one isn't my fault. During testing it turned out that certain GIFs (which are otherwise harmless and fully functional) apparently cause GDI+ to throw some horrible exception and crash the application. Since I didn't actually write Microsoft's GIF-parsing code or their PictureBox controls, I think I can safely blame them. Technically, MS may have already fixed this, though I don't know because I completely forgot what .NET version this happened with (I am that good.)
And that's it as far as I'm aware; if you find any others, please complain loudly.
Conclusion
This was the section I always got marked down for in English class, so I won't even try.
Have fun! (Or don't. Killjoy.)


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 







