Zipped Words_Dictionary files
Part I: How I Scraped Merriam-Webster's Dictionary
Part III: Creative Writer's Word Processor
Introduction
In my last article, I talked about one way you can use to scrape files off a public website. Since those files require supporting references located on the server to look the way they do, simply loading the HTML files off your own harddrive using your favourite web-browser makes them look like they would have looked like in 1991 when your hip parents were still grooving to the Cranberries. You might have a cool song in your head right now but the webbrowser in your mind should look like little more than text from a bygone BBS.
So, all 255,000 HTML files are going to have to be parsed-out and spruced-up using a lot of cutting and splicing of hyper-text to format them with colors, tabs, fonts and a general sense of well-being only tofu, nuts and Hawaian-blend trail-mix can provide.
Using the Code
I tried to compress the 974 HTML documents of words that start with non-alpha characters and the file was 14MB (too big to upload here) and there are ¼million of the so ... you ain't getting a copy. You can still download what files you want to run this app on and set the source directory input value on the app's main screen to see the result.
So here's what a typical definition on-line would look like. They have a lot of over-head to help you navigate along with advertisement to pay for it all.
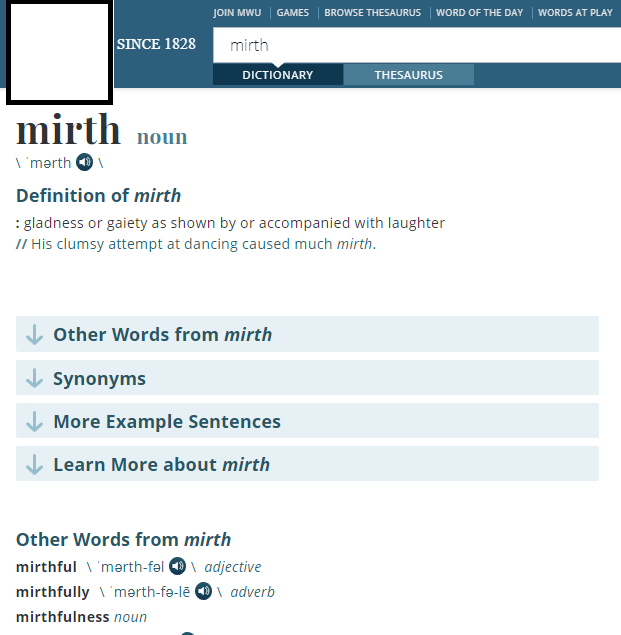
This is what the HTML looks like when you load it off-line. It just looks like crap, all that over-head is distracting and ugly.

After it has all been parsed and cleaned up, the RTF file looks like this:
There's no advertisement or overhead in the RTF files. Just the definition and information relevant to the word you're looking at. If you look through the code, you'll notice that the source filenames reflect the words the HTML files define while the RTF file names are computer generated filenames of uniform size. The reason for the change in file names (beyond their extensions) is so that I can more easily include the filenames in a binary random-access file when I make a search engine for it all later.
Unicode
The HTML files all contain something called Unicode which allows any computer on the globe to read them before they are then converted to the appropriate fonts and displayed on your screen. To convert them from HTML Unicode to readable text, I resorted to the old fashioned grunt method of one-on-one comparison. Making a list of Unicode character combinations found in the source files, and matching them with the appropriate output characters, they're all replaced before any parsing takes place. There were a few issues there, and I'll probably find more problems, but the one that stands out to my mind right now is the lack superscript characters in MS. The only numerals available in superscript are {0, 1, 2 & 3} so when loading a definition like the one for the word Angstrom requires superscript characters, they are not available. Short of painting an image on the background or pasting a smaller fonted label on top of the RichTextBox, there's no simple way to display 1010 in a RichTextBox. So, when that happens, the text is rewritten "10^10" which is less elegant but can still be understood by most mathematically literate users.
The Unicode conversion is straight forward and you can have a look at it in the classStringLibrary:
public static string Unicode_ConvertToString(string strHTML)
GetNext
The GetNext function is by-far the work-horse of this project. You give it the open/close HTML parameters you're looking for and it provides you with all that is contained within those markers from the source material you provide it. You can find it in the classStringLibrary.
public static string HTML_GetNext(string strHTML, string str_Start, string str_End)
The HTML file had to be broken up into small segments. Each segment of text had to be tagged with an enumerated type label as well as its index location in the source file. The code uses a for-loop to cycle through all the different types of texts that are found in the file and then locates, isolates and compiles them in a list. When it's done going through all the different formats it's looking for, it reorders the compiled list in the order of each text's index location in the source file, then pastes them into a RichTextBox. When that's done, it goes over the entire list again setting the font size and color before saving it all to the harddrive.
Here's a sample of some of these types of formats. You can find these in the classFontDefinition class where each have their formatting information defined.
public enum enuDefinitionContentType
{
ExamplesInSentence,
SynonymDiscussion,
Note,
altSpellings,
altWords,
Antonyms,
AntonymSynonymSubHeading,
Definition,
DefinitionQualifier_1,
DefinitionQualifier_2,
DefinitionQualifier_3,
DefinitionQualifier_4,
dialectal,
Etymology,
ExampleAuthorName,
Here's an example of how one of these formats is defined:
{
classRTX.classRTX_FontInfo cFntAntonyms = new classRTX.classRTX_FontInfo();
cFntAntonyms.clrFore = Color.DarkGray;
cFntAntonyms.fnt = new Font(strFontFamily, intFontSize, FontStyle.Regular);
cFntAntonyms.intIndent = intTabs[0];
cRtxFont[(int)enuDefinitionContentType.Antonyms] = cFntAntonyms;
}
Parsing the HTML text itself required a lot of searching for markers and then cutting out what was needed before removing the MarkUpLanguage and making it look like proper English text. Typically, it would search for a marker, use HTML_GetNext() with the index of the marker it just found to get the text. The reason why it couldn't just say "find the next HTML code that starts with <span class="dtText"> </span>" was because the GetNext() function will search for the opening marker (<span class="dtText">) and disregard all others but still shut down when it finds the first closing marker (</span>). Since there are likely going to be other <span ...> opening markers before you reach your intended closing marker, it will stop after the first closing marker regardless of how many proper opening <span ...> it finds along the way. To avoid this, the opening and closing markers are the broader more generic ones <span & </span>. Since GetNext() is also provided with the previously located starting index, it will start at the intended starting marker and stop when it has reached its rightful end.
Here's a typical example:
case enuDefinitionContentType.ExamplesInSentence:
{
int intExamplesInSentence_Find =
strHTML.IndexOf(strContentTags[(int)eDefConType], StringComparison.Ordinal);
while (intExamplesInSentence_Find > 0)
{
string strExamplesInSentence =
GetNext(strHTML, "<div ", "</div>", intExamplesInSentence_Find);
strHTML = strHTML.Replace(strExamplesInSentence, "".PadRight
(strExamplesInSentence.Length, '.'));
if (strExamplesInSentence.Length > 0)
lstDefCont.AddRange(ParseHTML_MerriamWebster_ExamplesInSentence
(intExamplesInSentence_Find, strExamplesInSentence));
intExamplesInSentence_Find = strHTML.IndexOf(strContentTags[(int)eDefConType],
intExamplesInSentence_Find + 1, StringComparison.Ordinal);
}
bolLoop = false;
}
break;
There were some that were more complicated than others but it's all pretty basic. In the example above, the text is replaced by '.' characters because some Examples in Sentences conflicted with others, by removing them here that eliminated the problem of the text being reported more than once.
I included the code to my HTML-ator project because it was a great help to me to figure out how to parse and cut-up the HTML files to make them into decent looking .rtf files. There's a bit more information about that app in my previous article, How I Scraped Merriam-Webster's Dictionary.
The entire project was a hack and could certainly be improved but I'm pleased with the result and my new Merriam-Webster dictionary that I've incorporated into a word-processor which I'll write about in my next article.
History
- 20th September, 2019: Initial version
Christ Kennedy grew up in the suburbs of Montreal and is a bilingual Quebecois with a bachelor’s degree in computer engineering from McGill University. He is unemployable and currently living in Moncton, N.B. writing his next novel.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




