Introduction
When you work with a large amount of various data in your program, it is advisable to cache this data to speed it preparing and availability. I offer my implementation of caching algorithms, superior speed competitors.
Background
For decades, many caching algorithms have been developed: LRU, MRU, ARC, and others…
Most implementations of these algorithms are thread unsafe. If you simply protect the cache container with a mutex, this will significantly reduce performance. I was able to implement thread-safe caching algorithms while maintaining high speed. As proof, the caching pattern repository is organized as a test bench where you can compare speed with competing algorithms in multi-threaded and single-threaded tests.
Using the Code
Sources of the test bench and templates of the O(n)CacheXX_RU series caching algorithms can be taken in the repository: https://github.com/DimaBond174/cache_multi_thread
The templates are here and each is implemented as a single oncacheXXX.h file. In the test bench, for the testing of each algorithm, proxy classes are created where you can see how to connect the templates to your code. For example, the implementation of a container with a string key in proxy TestOnCacheMMRU2:
OnCacheMMRU<ElemNSizeKey *, ElemNSizeKey *> *cache = nullptr;
Warning: In this case, I deliberately send an adapter instead of a string as a key. This is done specifically for maximum speed, see how it is implemented:
struct ElemNSizeKey {
ElemNSizeKey() {}
ElemNSizeKey(const std::string &_data)
: data(_data) {
setKey();
}
void setKey() {
len = data.length();
if (data.capacity() < key_ElemNSizeKey_size) {
data.reserve(key_ElemNSizeKey_size);
}
key.setKey(data.data());
}
static constexpr int key_ElemNSizeKey_size = 3 * sizeof(uint64_t);
NSizeKey<key_ElemNSizeKey_size> key;
std::string data;
int len;
};
In this code, the string size is provided by the capacity to cover key uint64_t keyArray[3], and then the pointer to the given string.data() is simply cast to the key pointer to array *uint64_t[3]. This is done for high-speed hash calculation. For the template to work, 2 methods must be implemented:
- Hash function:
inline uint64_t get_hash(YourKey). For example, calculating a hash on a string, I cast the pointer std :: string.c_str() to an array[3] of 64-bit unsigned integers and put them together - these calculations are enough to decompose the elements into baskets of the hash-table:
inline uint64_t get_hash(const ElemNSizeKey *lhv) {
uint64_t re = 0;
if (lhv->key.keyArray) {
for (int i = 0; i < lhv->key.keyLongSize; ++i) {
re += lhv->key.keyArray[i];
}
}
return (re < 9223372036854775807ll)? re : (re >> 1);
}
- Comparison function:
inline int compare (YourKey lhv,YourKey rhv). For example, for std::string first compare casted to uint64_t[3] first letters and if they are equal, next call to std::string.compare(). So we are comparing by 8 bytes on each step versus 1 byte by 1 byte:
inline int compare (const ElemNSizeKey *lhv,
const ElemNSizeKey *rhv) {
if (lhv->key.keyArray) {
for (int i = lhv->key.keyLongSize_1; i >= 0; --i) {
if (lhv->key.keyArray[i] > rhv->key.keyArray[i]) return 1;
if (lhv->key.keyArray[i] < rhv->key.keyArray[i]) return -1;
}
} else if (rhv->key.keyArray) {
return -1;
}
return lhv->data.compare(rhv->data);
}
The hash function, instead of counting each letter of a string, simply casts a pointer of the given string to uint64_t keyArray[3] and counts the sum of integers. That is, it works like the TV show "Guess the melody" - and I guess the melody by 3 notes .. 3 * 8 = 24 letters of the Latin alphabet and it already allows you to scatter the strings well enough on the hash baskets. This trick allows us to surpass the competitor speed 3-5 times:
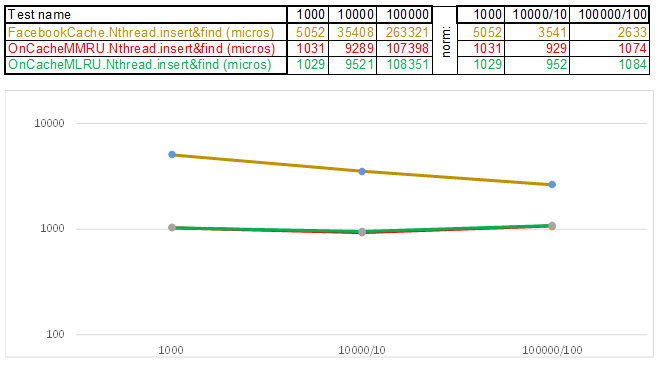
Graphs are constructed as follows:
- The following volume is planned for measurements: 1000 items, 10000 items, 100000 items ... N items
- For the next algorithm, a cache of N * capacity percent is created. So if you specify capacity percent == 10, then the cache volume V = N * 10/100 == 100 items, 1000 items, ...
- The cache is heated by inserting V items without measuring time.
- Turns on the barrier for threads to start simultaneously.
- Insert threads and search threads are prepared according to the counts you specified.
- Measuring the start time
- The barrier is lowered so that the threads can start working.
- The main thread is waiting for the completion of the generated threads through
thread.join(). - Measuring the end time
- The resulting difference (
end_time - start_time) is divided by how much the current test volume exceeds the volume of the first test (which always 1000 items):
- for 10,000 items time =
(end_time - start_time) / 10 - for 100,000 items time =
(end_time - start_time) / 100 - for 1,000,000 items time =
(end_time - start_time) / 1000
So we normalize time by bringing it to a volume of 1000 items. If the graphs remain parallel to the X axis, then the algorithm under test behaves as O(n).
Yes, the hash function is not perfect and many items can accumulate with each hash basket. But this is not a problem as each hash basket inside is organized as Skip-List:

Nodes in which keys are stored and data are taken from a previously allocated array of nodes, the number of nodes coincides with the cache capacity. Atomic identifier indicates which node to take the next one - if it reaches the end of the node pool, it starts with 0 = so the allocator walks in a circle overwriting the old nodes in the FIFO cache OnCacheMLRU.
For the case when it is necessary that the most popular items in search queries are saved in the cache, a second class OnCacheMMRU has been created. The algorithm is as follows: in the class constructor except the cache capacity is passed also the second parameter uint32_t uselessness popularity limit - if the number of search queries that wanted the current node from the cyclic pool is less than the uselessness border, then the node is reused for the next insert operation (will evicted). If on this circle, the node's popularity (std :: atomic <uint32_t> used {0}) is high, then at the time of the request from the cyclic pool allocator, the node can survive, but the popularity counter will be reset to 0. So the node will exist one more circle of the allocator's passage through the pool of nodes and will get a chance to gain popularity again in order to continue to exist. That is, it is a mixture of MRU algorithms (where the most popular ones hang in the cache forever) and MQ (where the lifetime is tracked). The cache is constantly updated and at the same time, it works very fast - instead of 10 servers, it will be possible to install 1.
Step-by-step instructions on how to compile, configure and run this test bench: https://github.com/DimaBond174/cache_multi_thread/wiki.
If there is no step-by-step instruction for the operating system convenient for you, then I would be grateful for the contribution to the repository for the implementation of the ISystem and step-by-step compilation instructions (for WiKi) .. Or just email me - I will try to find time to raise the virtual machine and describe the build steps.
Points of Interest
- I have created a small simple fast JSON parsing library consisting of one file specjson.h for those who do not want to drag a few megabytes of someone else's code into their project in order to parse the settings file or incoming JSON of a known format.
- Approach with injecting implementation of platform-specific operations in the form (
class LinuxSystem : public ISystem { .. } ) instead of the traditional ( #ifdef _WIN32 ). So it is more convenient to wrap up, for example, Semaphores, work with dynamically linked libraries, services — in classes, only the code and headers from a specific operating system. If you need another operating system, you inject another implementation (class WindowsSystem : public ISystem { .. }). - The test bench is building with
CMake - the CMakeLists.txt project is convenient to open in Qt Creator or Microsoft Visual Studio 2017. Working with a project through CmakeLists.txt allows you to automate some preparatory operations — for example, copy test case files and setup files to the installation directory:
//
# Coping assets (TODO any change&rerun CMake to copy):
FILE(MAKE_DIRECTORY ${CMAKE_RUNTIME_OUTPUT_DIRECTORY}/assets)
FILE(GLOB_RECURSE SpecAssets
${CMAKE_CURRENT_SOURCE_DIR}/assets/*.*
${CMAKE_CURRENT_SOURCE_DIR}/assets/*
)
FOREACH(file ${SpecAssets})
FILE(RELATIVE_PATH
ITEM_PATH_REL
${CMAKE_CURRENT_SOURCE_DIR}/assets
${file}
)
GET_FILENAME_COMPONENT(dirname ${ITEM_PATH_REL} DIRECTORY)
FILE(MAKE_DIRECTORY ${CMAKE_RUNTIME_OUTPUT_DIRECTORY}/assets/${dirname})
FILE(COPY ${file} DESTINATION
${CMAKE_RUNTIME_OUTPUT_DIRECTORY}/assets/${dirname})
ENDFOREACH()
//
- For those who are mastering the new features of C++17, this is an example of working with
std::shared_mutex, std::allocator <std::shared_mutex>, static thread_local in templates (are there nuances - where to allocate?), running a large number of tests in streams with different ways with measuring the execution time:
for (i = cnt_insert_threads; i; --i) {
std::promise<InsertResults> prom;
fut_insert_results.emplace_back(prom.get_future());
threads.emplace_back(std::thread (&TestCase2::insert_in_thread,
this, curSize, std::move(prom), p_tester));
}
for (i = cnt_find_threads; i; --i) {
std::packaged_task<FindResults(TestCase2 *i, int, IAlgorithmTester *)> ta(
[](TestCase2 *i, int count, IAlgorithmTester *p_tester){
return i->find_in_thread(count, p_tester);
});
fut_find_results.emplace_back(ta.get_future());
threads.emplace_back(
std::thread (std::move(ta), this, curSize, p_tester));
}
auto start = std::chrono::high_resolution_clock::now();
l_cur_system.get()->signal_semaphore(cnt_find_threads + cnt_insert_threads);
std::for_each(threads.begin(), threads.end(), std::mem_fn(&std::thread::join));
auto end = std::chrono::high_resolution_clock::now();
History
For easy benchmarking, I created a test app for Android.
Test bench sources for Android, as well as templates for the implementation of algorithms in C++ and Java here: https://github.com/DimaBond174/android_cache
Video of the test bench working with String keys:
https://youtu.be/HfmQx5MV0e0
In some cases, you can see an 8-fold superiority in speed over Google Guava when multithreaded work with the cache:
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 







