|
I feel like I'm back in 1992 at the moment, reading code written by a scientist and yelling at the screen as I try and understand the difference between their "process", "process1" and "process1_1" and the intent of the parameters a, b and c. Flashbacks to FORTRAN days where every variable was a, aa, aaa, aab and so on. For the next 10,000 lines.
Python is such a simple language except for the big ugly warts where it isn't. A language's syntax isn't generally the challenge, it's the libraries and it's know which way to hold the handle so you don't cut yourself. To this end we're working on providing some solid, simple Python reference material that will cut to the chase and make it a little easier to learn Python. More on that soon.
For better or worse Python is the language of choice for data scientists, for those teaching code, and for many doing AI and numerical work. I need to learn Python better, and I would say every software developer should have a working knowledge of Python. You will bump up against it one day. Maybe to actually write code, maybe simply to understand what's happening within a Jupyter notebook.
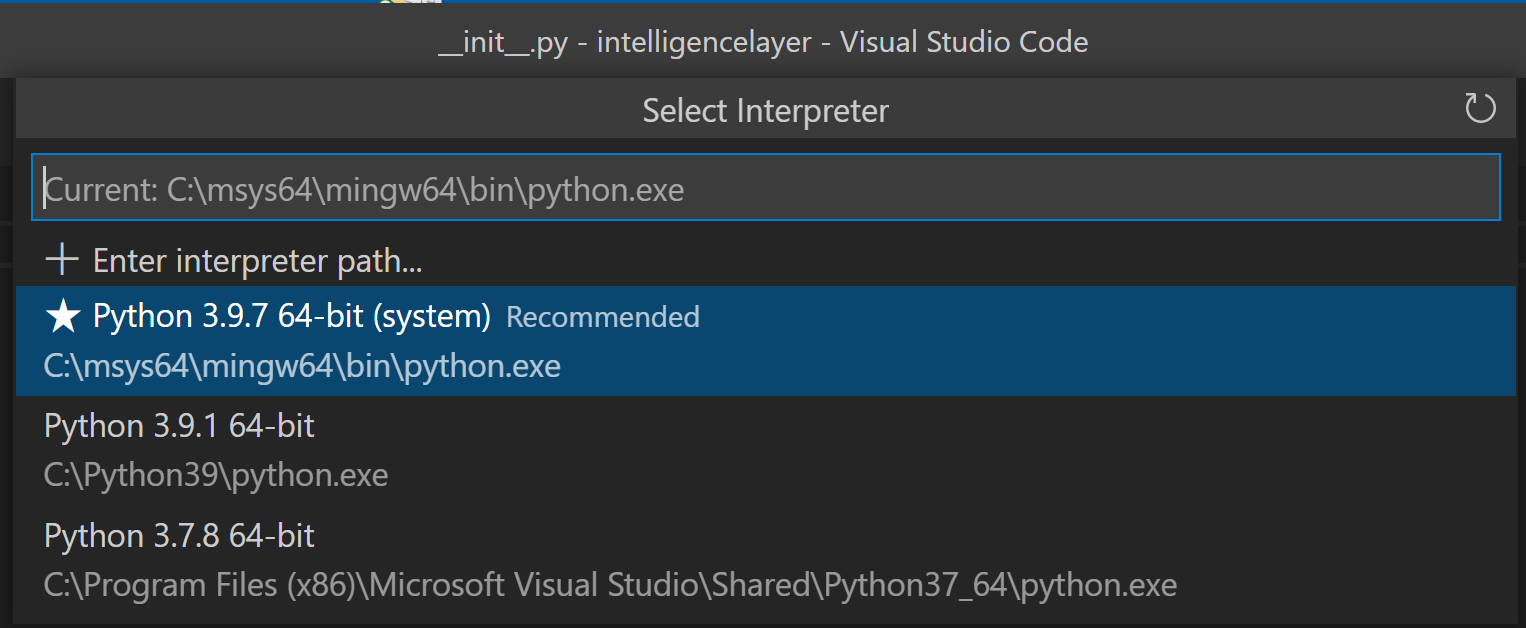
One of the benefits of Python is that it's self contained. You can deploy an app that contains the Python interpreter, the libraries, your code, everything, and you won't have conflicts with other versions of Python. I say "other versions" because there's a solid chance you have one or more versions of Python on your machine already. Here's me:

This is especially important because the change from Python 2 to Python 3 included some breaking changes and 3X is not backwards compatible.
But to the point of this whole post: Python is important for a zillion reasons and so we will be ramping up our focus on Python at CodeProject. We're after your articles, your knowledge, and obviously your Python code samples and shareable modules. From the gnarliest data diving to the simplest explanation for new developers - it's all needed. We'll be doing our part with our own content shortly.
cheers
Chris Maunder
|
|
|
|
|
Have you ever looked at a new technology and thought "that looks like a lot of work" and just kinds of...left it.
When I first started CodeProject I knew nothing about database development. I wrote, exclusively, UI components. Self contained, easy to install, easy to learn, UI components. Databases were server-based systems. Sure, they often sat on the same machine as your app, but they were...separate. Distant. Not to be trusted and probably a nightmare to manage and setup and maintain. I was totally intimidated but I had a website with thousands of articles and I really, really had to work out this whole database thing.
And so I did, in about a day, and then spent the rest of the weekend alternatively marveling at how simple it all was and kicking myself for not taking the time sooner.
This pattern has repeated itself with MVC, or Vue.js, or Bootstrap, or regular expressions. Core development technologies that I now take for granted and are really, really simple (when you get them).
And this is how I currently think about AI. It's intimidating to me. There's a lot of stuff to wrap your head around. Models and data preparation and training and all that maths. Way too hard, way too messy, and I'm sure I can work around it with some really clever switch statements.
Except, obviously, there's a lot of deja vu going on here so I started scratching a little. I figured with a degree majoring in Mathematics I could probably at least pronounce some of the complicated words that are used. Maybe even recognise a symbol or two. And so I started reading and what I found, and am finding, is that AI and Machine Learning and all the bits that go into it do not require you to have a degree in advanced mathematics. They don't require you to be a rocket scientist. They do require you to understand what it is, exactly, you're trying to do and to be aware of the limitations (and sometimes the work required) but there's nothing fundamentally hard about simply using it.
As I looked around, and read, and forked GitHub repos and installed a billion packages that is making my computer hate me, and I realised the huge issue with AI right now is it's messy. Really messy. Sure, there are lots of cloud-based solutions and toolkits and SDKs that free you up from a lot of heavy lifting but I long for the time of UI component style reuse of code. I want to download something to my computer, add maybe 5 lines of code, and have AI working. No pain, no config, no fighting with compilers or libraries or PATH environment variables or any of that.
I want the Easy.
cheers
Chris Maunder
|
|
|
|
|
At CodeProject we typically work hard to keep older devices working. It's not so long ago that I removed some hacks that were there to ensure CodeProject worked well on the Blackberry browser, and only yesterday I made some fixes to ensure the site runs on the original iPad 1. Dedication to antiquity!
Obviously there's a point where working around old issues will take time, resources and sanity away from moving forward and so, given Microsoft's own announcement[^] that IE is a "compatibility solution", we're dropping active support for IE.
While we will still work to ensure the most egregious issues don't cause IE to completely fail to render CodeProject, smaller issues such as certain functionality missing, or small glitches with layouts will most likely remain addressed.
We all, collectively, need to move on and ensure we use tools that make the internet safer.
cheers
Chris Maunder
|
|
|
|
|
We're trying something new at CodeProject.
We noticed something interesting while digging through some data: the higher the reputation of a person, the less likely they are to ask a question. A high rep member is often someone who is technically competent, finds solutions where others can't, and is able to nut things out themselves in the face of substandard docs.
They still, however, have questions. We all do, and in doing a little soul-searching we realised that sometimes there's a hesitation in asking a question because you're scared to tarnish that reputation. We are all newbies at various stages, and the more we put ourselves in the position of being a newbie the more we learn.
If our biggest fear in asking a question is having people think we're dumb because we asked a dumb question, and if the purpose of Quick Answers is to provide a system to get questions answered, then why do we even need to show the name of the person posting the question? It doesn't add any value to the question itself. In fact it provides bias to the question, positive or negative, and that bias is unwarranted.
So we're not showing your name when you ask a question in Quick Answers. Ask away. The only time your question will have a problem is if it's not actually a question, if you've asked in a way that is unintelligible, or if you've dumped a homework assignment. Take the time to form an actual question and someone, somewhere will be able to answer it.
cheers
Chris Maunder
|
|
|
|
|
As a, supposedly, high-rep user, I don't care whether or not people think a question I'm asking is dumb. I suspect that most of the competent high-rep users feel the same. To be honest, it looks like you've taken isolated data and extrapolated an assumption out of it. Why not just ask us if we're put off because we think a question could be perceived as dumb or whether it's more likely that we have honed our searching skills?
This space for rent
|
|
|
|
|
From knowing you a bit I already assume that you, and many others, wouldn't care. You also have high searching and investigative skills. There's no doubt about that. My thoughts come from private conversations with developers and yes, there's definitely a low data set.
I'm not sure how many people are going to put up their hand and say "yep - I don't want my name shown front-and-centre because I think I'll look dumb".
There was another motivation to this which was to see the effect of removing the person from the question and letting the question be treated on its own merits. I have worried for a long time that a name or a reputation level immediately biases those answering (or flagging) questions.
I'm ready to be wrong about this but thought it was worth an experiment. If it's out-and-out a bad idea then I'll flip the switch back on.
cheers
Chris Maunder
|
|
|
|
|
Chris Maunder wrote: There was another motivation to this which was to see the effect of removing the person from the question and letting the question be treated on its own merits. I have worried for a long time that a name or a reputation level immediately biases those answering (or flagging) questions.
I actually assumed that was the real reason, and while I find it commendable and have absolutely nothing against it, I believe you need to find a way to take care of the drawbacks first. The handling of spam and abuse being the major ones as far as I'm concerned.
|
|
|
|
|
Jörgen Andersson wrote: I believe you need to find a way to take care of the drawbacks first.
Absolutely.
What I've done is that once you report a message you will see a shield icon. Hover over that icon and you will see a popup that provides a link to the member's account.
It's an extension of the experiment: flag messages on the merit of the message.
Then again if this is a total waste of time I will turn it off. It's better to try and fail...
cheers
Chris Maunder
|
|
|
|
|
Chris Maunder wrote: Hover over that icon
I'm often enough sitting with an ipad, especially when I'm not working and actually have time to help out with spam...
|
|
|
|
|
Hi,
Off Topic:
Do the menus work for you on iPad? I have to go to the 'All Boards' page and navigate that huge list to get to the desired forum on Safari. I use to be able to hold down on the menu and it would open... but it stopped working a few weeks back.
Best Wishes,
-David Delaune
|
|
|
|
|
The left side menus work.
But the horizontal menus below the orange bar only works with the defalt selection, since hover doesn't work.
|
|
|
|
|
Jörgen Andersson wrote: But the horizontal menus below the orange bar only works with the defalt selection, since hover doesn't work.
How is it now?
cheers
Chris Maunder
|
|
|
|
|
Works fine now.
Sorry for not responding until now, but I experienced another bug (which I will report separately), so I had to wait until I had the computer and the iPad side by side so I could find the message, test and respond to it.
|
|
|
|
|
They did and now don't. I'll get them back for touch screens today or tomorrow
cheers
Chris Maunder
|
|
|
|
|
Another good point.
How about: once a question is reported the person question asker appears for moderators.
Or I could simply make the question poster appear to moderators regardless.
cheers
Chris Maunder
|
|
|
|
|
Simple enough solution.
I don't care which one you choose.
But personally I'd do the simplest one, as you have already chosen to trust moderators/protectors.
|
|
|
|
|
It's moot since I can't even reach the right side bar (Discussions, Questions, spam and approvals) on an iPad.
|
|
|
|
|
Pete O'Hanlon wrote: Why not just ask us if we're put off
If someone is shy about posting a question I think they'd also be shy about answering that question. 
Everyone is born right handed. Only the strongest overcome it.
Fight for left-handed rights and hand equality.
|
|
|
|
|
|
Hi,
Just my 2 cents:
If you could read the internal employee message boards/mailing lists at one of the largest software companies... you'd see the same thing... the senior engineers hardly ever ask any questions. I think it's simply because they are the most experience problem solvers. Almost any problem can be solved with a debugger and 1 experenced engineer.
It's an interesting idea but I highly doubt you'll see any change in the numbers.
Are you working with some other dataset I don't know about? Are you seeing high rep members creating sockpuppets to ask questions?
Best Wishes,
-David Delaune
|
|
|
|
|
Hmmm, you have a point, but I suspect that it does more harm than good. Ya gotta try though.
Primarily I agree. I ask very few questions and when I do have something I might ask about, I try to do as much as I can to diagnose the issue and give a full accurate description -- often with the result that I solve it myself. And maybe write a Tip.
But when there is something that still eludes me, I have no issue with asking -- I so want those other two platinums!
Maybe give members above a certain reputation the option to obfuscate their name?
Maybe similar to the option I have of posting as myself or as my Group?
Sinerely,
Member 2587207
|
|
|
|
|
I think you are spot on with this.
-- rants are the vehicle of the lazy and uninspired - JSOP 2/2018
|
|
|
|
|
That is really a very personal Statement: In case a member thinks he is to good/high rep to ask a question un-anonymously (how this would really called this un-anonymously?), he does not deserve an answer!
As a voice of low rep members I still would like, that questions can't be downvoted.
Only my two Cents to the discussion.
Bruno
It does not solve my Problem, but it answers my question
modified 19-Jan-21 21:04pm.
|
|
|
|
|
It's not about being too good to ask a question. It's about worrying what people would think if they asked a dumb question.
It's a small percentage of users for sure but it got us thinking "why do we need to identify the person asking the question at all?" Hence the experiment.
cheers
Chris Maunder
|
|
|
|
|
"if they asked a dumb question", I think that is exactly the same like "to be too good, to fail". But nevertheless a good Experiment, looking Forward for the results (if the results would ever be published).
It does not solve my Problem, but it answers my question
modified 19-Jan-21 21:04pm.
|
|
|
|
|


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin