|
Received similar while opening www.codeproject.com:
It does not solve my Problem, but it answers my question
modified 19-Jan-21 21:04pm.
|
|
|
|
|
we had a configuration mistake (mine) that has been corrected.
Please let me know if you are still getting these errors.
"Time flies like an arrow. Fruit flies like a banana."
|
|
|
|
|
Will do; looks cured though 
Bastard Programmer from Hell  If you can't read my code, try converting it here[^]
If you can't read my code, try converting it here[^]
"If you just follow the bacon Eddy, wherever it leads you, then you won't have to think about politics." -- Some Bell.
|
|
|
|
|
Still there.
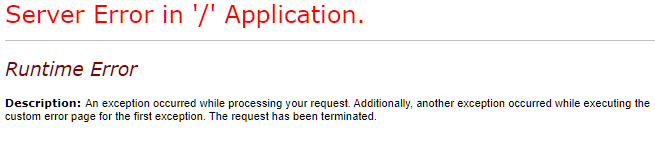
Server Error in '/' Application.
Runtime Error
Description: An exception occurred while processing your request. Additionally, another exception occurred while executing the custom error page for the first exception. The request has been terminated.
Bastard Programmer from Hell
If you can't read my code, try converting it here[^]
"If you just follow the bacon Eddy, wherever it leads you, then you won't have to think about politics." -- Some Bell.
|
|
|
|
|
It was a problem with only one of our servers, so you had a 1/6 chance of seeing this.
All good now.
"Monday is a terrible way to spend 1/7th of your life"
"Time flies like an arrow. Fruit flies like a banana."
|
|
|
|
|
1/5th of me thinks you're right. The rest is asleep 
Bastard Programmer from Hell
If you can't read my code, try converting it here[^]
"If you just follow the bacon Eddy, wherever it leads you, then you won't have to think about politics." -- Some Bell.
|
|
|
|
|
We seem to be accumulating a lot of "message closed" messages again - some going back several months.
It would be nice if the robo-hamsters could automatically remove any closed message with no replies after a couple of weeks.
"These people looked deep within my soul and assigned me a number based on the order in which I joined."
- Homer
|
|
|
|
|
Richard Deeming wrote: It would be nice if the robo-hamsters Community Engineers could automatically remove any closed message
FTFY 
|
|
|
|
|
You don't think they'd trust us with that much power, do you?
"These people looked deep within my soul and assigned me a number based on the order in which I joined."
- Homer
|
|
|
|
|
Some of us already have it. 
|
|
|
|
|
Which forum has this. Under some conditions the cache doesn't get cleared out properly.
We have an button for admins that will quickly fix this.
"Time flies like an arrow. Fruit flies like a banana."
|
|
|
|
|
Just looking at the first pages (50 messages per page), and most of them have at least one; some are almost entirely "message closed" messages:
That's why I thought it might be easier to have a robohamster / scheduled task to clean them up automatically, rather than relying on manual intervention.
"These people looked deep within my soul and assigned me a number based on the order in which I joined."
- Homer
|
|
|
|
|
Thanks for the heads up. I have cleaned up theses forums. If you find more, let us know.
Obviously we have an issue as these messages should have automatically been removed from the cache.
We’ll look into the issue, and possibly do process to scan for and clean up these messages.
"Time flies like an arrow. Fruit flies like a banana."
|
|
|
|
|
If I open the Rep History page by clicking on the Points display in the top right, all I get - and this has been like it for a couple of years, IIRC - is a blank page:
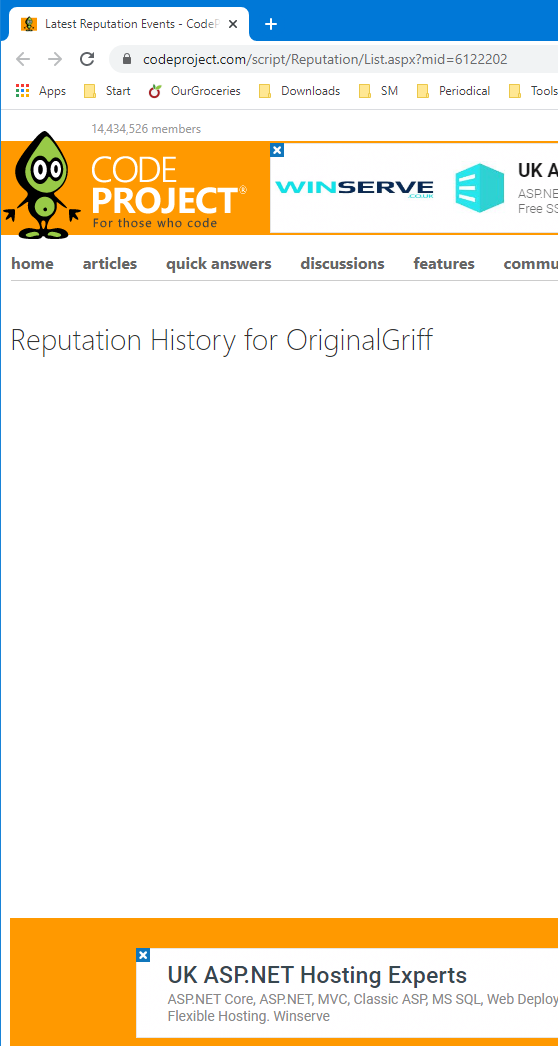
But ... if I open the "Admin messages" it looks like a DB timeout problem:
[removed]
If you're ever looking to fix that, this may help.
"I have no idea what I did, but I'm taking full credit for it." - ThisOldTony
AntiTwitter: @DalekDave is now a follower!
modified 3-Feb-20 8:59am.
|
|
|
|
|
The question has been up earlier and Chris et.al. are quite aware of the reason.
I'm willing to bet it would be easy to fix with a composite index on (UserID,DateAdded DESC) or something similar. But that might kill insert performance instead I guess.
|
|
|
|
|
Jörgen Andersson wrote: easy to fix with
Another easy fix would
DELETE TOP 90 PERCENT ...
...
WHERE userid = 'originalgriff'

Social Media - A platform that makes it easier for the crazies to find each other.
Everyone is born right handed. Only the strongest overcome it.
Fight for left-handed rights and hand equality.
|
|
|
|
|
I'd probably also add a default timelimit in the queries, for example last 10 days or so.
It could also help to include only a portion of the data (again the last 10 days) in the index thus preventing too many levels in the B-tree
|
|
|
|
|
How much data do you need to add before the number of levels in the b-tree becomes a problem?
I think we would run out of disk space before that happens.
Filtering the index is a good idea though, for space reasons.
|
|
|
|
|
Probably depends how the index is used. For example when fetching individual rows within a nested loop join, the number of levels is multiplied by the number of rows included in the join (plus leaf). Then again with a horizontal index scan the number of level becomes irrelevant.
|
|
|
|
|
Yes, and when you add more rows the number of levels grows logarithmically with the number of rows, and therefore also the seek time.
You very quickly reach three levels in an index, while more than six almost doesn't exist.
|
|
|
|
|
We have indexes. Lots of indexes. The "lots of" has been an issue we've been attacking and have removed a number that are simply slowing down the writes.
We've made some changes that have resulted in better execution plans but we're still not there. We're now starting to remove some logging calls that, while useful, aren't critical, in the hope that this reduces load enough that we can see the root cause of this particular issue.
The funny thing is that load is actually quite low on our DB. It's just a few sprocs that, in certain circumstances, take a lot of time. Run them in isolation and they are instant. Run them in the debugger and they are instant. Run them on your crappy laptop and they are instant. Run them live during a quiet part of the day when nothing strange is happening and they misbehave. So we look at stats, and recompilation, and plans, and load, and locks and everything is fine. Except it's not always.
If software development is magic then database tuning is voodoo.
cheers
Chris Maunder
|
|
|
|
|
I have a feeling you're not using SQL Server any more, otherwise I'd recommend sp_BlitzIndex®[^] by Brent Ozar. It will list overlapping indexes amongst other things. I also have a nifty little query that will list missing indexes for you.
Anyway, the thing is, this particular timeout isn't happening just sometimes, it happens basically all the time for users with high enough reputation. Which implies that it is very dependent on the number of rows in the query.
Normally this would be a query similar to
SELECT TOP 100 Columns FROM Reputation WHERE mid = 2624750 ORDER BY DateTimeAdded DESC which would easily be handled by a RangeScan on the index(mid,DateTimeAdded DESC). (Preferably clustered in this case)
But you know that already, so there's something else going on here.
Have to admit I'm curious.
|
|
|
|
|
Jörgen Andersson wrote: Preferably clustered in this case
Which would almost certainly kill the insert performance.
"These people looked deep within my soul and assigned me a number based on the order in which I joined."
- Homer
|
|
|
|
|
Well, the index exists anyway.
And if I recall correctly, (I haven't seen the reputation history for a while), there isn't very much more data in it.
But, while writing this I realize a possible reason to why this is slow. And then the index obviously can't be clustered, because this is not a table of it's own.
<edit>that's the bad part of making assumptions on something you don't have any knowledge about. </edit>
|
|
|
|
|
We actually do use SQL and have run the Brent script and have our laundry list.
Happy to see your script too!
Current theory: too many indexes which are slowing down writes (and causing locks) which is killing reads.
cheers
Chris Maunder
|
|
|
|




 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 









