
What inside of video analytics
4.89/5 (7 votes)
Principles of video analysis
Introduction

Many people know about OpenCV - great computer vision library. This extensive cross-platform project include many different algorithms and it is not so easy to understand how it works. You can find a variety of publications and examples of how and where to use machine vision, but not about how it works. And this is very important knowledges for understanding of the process, especially when you just starting to study computer vision.
General scheme of the video analysis is presented below.
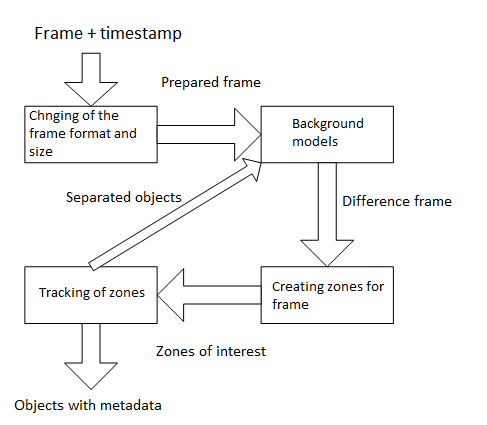
The process is divided into several stages. Information about what is happening in the picture is complemented by new details in each stage. It may also be back references between stages to better respond to the scene changes. Consider the scheme in more detail.
What is the video stream
First of all we need to understand what is a the video stream. There are many formats of video data but their essence is the same: a sequence of frames at a certain rate per second. Frame characterized by resolution and format (the number of bits per pixel and their interpretation: which bits are responsible for a different color). Frames compression could be used to reduce amount of transmitted data, but when frames are displaying on the screen they always decompressed to the original state. Analytics algorithms are always work with uncompressed frames too.
So the video stream is characterized by frame rate, resolution, and bit format.
It is important to note that the computer vision algorythms is always analyse only one frame at the moment. That is frames are processed sequentially. Furthermore it is important to know how much time has passed since the previous frame. This value can be calculated from the frequency but a more practical approach is to append each frame with timestamp.
Changing of the frame format and size
The first step is to prepare the frame. Typically, in this step size of the frame is significantly reduced. The reason is the fact that each pixel of the image will be involved in further processing. Accordingly, than smaller frame size then faster it will work. Of course, it will lost some information while size reducing. But it is not critical and even useful. The objects with which the analytics works mainly large enough to not be lost during compression of the frame. But some kinds of “noise” associated with the quality of the camera, lighting, natural factors and other will be reduced.
Changing the resolution occurs by combining several pixels of the original image into one. Amount of information loss is depends on the pixels combination type.
For example, a square of 3x3 pixels of the original image will be converted to a single pixel. You can sum all 9 pixels, can sum of 4 corner pixels and can take only one central pixel.
Sum of 4 corner pixels:

Sum off all 9 pixels:

Only one central pixel:

The result will always be slightly different by speed and quality. But sometimes it happens that way with losing more information gives a smoother picture than the way that uses all the pixels.
Another action at this stage is to change frame format. Color images are generally not used, since it also increases the processing time. For example, RGB24 contains 3 bytes per pixel. But Y8 contains only one and it does not loose many information:
Y8=(R+G+B)/3.
The result will be the same image but in grayscale:


Background models
This is the most important stage of processing. The purpose of this step is to create a scene background and obtaining the difference between the background and the new frame. Result of processing is significantly depends from quality of algorithms of this stage. Correction of situations when an object is adopted as a background or part of the background is highlighted as an object will be very difficult at the next stages.
In the simplest case you can take a frame with an empty scene as background:

For example, take frame with the object:

If we convert these frames to Y8 and subtract background frame from the frame with the object then we get the following:

For convenience, you can make a binarization: replace the value of all the pixels is greater than 0 to 255. As a result we turn from grayscale to the black-and-white image:

It seems to be all good: well separated from the background object has clear boundaries. But, firstly shadow is highlighted as part of the object. And secondly,you can find artifacts of image noise at top of the frame.
This approach is not good to practical use. Any shadow, glare light, change the camera brightness will spoil the whole result. Therein lies the whole complexity of the problem. Objects should be separated from the background, thus it is necessary to ignore the natural factors and image noise: light reflections, shadows from the buildings and clouds, swaying branches of plants, frame compression artifacts, etc. In addition, if you are looking for the left object it should not become part of the background.
There are many algorithms for solving these problems with varying efficiency. From a simple averaging of the background to the useing of probabilistic models and machine learning. Many of them are included in OpenCV. And it is possible to combine several algorithms that will give even better results. But than more complex the algorithm, then process of the next frame will be longer. If live video has 12.5 frames per second then the system has only 80 milliseconds for processing. Therefore the choice of the optimal solution will depend on the objectives and the resources allocated for its implementation.
Zones creation
A difference frame is formed. We see white objects on a black background:


Now we need to separate objects form a zones that combining the pixels of objects:

For example this can be done by connected component labeling.
At this point you can see all problems of the background model. The man on top is divided into several parts, a lot of artifacts, shadows of people. However, some of these issues can be corrected at this stage. Knowledges about object area, its width and height, pixel density, makes possible to filter out unnecessary objects.
Blue rects are indicating objects which are involved in the further processing and green - filtered objects. Errors can occur here to. As you can see, the man on top divided into several parts has been filtered because of their size. This problem can be solved, for example, through the use of perspective.
Other errors are possible. For example, some objects may be combined into one. So that there is a great field for experimentation at this stage.
Tracking of zones
Finally in the last stage zone are turning into objects. Here are using the result of processing the last few frames. The main task is to determine that the area on two sequential frames is the same object. Signs may be different: size, pixel density, color characteristics, prediction of movement direction, etc. Timestamps are very important at this stage. They allow to calculate the object’s speed and traveled distance.
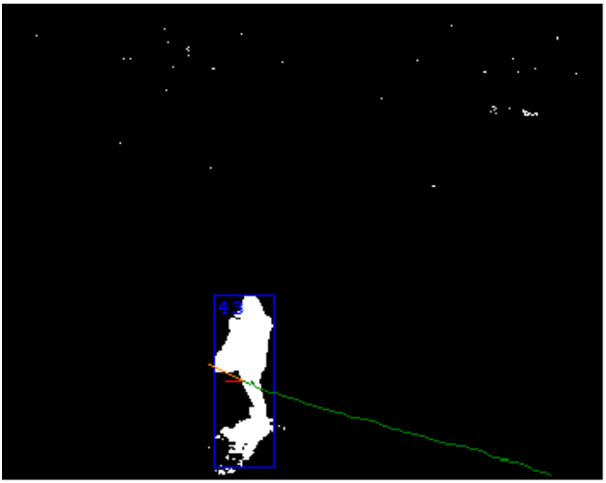
At this stage it is possible to correct the issues of the previous stages. For example, the connected objects can be divided by using history of their movement. On the other hand, there may be a problems too. The most important of them is the intersection of two objects. A particular case of this problem is when a larger object overshadow smaller object for a long time.
Objects for using in the background model
The architecture of the analyse algorithm can include back references which improve the work of the previous stages. The first thing that comes to mind - to use the information about the objects in the scene in the formation of the background.
For example,it is possible to find lost object and did not make it part of the background. Or fight with the “ghosts”: if you create a background with the man on the stage, then when he is gone there will be “ghost” object. Understanding that in this place begins the trajectory of the object can help you to quickly remove the “ghost” from the background.
Results
The result of all stages is a list of objects in the scene. Each of these is characterized by size, density, velocity, trajectory, direction, and other parameters.
This list is used for a scene analytics. You can determine line intersection by the object or a movement in the wrong direction. Or you can count the number of objects in a given area, idle stagger, fall and many other events.
Summary
Modern systems of video analytics have achieved very good results but still they remain complex multi-step process. And the knowledge of the theory does not always gives good practical results.
In my opinion, the creation of a good machine vision systems is a very complicated. Setting algorithms is very hard process and takes long time. It requires a lot of experimentation. And, although in this case OpenCV is very good, but it is not a guarantee of results, because you should to know how to correctly use the tools that it contains.