Introduction
I often use CodeProject's articles and code samples as a source of information on programming related subjects. Probably, this is the time to share some knowledge and experience. With so many relatively close technologies, nowadays it is not easy to select the correct way to solve coding problems and to find effective solutions - from the right choice of platform and programming language, to the many variants that almost any programming task can be implemented. The best and unique feature of the CodeProject model is that a text on a given subject (not only on Microsoft’s technologies as in MSDN, for example) written by a programmer is accompanied by code samples on a given programming language. Thus, the following article with code sample (console application) is supposed to help you in time when you need to process a large volume of structured information. Of course, slightly adapted to your needs, this code can be used in your C/C++ project to read and process a large volume of structured data from an XML file.
Background
There are many ways to read a large volume of data and to process it in your program. For example, you can use SQL to read structured information from a database. You can use programming technologies and a given language functions to read data from an Excel or CSV file. In all these cases, you would have to write your own code to process (parse) the data, which can be an ineffective and error prone solution most of the time. The Document Object Model (DOM) provides a standardized way to read and parse structured data read from an XML file. This is “a platform- and language-neutral interface that allows programs and scripts to dynamically access and update the content, structure, and style of documents” - (www.w3.org/DOM/).
Using the code
DOM provides standard APIs to access an XML document's objects by going through the tree of "nodes" created by the parser. MSDN says: “The DOM implementation is a part of the MSXML parser” (here we use the DOM implementation in Microsoft XML Core Services or MSXML) where the parser creates a physical, tree-like, structure of the document, checks if it is well-formed, and validates, if requested.
These is the elements and attributes structure in the XML file provided with the code sample (this is the stocks.xml file from the MSXML 4.0 SDK):
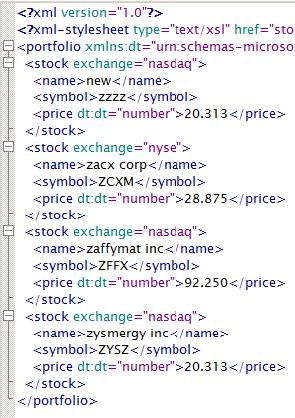
Sample XML file
MSDN, MSXML 4.0 SDK says: “After a document is parsed, its nodes can be explored in any direction; they are not limited to straight-through text file processing. The DOMDocument object exposes properties and methods that allow you to navigate, query, and modify the content and structure of an XML document. Each of the following objects exposes methods and properties that enable you to gather information about the instance of the object, manipulate the value and structure of the object, and navigate to other objects within the tree. For developers using C, C++, these objects are exposed as the following COM interfaces”. Here is the corresponding code:
CoInitialize(NULL);
docPtr.CreateInstance(__uuidof(DOMDocument30));
Then load the document (XML file):
_variant_t varXml(szFileName);varResult = docPtr->load(varXml);
Collect all or selected nodes by tag name:
NodeListPtr = docPtr->getElementsByTagName(strFindText);
docPtr->documentElement->get_nodeName(&bstrItemText);
In the DOM model, “the node can be used to represent elements, attributes, textual content, comments, processing instructions, entities, CDATA sections, and document fragments”. In our sample, we work with elements and attributes only.
Finally, in the for loop, we go through every node of type element and then through the attributes of every element (if exist):
for(i = 0; i < (NodeListPtr->length); i++)
{
if (pIDOMNode) pIDOMNode->Release();
NodeListPtr->get_item(i, &pIDOMNode);
if(pIDOMNode )
{
pIDOMNode->get_nodeTypeString(&bstrNodeType);
BSTR temp = L"element";
for(j = 0; j < length; j++)
{
}
}
}
This is the output of the parsing:

Output of parsing the stocks.xml file
References
History
- 08.2009 - Built-in Visual Studio C++ 6.0
- 29.08.2010 - Recompiled in Visual Studio C++ 2008
- 15.04.2011 - Added images and updated text
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




