
Traceability in Layered Architecture: A Roadmap
4.61/5 (18 votes)
Traceability in layered architecture lets software architects to define, utilize, reuse, and re-engineer existing, current, and future application architectures in a more structured way. This article provides a roadmap to trace multi-layer architectures easily.
Overview
Traceability in layered architecture lets software architects to define, utilize, reuse, and re-engineer existing, current, and future application architectures in a more structured way. This article provides a roadmap to trace multi-layer architectures easily.
Introduction
Multi-layer architecture is one of the most popular and proven models in the current trend of software development. It lets software designers and developers to easily isolate user interface, business logic, and data access logic.
In the last few years, I have worked on several projects done by other developers, to be improved and/or enhanced. Also, I have seen lots of starter kits - sample projects available on the web, and from where a beginner to expert can improve their ideas regarding the latest best practices in layered architecture.
However, while reviewing source codes of projects done by other developers, I always miss a simple document by which I can easily grab the core ideas of the layering, and can update any part along with my own point of view. No matter how big the application or how complex the application architecture is, having a traceability structure helps future developers of a given project, to quickly understand the existing layering model, and/or to utilize/update existing structures by considering the appropriate design and the requirements context.
The traceability model, considering the logical layers, is a very basic document which addresses several common questions, answers, and view points of current or future application architectures.
This article explores some of the common questions and explanation points which will help us form our own traceability model.
Layered Architecture Design Factors: Business Entity
Business entities are the logical data containers which are passed across logical layers. These can be a simple class which contains the data items commonly mapped from data columns from logical and/or physical data tables, or can be complex classes with a high-end overhead.
What is the type of business entity?
For .NET applications, business entities can be categorized as Custom Entities, Typed DataSets, and Generic DataSets. Custom Entities are generally simple and faster than DataSets, whereas they include more involvement from the developer end, as opposed to a DataSet, which includes lots of built-in functionalities, along with several trade-offs in performance. Choosing the right business entity which fits in the application requirements and the development context is one of the basic actions in software architecture.
To which context are Business Entity classes mapped?
For simple applications, mapping directly from a physical table to logical business entities reduces lots of cost in programming, especially while using code generators. However, in simple as well as complex applications, besides mapping physical tables, there are a few areas which might not be suitable to be mapped directly from databases tables.
To map one-to-many relations from the database to the logical application model, some designers create a base container class for the business entities, which includes both the parent and child business entities as data elements. It facilitates complex data containers to be passed through layers simply.

Where and how the joined operation (fetched from multiple data tables) is placed in business entities?
When we need to retrieve result sets from multiple database tables via a join operation, a common practice is to use a Generic DataSet to store the result. We can consider Custom Business Entities for cases where the joining operation can be determined at software design time, which provides a faster execution time than DataSets.
Also, in some cases, a joining operation is required to be implemented in the application end, rather that at the database end, especially when multiple entities are required to be combined from the database and/or web service sources.
How do you map OOP concepts to a relational database design?
Let’s consider a simple sample:
- Contact DB table: Contact ID (primary key), Contact Name, Contact Address
- Employee DB table: Employee ID (primary key), Employee Joining Date
- Customer DB table: Customer ID (primary key), Customer Birth Date
Now, to utilize the object oriented inheritance concept in a relational database model, we can create a one to one relation from the Contact table with the Employee and Customer tables, where besides the primary key, the Employee ID and the Customer ID will be used as foreign keys of the Contact table, with the concept that all Employees and Customers are considered as a “Contact” object.
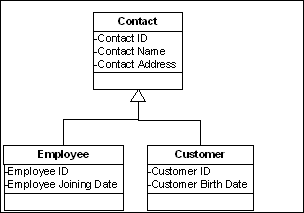
Now, if we wish to map this idea to a real world OOP code, we will create a business entity named “Contact” with the “Employee” and “Customer” business entities as inherited sub classes. The corresponding BLL and/or DAL (Data Access Layer) class of “Employee” or “Customer” can also be inherited from the BLL (Business Logic Layer) and/or the DAL class of “Contact”, to perform the required operations in an object oriented manner.
Are there any special considerations for “typed” entities?
There are a few entities in which data does not change very frequently, but one or two items are added over a few months. For instance, user type, product category, order type, and payment mode. For better database operations, the values of these fields are kept in a database and referred to other entities as foreign keys. But, interestingly, the values of these “Type” entities are used very frequently in the coding layer, where developers have to use the hard-coded primary key value or the string value of this type to perform any business logic or UI (User Interface) logic, which reduces the "Readability" or the “Maintainability” of the code (what if we change the type name; in that case, we need to search for the string or the primary key value from the whole project!).
As the .NET framework supports the enumeration type, where possible, the enumeration type can be implied upon these business entities. Where adding or changing to any of its values is required, the developer only needs to concentrate on the code segment where the enumeration values are set.
Layered Architecture Design Factors: Logical Layers
How many layers will be considered? Why?
Here, we will address a few primary design considerations regarding logical layers. It is not mandatory that we need to build each and every system in the popular “Three Layer” model. There might be a design context where single or two layer approaches can be a good design choice. Here, we need to clarify the layered division and their responsibilities. We can also address some present and future possible considerations, supporting the current division of layers, such as, regarding multiple UI (Windows Forms, Web Forms), data sources (SQL Server, XML, Oracle etc.), platforms, etc.
Do you use a cache layer?
To improve the application performance, “Caching” is one of the popular techniques in the current trend of best practices. Some designs support caching data in the UI interface level, where a built-in cache mechanism is available. Sometimes, putting the cache mechanism in a separate layer provides better isolation and control over the application space. If so, the cache isolation, expiration, and the coupling with other layers policy should be addressed properly.
How the layers communicate with the next level layers?
For a three layered application model, in some cases, the UI interface layer can use the DAL directly, rather than using it via the BLL (i.e., the “immediate next layer”). This type of application model generally includes a small set of classes and methods in the business logic layer, ignoring the mapping of all functionalities from DAL to BLL. This design issue provides a sort of performance, by reducing the engagement of intermediate layer(s).
On the other hand, we can have a model, where a complete set of functionalities is needed to be present in the BLL, and is “tightly coupled”. In this context, UI layers can’t use the functions of the DAL directly.

At this point, the software architect is needed to address this design issue clearly.
What are the mapping criteria for DAL classes and CRUD methods?
DAL classes can be defined with respect to physical or logical business entities, BLL classes, and vice versa. This mapping process can include one to one, one to many, or many to many techniques.
For example, we have two business entities (physical or logical), named “Order Summery” and “Order Items”, for an e-commerce application. Having a one-to-one mapping relation to DAL will contain two separate DAL classes, “OrderSummeryDAL” and “OrderItemsDAL”.
What are the mapping criteria for BLL classes and CRUD methods?
BLL classes can be defined with respect to physical or logical business entities, DAL classes, and vice versa. This mapping process can include one to one, one to many, or many to many techniques.
For example, we have two business entities (physical or logical), named “Order Summery” and “Order Items”, for an e-commerce application. Having a one-to-many mapping relation with BLL and DAL in the class level can contain one separate BLL class, “OrderBLL”, and two separate DAL classes, “OrderSummeryDAL” and “OrderItemsDAL”. The “CreateOrder” method of the “OrderBLL” class can call the “CreateOrderSummery” and “CreateOrderItem” methods of “OrderSummeryDAL” and “OrderItemsDAL”, respectively, to complete the entire database create operation for a whole order, as shown in the figure below:

Even having a one-to-one relation with the BLL and DAL classes can include a one-to-many relation in the method level. For example, we have a BLL class “OrderBLL” and a DAL class “OrderDAL”. Having a one-to-many relation in the method level will include a “Create” method in OrderBLL which basically calls the “CreateOrderSummery” and “CreateOrderItem” methods, as shown in the figure below:

The appropriate design issues need to be defined at this point.
For CRUD operations in the BLL, when should we use the business entity and when to use the parameters?
Business entities can be passed as method parameters in the BLL, or all data elements can be passed separately in BLL methods as method parameters. Some designs may also support the Business Entity class to include the corresponding CRUD methods, which basically doesn’t require any data element to be passed in the CRUD methods.
For CRUD operations in the DAL, when should we use the business entity and when to use parameters?
Business entities can be passed as method parameters in DAL, or all data elements can be passed separately in DAL methods as method parameters. Some designs also support the Business Entity class to include the corresponding CRUD methods, which basically doesn’t require any data element to be passed in the CRUD methods.
How do we generally handle one to many (database) relationships in logical layers?
One to many relations are one of the most core considerations in relational database design contexts. However, while mapping the database tables to the logical layers, it needs to be defined clearly, how it has been handled. For instance, designs can include a container class that holds parent and child classes as properties, or can include separate classes for all data entities regardless of the parent/child relationship.
How do we generally handle many to many (database) relationships in logical layers?
Generally, a many-to-many relation between two data tables forms a third table which contains the primary key of both tables. For instance, if there are two tables or data entities, named “Person” and “Address”, and if there is a “many to many” relation between these entities, there would be another table which will keep this relation in the table, which could be named as “Person-Address”. Some logical models support creating a separate logical entity in the application layered components (DAL, BLL, BE etc.) for the many-to-many table, and some applications embed the operations in the logical entity of any of the two primary tables.
What are special cases we need to consider?
The common model of the logical layers which can be fit to most business entities can be implemented using code generator tools, which saves a lot of developer time. Besides the common model, there might be some cases which require special consideration. Specific and complex business logic can be an example of such special cases.
How the null values are handled?
Null values are one of the basic considerations, not taking care of which may raise lots of confusions and errors while the application is running live. Some application architectures support a model which puts null values to the database when the user provides empty data from the user interface. For string/text type, data is sometimes saved as an empty string (i.e., String.Empty). But, it creates confusion where empty string itself is considered as a value. Also, besides string/text type data, special care is required for other types of data (number, fraction, date time etc.) with respect to null values being saved and retrieved to and from the physical database tables. These considerations are required to be addressed.
Where are exceptions thrown for invalid values?
In some cases, invalid values are handled from the user interface level, by using validation controls. However, we need to address the points, where and how we handle invalid values, which are not been validated from there user interface layer and/or are required to be validated in the code level. These considerations are to be addressed at this point.
Which portion of the DB utility classes are vendor specific?
To perform database operations from applications, generally, the DAL uses some DB utilities that helps to write minimal lines of code to perform data operations. In the data utility classes, some classes and methods might be specific to the vendor (for instance, the SQLHelper class will only work to perform operations on MS SQL Server), and some classes and methods might be used regardless of database vendors. These issues, along with the boundaries, should be addressed here.
Layered Architecture Design Factors: Physical Tiers
How are the logical layers connected?
Logical layers such as BLL, DAL, CL, etc. can be hosted in the same machine, or can be distributed in separate machines, specially where high end scalability is required. The relation and isolation among logical and physical tiers are required to be defined and explained with an appropriate design goal.
While considering logical layers in a distributed environment, there are several technologies available. SOAP/HTTP based web services or .NET Remoting can be considered, each of which has its own merits and de-merits. These considerations are required to be addressed at this point.
Layered Architecture Design Factors: Some Basic Design Issues
Do we use transaction? If so, is it in the DAL or the SP layer? Why?
Transaction is a mechanism where a batch of operations can be rolled back for any failure at a mid point of the whole process, or can be committed after successful completion of all the operations. Transactions can be used in both the database level and/or the application level.
Do we use cascading on CRUD operations? If so, is it in the DAL or the DB layer? Why?
Cascading is a technique that resides between the relations between two database tables. It enables records of child tables to be deleted/updated with respect to the corresponding records of the parent table records. Besides the database level, this operation can also be considered in the inter-mediate logical layer. Software designers are required to define the appropriate explanation regarding this consideration.
Where and why do we use inline SQL, LINQ queries, CLR stored procedures, or built-in stored procedure to manipulate data?
To manipulate database objects, there are several ways available to developers, such as inline SQL, LINQ queries, CLR stored procedures, or built-in stored procedures. Each of them has its own benefits and trade-offs. These issues need to be addressed at this point.
What are the standard practices when we need high performance?
There are several best practices available in the developer community defined by top experts. However, while considering the best practices regarding performance, of course, there will be some trade-off (for instance, security, usability etc.). According to the application context, these points should be adjusted properly.
What values are returned by the Create/Update/Delete methods (both in BLL/DAL) to the caller, notifying the success of a data operation?
Create methods may return the generated primary key of the new record, to the caller, so that it can be used if required. Returning a default value may be considered as the failure of the data operation. Also, since Update or Delete operations don’t usually need to return any value, these types of methods can only return Boolean values notifying the success/failure status.
How do we consider naming conventions to write a new business entity, BLL, and DAL?
Following a naming convention on DB objects, class names, and methods makes coding and future modifications easier. For example: the BLL CRUD methods for a given business entity can be written as:
GetEmployeeById: that returns a single instance of an employee business entity.CreateEmployee: that creates a new employee business entity.
What should be performed when there is an addition or modification on existing relations, entities, and attributes?
This is one of the very important issues in traceability of software architecture. Some easy sample walkthroughs are required to be provided very clearly. For instance, what steps needs to be performed while adding a new entity to the system, or adding a data element in an existing entity etc.
Conclusion
This article explored some common design considerations to be traced while developing a multi-layer application architecture. However, you can create your own traceable models by adding and/or removing issues provided here.
Stay tuned with the latest updates along with blank templates @ code.msdn.
Appendix
- DAL: Data Access Layer
- BLL: Business Logic Layer
- CRUD: Create Read Update Delete