Introduction
Huffman encoding is one of the well known lossless compression methods I know of. I tried to implement it alongside with RLE (run length encoding) and in this article I will try to explain the basics of the encoding and the implementation (the one I used).
The first part will be about the Encoding itself and how I implemented it. If you'll look inside the source project, you'll see more classes than will be explained in the article. They will be explained in the next part...
One of the classes you also see in the test project is the PromptInput class, which is basically a prompt with auto-completion for console applications. Quite useless, but pretty fun to code.
Background
Huffman Encoding is based on the idea that some character's frequencies are higher than others in almost every file, so instead of encoding all the characters as 8 bits, all the frequent characters are represented in a shorter manner (depends on how the encoding tree was built, but usually 3-5 bits), as you may guess, some of the characters will be represented in a longer manner (more than 8 bits) but the gain in space is much better than the loss.
The basic idea is to gather character frequencies from the text and build an Encoding tree so when reading the stream of bits, every path will get you to a leaf and every path will be unique, so if you used 11 to represent an 'A' you can't use 110 to represent anything else, you'll have to branch off before the last 1, e.g. 10, or later on 011.
RLE means - take any instance of a repeating character and compress it, by means of adding a special header character (a symbol you decide on), counter (ASCII representation of the amount repeated) and the character itself. For example (if your header is 'A') -> 'BBBBB' will be compressed into 'A5B' (only the 5 will be in ASCII value) and 'A' itself will be written as 'A1A' (We lose here.. ). When you decode the stream, everytime you'll encounter an 'A' you'll expect a counter and the character.
Building the Tree
This method counts frequencies and is pretty straightforward:
for (int i = 0; i < 256; i++)
mapper[i] = -1;
foreach (var let in text) {
if (mapper[let] != -1) {
frequency[mapper[let]]++;
}
else {
literals.Add(let);
mapper[let] = literals.Count - 1;
frequency.Add(1);
}
}
for (int i = literals.Count - 1; i > 1; i--) {
int mini = i;
for (int j = 0; j < i - 1; j++)
if (frequency[j] < frequency[mini]) {
mini = j;
}
if (mini != i) {
mapper[literals[i]] = mini;
mapper[literals[mini]] = i;
int temp = frequency[i];
frequency[i] = frequency[mini];
frequency[mini] = temp;
byte temp2 = literals[i];
literals[i] = literals[mini];
literals[mini] = temp2;
}
}
A few explanations - We map every ASCII from an array of size 256 to a smaller literals List. Helps speed things up. We count the frequencies, and sort them from the most frequent to the least frequent. All we need now is the code list (which is the function that translates ASCII characters to their shorter Huffman version), so we will build an encoding tree, and walk it (In order walk, see inOrder method) to extract the codes.
List<tree> nodes = new List<tree>(0);
for (int i = 0; i < literals.Count; i++)
nodes.Add(new Tree(true, literals[i], frequency[i]));
int first = literals.Count - 1, second = literals.Count - 2;
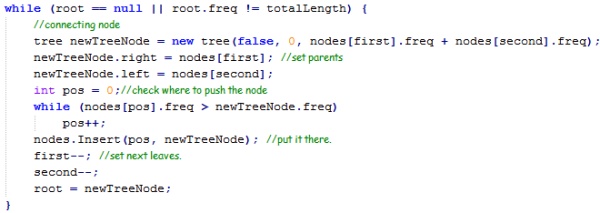
while (root == null || root.freq != totalLength) {
Tree newTreeNode = new Tree(false, 0, nodes[first].freq + nodes[second].freq);
newTreeNode.right = nodes[first];
newTreeNode.left = nodes[second];
int pos = 0;
while (nodes[pos].freq > newTreeNode.freq)
pos++;
nodes.Insert(pos, newTreeNode);
first--;
second--;
root = newTreeNode;
if (first == 0 && totalLength == 0)
totalLength = root.freq;
}
Here we create the tree, by going from the least frequent nodes, connecting them to a new node, summing the frequencies, and inserting the node to the nodes list (to speed things up) in the appropriate place (so as not to break the order), then we continue connecting, until the root node has all the text under it. After that, we walk the tree and build a look up table of codes that translate a byte into a series of bits (using a list of bytes for convenience).
Encoding is done pretty easily now, by reading the byte array and encoding every byte to its code. Manipulating the bits is done with bit shifting into an unsigned long. (Here we check for repeating characters to encode repeating characters using RLE.
var k = codes[mapper[text[i]]];
if ((i + 1) % 500000 == 0) {
progress = (int)(((float)i / (float)text.Length) * 100);
}
for (int l = 0; l < k.Count; l++) {
buffer = buffer | ((ulong)k[l] << pos);
if (++pos == 64) {
if (prevBuffer != buffer || initial) {
if (rle < 2 && prevBuffer != ulong.MaxValue) {
if (!initial)
for (int d = 0; d <= rle; d++)
myWrite.Write(prevBuffer);
}
else {
myWrite.Write(ulong.MaxValue);
myWrite.Write(rle);
myWrite.Write(prevBuffer);
}
... snip
Using the Code
Here's a small example of how to use the encoding method using the EncodeByteArray method.
HuffManEncoder encoder = new HuffManEncoder();
packedSize = encoder.EncodeByteArray(byteArray, newfileName);
Points of Interest
In the next part, I will explain the wrapper classes around the HuffManEncoder class, that help you manage archive files' extraction and creation.
Just Babble
Since I am not a native English speaker, you'll probably find some (or a lot) of mistakes in my article. I plead ignorance. :)
I am a third year student in the Information Systems Degree, and you can visit me and my friends in our nice little blog.
I'll be happy to hear from you, see you in the next part!
History
I live in israel, I'm a third year student learning Information Sciences, in Kinneret Academic college (Near the Sea of Galillee). I work as a web site and system developer in Amsalem Tours.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




