
Haar-feature Object Detection in C#
4.97/5 (133 votes)
A description of how it was possible to achieve real-time face detection with some clever ideas back in 2001
- Download source - 3.5 MB
- Download sample - 1.2 MB
- Download the full version of the Accord.NET Framework
Contents
Introduction
In 2001, Viola and Jones proposed the first real-time object detection framework. This framework, being able to operate in real-time on 2001 hardware, was partially devoted to human face detection. And the result everyone knows - face detection is now a default feature for almost every digital camera and cell phone in the market. Even if those devices may not be using their method directly, this now ubiquitous availability of face detecting devices have certainly been influenced by their work.
Now, here comes one of the more interesting points of this framework. To locate an object in a large scene, the algorithm simply performs an exhaustive search using a sliding window, using different sizes, aspect ratios, and locations. How come something like this could be so efficient?
And this is where the authors' contributions kicks in.

This article should present the reader to the Viola-Jones object detection framework, and guide on its implementation inside the Accord.NET Framework. A sample application is provided so interested readers can try the image detection and see how it can be performed using the framework.
Background
The contributions brought by Paul Viola and Michael Jones were threefold. First, they focused on creating a classifier based on the combination of several weak classifiers, based on extremely simple features in order to detect a face. Second, they modified a then standard algorithm for combining classifiers to generate classifiers which could even take some time to actually detect a face in a image, but which could reject regions not containing a face extremely rapidly. And third, they used a neat image representation which could effectively pre-compute nearly all costly operations needed for running their classifier at once.
The Simple Features
Most of the time, when one is about to create a classifier, we suddenly have to decide which features to consider. A feature is a characteristic, something which will hopefully bring enough information in the decision process so the classifier can cast its decision. For example, suppose we are trying to create a classifier for distinguishing whether a person is overweight. A direct choice of features would be the person's height and weight. Hair color, for example, would not be a very informative feature in this case.
So, let us come back to the features chosen for the Viola-Jones classifier. The features shown below are Haar-like rectangular features. While it is not immediately obvious, what they represent is the differences in intensity (grayscale) between two or more adjacent rectangular areas in the image.
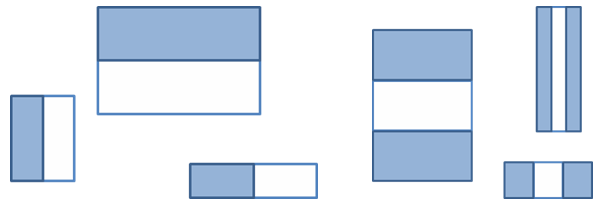
For instance, consider if one of those features is placed over an image, such as the Lena Söderberg's image picture below. The value of the feature would be the result of summing all intensity pixels in the white side of the rectangle, summing the pixels in the blue side of the rectangle, and then computing their difference. Hopefully, it should be clear by the images on the right side of the sequence why those rectangular features would be effective in detecting a face. Due to the uniformity of shadows in the human face, certain features seems to match it very well.

The image above also gives an idea on how the search algorithm works. It starts with either a large (or small) window and scans the image exhaustively (i.e., such as by dislocating the window some points to the right, and going down at the end of the line). When a scan finishes, it shrinks (or grows) this window, repeating the process all over again.
The Attentional Cascade
If the detector wasn't extremely fast, this scheme most likely won't have worked well in real time. The catch is that the detector is extremely fast at discarding unpromising windows. So it can quickly determine if a region does not contains a face. When it isn't very sure about a given region, it spends more time trying to check that it isn't a face. When it finally gives up on trying to reject it, it can only conclude it is a face.
So, how does the detector do that?

It does so by using an attentional cascade. A cascade is a way of combining classifiers in a way that a given classifier is only processed after all other classifiers coming before it have already been processed. In a cascade, the object of interest is only allowed to proceed in the cascade if it has not been discarded by the previous detector.
The classification scheme used by the Viola-Jones method is actually a cascade of boosted classifiers. Each stage in the cascade is itself a strong classifier, in the sense it can obtain a really high rejection rate by combining a series of weaker classifiers in some fashion.
A weak classifier is a classifier which can operate only marginally better than chance. This means it is only slightly better than flipping a coin and deciding if there is something in the image or not. Nevertheless, it is possible to build a strong classifier by combining the decision of many weak classifiers into a single, weighted decision. This process of combining several weak learners to form a strong learner is called boosting. Learning a classifier like this can be performed, for example, using many of the variants of the AdaBoost learning algorithm.
In the method proposed by Viola and Jones, each weak classifier could at most depend on a single Haar feature. Interestingly enough, therein laid a solution to a untold problem: Viola and Jones had patented their algorithm. So in order to use it commercially, you would have to license if from the authors, possibly paying a fee. As a way to extend the detector, Dr. Rainer Lienhart, the original implementer of the OpenCV Haar feature detector, proposed adding two new types of features and transforming each weak learner into a tree. This later trick, besides helping in the classification, was also sufficient to get out of the patent protection of the original method.
Well, so up to now, we have a classification system which can be potentially fast at rejecting false positives. However, remember this classifier has to operate on several scaled regions of the image in order to completely scan a scene. Computing differences in intensities would also be quite time consuming (imagine summing a rectangular area again and again, for each feature, and recomputing for each re-scaling). What can be done to make it faster?
The Integral Image Representation
Caching. This is often an optimization we perform everyday when coding. Like caching the output of a variable out of a loop instead of recomputing it every time. I think most are familiar with the idea.
The idea for making the Haar detection practical was no different. Instead of recomputing sums of rectangles for every feature at every re-scaling, compute all sums in the very beginning and save them for future computations. This can be done by forming a summed area table for the frame being processed, also known as computing its integral image representation.

The idea is to compute all possible rectangular areas in the image. Fortunately, this can be done in a single pass over the image using a recurrence formula:

or, to put it simply:
![]()
In an integral image, the area for any rectangular region in the image can be computed by using only 4 array accesses. The picture below may hopefully help in illustrating this point.

The blue matrices represent the original images, while the purple ones represent the images after the integral transformation. If we were to compute the shaded area in the first image, we would have had to sum all pixels individually, reaching the answer of 20 after about 6 memory accesses. Using the integral image, all it is needed is a single access (but this only because we were in the border). In case we are not in the border, all it would require would be at max 4 array accesses, independently of the size of the region; effectively reducing the computational complexity from O(n) to O(1). It will require only two subtractions and one addition to retrieve the sum of the shaded area on the right image, as described in the equation below:

Source Code
Finally, the source code! Let's begin by presenting a class diagram with the main classes for this application.

I am sorry if it is a bit difficult to read, but I tried to keep it as dense as possible so it could fit more or less under 640px. You can click it for a larger version, or check the most up-to-date version in the Accord.NET Framework site.
{kind=link}
Well, so first things first. The exhaustive search explained before (in the introduction) happens in the HaarObjectDetector. This is the main object detecting class. Its constructor accepts a HaarClassifier as parameter which will then be used in the object detection procedure. The role of the HaarObjectDetector is just to scan the image with a sliding window, relocating and re-scaling as necessary, then calling the HaarClassifier to check if there is or there is not a face in the current region.
The classifier, on the other hand, is completely specified by a HaarCascade object and its current operating scale. I forgot to say, but the window does not really need to be re-scaled during search. The Haar features are re-scaled instead, which is much more efficient.
So, continuing. The HaarCascade possesses a series of stages, which should be evaluated sequentially. As soon as a stage in the cascade rejects the window, the classifier stops and returns false. This is best seen by actually checking how the HaarClassifier runs through the cascade:
/// <summary>
/// Detects the presence of an object in a given window.
/// </summary>
///
public bool Compute(IntegralImage2 image, Rectangle rectangle)
{
int x = rectangle.X;
int y = rectangle.Y;
int w = rectangle.Width;
int h = rectangle.Height;
double mean = image.GetSum(x, y, w, h) * invArea;
double factor = image.GetSum2(x, y, w, h) * invArea - (mean * mean);
factor = (factor >= 0) ? Math.Sqrt(factor) : 1;
// For each classification stage in the cascade
foreach (HaarCascadeStage stage in cascade.Stages)
{
// Check if the stage has rejected the image
if (stage.Classify(image, x, y, factor) == false)
{
return false; // The image has been rejected.
}
}
// If the object has gone all stages and has not
// been rejected, the object has been detected.
return true; // The image has been detected.
}
And that's it. Now comes the Classify method of the HaarCascadeStage object. Remember that each stage contains a series of decision trees. All we have to do is then to process the several decision trees, and check if it is higher than a decision threshold.
/// <summary>
/// Classifies an image as having the searched object or not.
/// </summary>
public bool Classify(IntegralImage2 image, int x, int y, double factor)
{
double value = 0;
// For each feature in the feature tree of the current stage,
foreach (HaarFeatureNode[] tree in Trees)
{
int current = 0;
do
{
// Get the feature node from the tree
HaarFeatureNode node = tree[current];
// Evaluate the node's feature
double sum = node.Feature.GetSum(image, x, y);
// And increase the value accumulator
if (sum < node.Threshold * factor)
{
value += node.LeftValue;
current = node.LeftNodeIndex;
}
else
{
value += node.RightValue;
current = node.RightNodeIndex;
}
} while (current > 0);
}
// After we have evaluated the output for the
// current stage, we will check if the value
// is still lesser than the stage threshold.
if (value < this.Threshold)
{
// If it is, the stage has rejected the current
// image and it doesn't contains our object.
return false;
}
else
{
// The stage has accepted the current image
return true;
}
}
Well, if I didn't interpret something horribly wrong, this should be it. Each decision node in a tree contains a single feature, and a single feature may contain two or three rectangles. Those features may also be tilted, but I will restrain from explaining tilted features, it would just add complication and the article already seems too long! It is better to jump on how to use the code.
Using the Code
Using the code is rather simple. The framework already comes with some default HaarCascade definitions available as instantiable classes (no need for *.xml files). Creating a detector can be done like this:
// First we create a classifier cascade
HaarCascade cascade = new FaceHaarCascade();
// Then we feed this cascade into a detector
var detector = new HaarObjectDetector(cascade, 30);
As a side node, it could be interesting to note that those definitions have been created automatically from OpenCV's *.xml definition files using a class generator conveniently named HaarCascadeWriter. However, to have written something, certainly the definitions had first to be loaded into the framework. For this reason, the framework can open OpenCV's definition files using standard .NET serialization.
Now that the detector has been created, we can process an image by calling:
// Process frame to detect objects
Rectangle[] objects = detector.ProcessFrame(picture);
And then we can finally mark those rectangles in the original picture using:
// Create a rectangles marker to draw some rectangles around the faces
RectanglesMarker marker = new RectanglesMarker(objects, Color.Fuchsia);
// Applies the marker to the picture
pictureBox1.Image = marker.Apply(picture);
And the result can be seen in the sample application, available for download in the top of the article. Hope you find it interesting!

Points of Interest
First and foremost, let me emphasize it: portions of the code were based on the algorithmic understanding provided by reading the excellent ActionScript implementation by Masakazu Ohtsuka on his project Marilena. As such, sections of this project follows the same BSD license as Marilena, being also dual licensed under the LGPL.
Some notes about the sample application: the sample application is processing a 600 x 597 picture on its entirety. In my 2008' Core 2 Duo notebook, it takes about 400ms to detect all five faces in the picture using parallel processing. This time drops to about 10ms if detection is restricted for a single face, starting from larger window sizes. On a typical application, the image would have been resized to much smaller dimensions before running a detector, achieving much faster detection times.
And by the way; the article presented a rather simplistic description of the method. For example, the Haar features have a justification for their name. They are based on the Haar Wavelet basis functions used, among others, by PAPAGEORGIOU, OREN and POGGIO, 1998. I have also left the tilted Haar features out of discussion, but they can be computed by computing a special tilted integral image before processing begins (the full framework version offers complete support for them). Another thing that went out of discussion is the learning of such classifier. However, I wouldn't put much hope on implementing a demonstrable version of it for this article. Learning a cascade of boosted classifiers could take weeks.
And finally; I am aware the Haar cascade detection may also have been discussed several times, even here in CodeProject. Other articles also deal with face detection. However, what is being shown here is not a port, nor a wrapper around native libraries. This is a pure C# application. And besides, using something already done is only half the fun.
Conclusion
In this article, we reviewed one of the most basic methods for face detection. This method was a variant of the popular Viola & Jones method based on rectangular haar-like features, as described by Viola & Jones (2001) and further aprimorated by Lienhart. The code presented here is part of the Accord.NET Framework, a framework for building scientific computing applications in .NET offering support for machine learning and machine vision methods such as the ones devised here. If you feel curious, check the Accord.NET Machine Learning Framework project page. I promise you won't be disappointed  .
.
References
- Viola and Jones, "Rapid object detection using a boosted cascade of simple features", Computer Vision and Pattern Recognition, 2001
- Lienhart, R. and Maydt, J., "An extended set of Haar-like features for rapid object detection", ICIP02, pp. I: 900–903, 2002
- Papageorgiou, Oren and Poggio, "A general framework for object detection", International Conference on Computer Vision, 1998.
- Masakazu Ohtsuka, "Project Marilena", SPARK project. Available from: http://www.libspark.org/wiki/mash/Marilena
History
- 16th August, 2012: First version submitted
- 2nd December, 2014: Updating project links