
Dazzling Dashboards and Business Intelligence with Azure Synapse Analytics Part 2: Importing and Analyzing Business Intelligence Data
5.00/5 (1 vote)
In this article we learn how to import and analyze business intelligence data.
In the first article in this series, we learned how Azure Synapse Analytics brings together all the tools that data scientists and business intelligence (BI) specialists need to get the most out of their data, and discussed the specific tools we need. In this article, we’ll explore how to import and analyze our data.
We’ll work with the Contoso BI Demo Dataset for Retail Industry, a fictional company’s expansive sales and organizational dataset. It contains an extensive collection of tables. We won’t need all of them, but our project’s first step is to get the data into the cloud on Azure. The dataset is a full backup of an SQL Server database, so we can restore it then push the tables we want to the cloud.
Restoring the Dataset to SQL Server
Before restoring the data, ensure you have SQL Server running or install and run SQL Server for free. Also, install SQL Server Management Studio (SSMS) on your computer to connect to the databases. Then, open and run SSMS and select Database Engine to connect to your local SQL Server via its server name (like localhost\SQLEXPRESS01).

Then, we download and open ContosoBIdemoBAK.exe to extract the ContosoRetailDW.bak file. We can place the file anywhere on our computer.
Next, we right-click on the Databases folder and select Restore Database to open the wizard dialog. In this wizard, we switch the Source option to Device and click the ellipsis button to Add the extracted ContosoRetailDW.bak file, then click OK to start the restore process.



Once the database finishes restoring, we can run SQL queries locally on any of the tables.

Migrating Data to the Cloud
Let’s now create an Azure SQL database on the cloud where we can migrate this data.
Log in to the Azure portal or create an account with $200 of free credits. Use a non-personal email address because we’ll use Power BI later (for example, don’t use a Gmail, Hotmail, or telecommunications services email address).
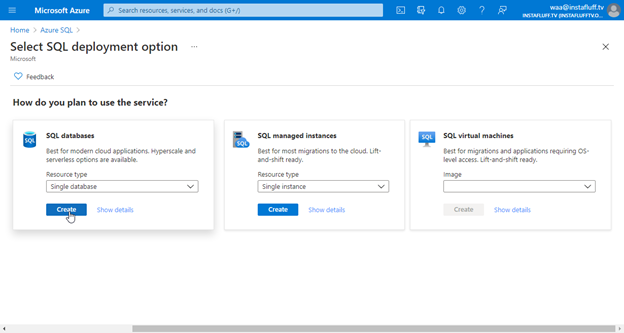
Then, in the search bar, we find and select Azure SQL. Then on that page, we click + Create to start setting up a new SQL database.

We then choose a Single database, create a new Resource group, name the database, and create a new Server for the database. Save the server’s name and login information. We’ll need them to connect and migrate our data from SSMS.
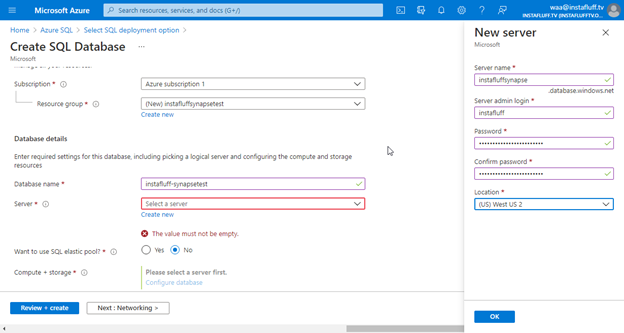
Next, we press Review + Create, then Create to deploy the new server and database. Then, we’ll wait until it completes.


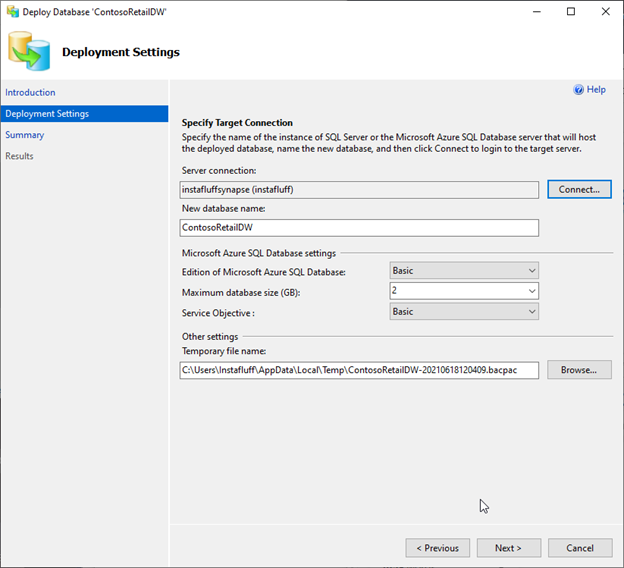
Once the deployment completes, we can go back to SSMS and push the local database to Azure by right-clicking ContosoRetailDW and selecting Tasks > Deploy Database to Microsoft Azure SQL Database to bring up the settings menu.
Note: The GeoLocation and Geometry columns in the dbo.DimStore table may prevent the data in this table from deploying correctly. If so, we can delete these columns inside SSMS before deploying them to Azure SQL.



We can now use the Azure SQL login credentials we saved earlier to connect to the cloud database. We press Connect and choose SQL Server Authentication in the dropdown menu, enter the server’s name, enter our login credentials, and then connect.
You may be prompted to sign in to Microsoft Azure to create a New Firewall Rule. If this happens, you can open the SQL server from the Azure Portal, open Set server firewall, then enable Allow Azure services and resources to access this server, click + Add client IP, and press Save.


We then click Next, then Finish. Now, Azure begins migrating the entire database to an SQL Server on Azure. This can take a while (up to a few hours) depending on Internet connection and the type of Azure SQL instance selected. So, this is a good time to grab a snack.



Once the data is on the cloud, we won’t need the local SQL database or the backup files. You can delete them now if you’d like.
Setting up the Azure Synapse Analytics Workspace
We’re now ready to start working with our data in Azure Synapse Analytics.
We first find Azure Synapse Analytics in the Azure portal and click + Create to configure a new Azure Synapse workspace.


Next, we select the Subscription and Resource group and name our workspace. Azure Synapse Analytics will place Data Lake Storage where any data blobs reside. So, we click Create new account below the Account name dropdown menu and set a File system name.

Then, we go to the Security tab and configure a set of SQL administrator credentials. The workspace’s SQL pools use these credentials for working with the data in queries and notebooks.

We then finish initializing the workspace by pressing Review + create, then create. Azure Synapse Analytics then begins the deployment process.


After Azure Synapse Analytics creates the workspace, we open the Azure Synapse workspace in the Resource group.

Then click the workspace web URL.

Next, we need to add a dedicated SQL pool to hold and transform the data we use in our analysis. First, we open the Manage tab at the bottom of the left-side icons. Then, in SQL pools, we click + New, add a name, and select our desired performance level (depending on our budget and performance needs). Then, we click Review + create and Create to deploy the workspace’s new SQL pool.




Lastly, we need a Spark pool to run the code within our notebooks. Let’s open the Manage tab again, select Apache Spark pools, and click + New. We name the Spark pool, select the node size, and choose the number of nodes (depending on our needs and budget). Then, we click Review + create and Create to deploy the workspace’s new Spark pool. Now we’re all set to start working with our data.




Ingesting Contoso Data into Synapse
We can now ingest the Contoso BI data into our workspace. First, we click the Home tab in the workspace. Then we click Ingest.
Let’s start a one-time data load from our Azure SQL database. If this was a production scenario, we could schedule this copy data pipeline to occur regularly, such as daily, weekly, or monthly. Then the latest data is always automatically ready and available.


We need to create a new connection to our Azure SQL database. So, we set the source type to Azure SQL Database, then click + Create new connection.

Then, we select our Azure subscription, server name, and set “ContosoRetailDW” as our Database name. We can use our saved SQL authentication credentials to connect. Let’s click Test connection to ensure we set everything up correctly, then click Create.

We don’t need all the tables for our project, so we only checkmark the following tables in the source tables list:
- dbo.DimChannel: Sales channel reference list (for example, store, online, catalog, and reseller)
- dbo.DimProduct: Product reference list
- dbo.DimPromotion: Promotion reference list
- dbo.DimStore: Store reference list
- dbo.FactSales: Table of all sales
Then, we click Next and select the dedicated SQL pool we deployed earlier as the destination connection. We continue to press Next until Azure Synapse Analytics creates the pipeline and it begins running. It takes a moment to finish setting up the pipeline. We can click Monitor to watch the pipeline in progress and wait until it completes.


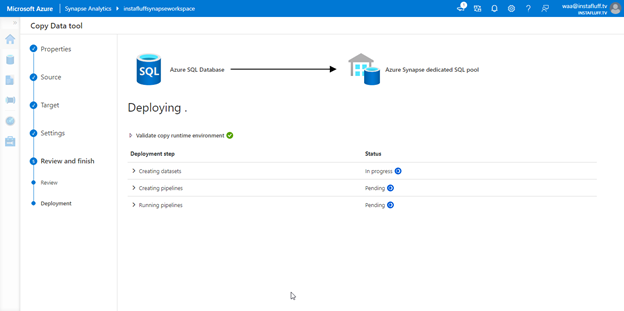

Exploring Data in Azure Synapse Analytics
Once the data copies into the SQL pool, we’re ready to work with the data in Azure Synapse Analytics. We’ll go to the Data tab (second icon from the top in the left-side menu) and expand the SQL pool from the list. We should see the imported tables inside. Let’s try exploring the FactSales table for a quick test.
We right-click the dbo.FactSales table or left-click the ellipsis (Actions) button and choose SELECT TOP 100 rows. Azure Synapse Analytics creates a new SQL script in the workspace and runs the query immediately to bring up a table of the rows.

Let’s finish by creating a notebook and pulling some basic data queries inside. Select the same dbo.FactSales table as before, but this time choose New notebook. Then click Load to DataFrame. These actions create a Spark notebook with a short Scala script for loading the table data.

We can select the notebook’s primary language from the dropdown list: Python, Scala, C#, or SQL. Alternatively, we can specify the language inside each entry by adding a tag such as %%sql at the top. We must first load the data into a workspace view before we can work with it. So, we load the tables we want into a temporary view, using a command like the following in Spark:
%%spark
val df = spark.read.sqlanalytics("instafluffsynapsesql.dbo.FactSales")
df.createOrReplaceTempView("factsales")
Now we can run various queries by adding Code cell entries in the notebook then clicking Run all. Here are some examples we can try to start analyzing the sales data:
%%sql /* Count Sales Rows */ SELECT COUNT (*) FROM factsales %%sql /* Get Sales Rows in 2009 */ SELECT * FROM factsales WHERE DateKey >= "2009-01-01T00:00:00Z" AND DateKey <= "2009-12-31T00:00:00Z" ORDER BY DateKey %%sql /* Calculate Sales Revenue by Date */ SELECT DATE_FORMAT(DateKey, "Y-MM-dd"), SUM(SalesAmount) FROM factsales GROUP BY DATE_FORMAT(DateKey, "Y-MM-dd") ORDER BY DATE_FORMAT(DateKey, "Y-MM-dd")
If we try switching an entry’s View from Table to Chat, we should see some colorful data visualizations. Azure Synapse Analytics guesses how to best display the information, but we may need to configure the display using the dropdown options on the right side of the panel.
The total sales revenue by time chart looks like this:

To save the notebook, we click Publish. We’ll be able to go back to our notebook in the future in the Develop tab.

Next Steps
We have now imported our data and have an idea of what it looks like. We can decide what might be worth including as a colorful dashboard chart to share with our managers.
In the following article, we'll take a closer look at this data. We’ll analyze the data to answer some of our business questions and gain insight into expanding and improving our sales. We’ll also create beautiful visualizations to share with our fictional business’ team and executives, so they get the information they need to drive the business forward.
To learn more about Azure Synapse Analytics, register to view the Hands-on Training Series for Azure Synapse Analytics or continue to the final article of this series to explore how to create charts and gain insight into business data.