
Sequence Classifiers in C# - Part I: Hidden Markov Models
4.95/5 (85 votes)
Let's understand hidden Markov models before taking a step into hidden conditional random fields.
Sequence Classification Series
- Sequence Classifiers in C# - Part I: Hidden Markov Models
- Sequence Classifiers in C# - Part II: Hidden Conditional Random Fields
Contents
Introduction
Let's say you have a bunch of sequences of events. Any kind of sequences, such as sequences of scores by your favorite Soccer team. Or sequences of (x,y) coordinates of a movement drawn with your fingers. Or sequences of letters forming a set of words. Wouldn't it be nice if there was a way to characterize those sequences? Perhaps we could elaborate some model which attempts to mimic them, or to behave more or less like the sequences you have - here is where the Hidden Markov Models come.
It is certainly easier to manipulate a model of something than the things itself - we do this with classes in class diagrams, for example. Hidden Markov Models are sequence models. And as such, they allow easier handling of those sequences. If you have a model for them, you assume they follow some regularity, some basic assumptions you can make about them. You can then start grouping together sequences which you assume to follow the same model - and this is basically how sequence classification using hidden Markov models work.
This article aims to present the reader to the current workings of the Accord.NET Machine Learning Framework; show where the sequences classifiers are located within the framework, describe their source code, how the Markov namespace is organized and the general ideas behind this organization. This will also provide the base to talk about Hidden Conditional Random Fields, which is my main goal in this series.
Hidden Markov Models
Think of a black box. At first, you show it some sequences of observations and tell it to learn from them. After that, you can now insert any sequence of observations in the input side of this box and obtain a measure of similarity to the other sequences it had learned as an output.
This is more-or-less what a hidden Markov models does. Those models can be trained - or in other words, estimated - from data sets, just as other machine learning models and methods.

If you just want to use HMMs rather than learn its internals, feel free to jump directly to the code sections right away. Perhaps you are in a hurry to use it on some application, or just test something quickly, there is no problem about it - but don't forget to come back here for the details.
Hidden Markov models are probabilistic models. As any model, they attempt to approximate something else (or the behavior of this something) in a concise and more manageable way, allowing for easier handling of this thing. It is much easier to work with an approximate model than it would be to deal with the real thing. Being probabilistic, it attempts to capture the behavior of this something with probabilities rather than with sure and concrete rules.
 Markov models are also specially suited to model behaviors defined over time. The model assumes those behaviors contains a fixed number of inner states. For example, think of a pinch-and-zoom hand gesture. This gesture certainly has some states: at first, two fingers touch the screen; then they start moving far apart. One could think of these two as two states, which have to occur in this particular to completely denote a pinch-and-zoom gesture.
Markov models are also specially suited to model behaviors defined over time. The model assumes those behaviors contains a fixed number of inner states. For example, think of a pinch-and-zoom hand gesture. This gesture certainly has some states: at first, two fingers touch the screen; then they start moving far apart. One could think of these two as two states, which have to occur in this particular to completely denote a pinch-and-zoom gesture.
These models are also called hidden for a reason. We are not required to tell it what those aforementioned states should be. We just have to tell it how many states we think are needed to model what we want. The model should be able to figure a suitable sequence of states to support our observations.
Being Markov means the model assumes the Markov property holds: it assumes that, in any sequence, the current observation will only be dependent on the most immediate previous one. Consider a sequence of observations x = <x1, x2, ... , xt> and a corresponding sequence of states y = <y1, y2, ... , yt>. Now, please do not be shy in front of the mathematics - the sequence could be a sequence of point coordinates in 2D space, multiple points in 3D space, or even a sequence of bitmap images. The sequence of states is really just a sequence of integer labels, such as <1, 2, 4> or <5, 3, 6, 8>. Those are state labels, and can vary up to the number of states assumed by the model. The Markov property was one of those small but neat ideas that had an immense impact in almost all areas of Science - from speech recognition to DNA matching and all other areas where sequence analysis was of major importance.
Assuming the Markov probability, the probability of any sequence of observations occurring when following a given sequence of states can be stated as:

in which the probabilities p(yt|yt-1) can be read as the probability of being currently in state yt given we just were in the state yt-1 at the previous instant t-1, and the probability p(xt|yt) can be understood as the probability of observing xt at instant t given we are currently in the state yt. To compute those probabilities, we simple use two matrices A and B. The matrix A is the matrix of state probabilities: it gives the probabilities p(yt|yt-1) of jumping from one state to the other, and the matrix B is the matrix of observation probabilities, which gives the distribution density p(xt|yt) associated a given state yt. In the discrete case, B is really a matrix. In the continuous case, B is a vector of probability distributions. The overall model definition can then be stated by the tuple

in which n is an integer representing the total number of states in the system, A is a matrix of transition probabilities, B is either a matrix of observation probabilities (in the discrete case) or a vector of probability distributions (in the general case) and p is a vector of initial state probabilities determining the probability of starting in each of the possible states in the model. Below is the IHiddenMarkovModel interface implemented by discrete and generic hidden Markov models in the Accord.NET Framework.

Note that we have our vector of initial probabilities p, the number of states n and the state-transition matrix A as properties (in order) on the interface definition. As I mentioned before, the matrix of emission densities B can be either a matrix or a vector of probability distributions. Thus said, we have two possible IHiddenMarkovModel implementations: the HiddenMarkovModel and the generic HiddenMarkovModel<TDistribution>:

Note how the non-generic implementation contains a matrix of double-precision floating point number as the Emission matrix B, whereas the generic implementation contains a vector of probability distributions of the TDistribution type (which has a requirement to implement the IDistribution interface). The Accord.NET Framework contains implementations for more than 35 distinct possible probability distributions, including univariate and multivariate distributions of both continuous and discrete nature.
Canonical Problems
There are several things we can do using hidden Markov models. However, the most classic things we can do are the direct solution of some problems associated with HMMs known as the Canonical Problems. Those are the problems of evaluating the probability of a sequence, finding which sequence of states most likely originated a sequence, and learning a hidden Markov model using a given amount of training data.
The first of those two were available in the IHiddenMarkovModel interface given above as the Decode and Evaluate methods. The last, the learning problem, will be given a separate mechanism since it can be solved in several different ways.
Evaluating the Probability of a Sequence
We have already seen how to compute the joint probability of a sequence of observations x when following a sequence of states y. However, as mentioned before, we may not know this sequence of states y. It may be hidden from us, or we would like to make it hidden from our model. So we avoid making any assumptions about y and consider all possible combinations of y in order to draw the probability of x. In other words, we marginalize the joint probability over y by summing over all possible variations of y:
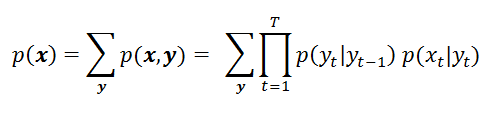
If we had 3 possible states (1, 2 and 3), and a sequence of 4 observations, this would render us the possibilities
(1, 1, 1, 1)
(1, 1, 1, 2)
(1, 1, 1, 3)
(1, 1, 2, 1) ... (exponential complexity listing goes on) ...
(3, 3, 3, 3)
Obviously considering all possible combinations would be quite intractable, even for small sequences or a small number of states. Fortunately for us, somebody already crafted a solution for this problem in the form of the Forward algorithm, which allows us to compute p(x) in exact linear time. Quite a feat! As such, the Forward algorithm is a key piece in many other algorithms such as the Baum Welch estimation algorithm or even other algorithms outside the realm of Markov models.
The Forward algorithm computes a matrix of state probabilities which can be used to assess the probability of being in each of the states at any given time in the sequence. By combining all those probabilities, in the last time slot, we can obtain the overall probability of the sequence occurring considering all possible state transition combinations (the Backward algorithm does almost the same, but starts from the end of the sequence, computing probabilities in reverse order - the evaluation algorithm can be solved using any of the two).

In the Accord.NET Framework, forward (and backward) matrices of probabilities or log-probabilities can be computed seamlessly by invoking any of the static methods in the ForwardBackwardAlgorithm static class located in the Accord.Statistics.Models.Markov namespace.
Let's then create a hidden Markov model and compute the probability for a random integer sequence using Accord.NET. First, we should import the Statistics and Math namespaces, referencing the two assemblies accordingly. Then let's write:
// Create a hidden Markov model with random parameter probabilities
HiddenMarkovModel hmm = new HiddenMarkovModel(states: 3, symbols: 2);
// Create an observation sequence of up to 2 symbols (0 or 1)
int[] observationSequence = new[] { 0, 1, 1, 0, 0, 1, 1, 1 };
// Evaluate its log-likelihood. Result is -5.5451774444795623
double logLikelihood = hmm.Evaluate(observationSequence);
// Convert to a likelihood: 0.0039062500000
double likelihood = Math.Exp(logLikelihood);
We can also create a continuous model with Normally distributed emission densities, for example:
// Create a hidden Markov model with equal Normal state densities
NormalDistribution density = new NormalDistribution(mean: 0, stdDev: 1);
HiddenMarkovModel<normaldistribution> hmm =
new HiddenMarkovModel<normaldistribution>(states: 3, emissions: density);
// Create an observation sequence of univariate sequences
double[] observationSequence = new[] { 0.1, 1.4, 1.2, 0.7, 0.1, 1.6 };
// Evaluate its log-likelihood. Result is -8.748631199228
double logLikelihood = hmm.Evaluate(observationSequence);
// Convert to a likelihood: 0.00015867837561
double likelihood = Math.Exp(logLikelihood);
The Evaluate method implementation simply calls the Forward static method to do the heavily lifting. Here, we have a very small likelihood because our model wasn't trained to anything. By default, the framework initializes the model with equal probabilities.
Decoding a Sequence
On some occasions, we may be interested in the sequence of underlying states that have been followed in order to generate our observed sequence of observations. In order to solve this problem, we can apply the Viterbi algorithm: it was invented by Andrew Viterbi as an error-correcting algorithm for noisy communication channels. It has been used, for example, inside DVD players to correct read errors on-the-fly.
This algorithm finds the most likely sequence of states leading to a sequence of observations, and this optimum sequence of states is often known as the Viberti path. It is closely related to the forward algorithm. However, instead of combining all possible transition paths, it considers only the maximum probability path at each time step. Thus it is often known as a max-sum algorithm for HMMs (the forward algorithm, due to its all-combining characteristic, is known as a sum-product algorithm).
Let's decode the same sequence. However, this time we will be manually specifying the parameters of our models by explicitly stating the matrices A, B and probability vector p:
// Create a model with given probabilities
HiddenMarkovModel hmm = new HiddenMarkovModel(
transitions: new[,] // matrix A
{
{ 0.25, 0.25, 0.00 },
{ 0.33, 0.33, 0.33 },
{ 0.90, 0.10, 0.00 },
},
emissions: new [,] // matrix B
{
{ 0.1, 0.1, 0.8 },
{ 0.6, 0.2, 0.2 },
{ 0.9, 0.1, 0.0 },
},
initial: new[] // vector pi
{
0.25, 0.25, 0.0
});
// Create an observation sequence of up to 2 symbols (0 or 1)
int[] observationSequence = new[] { 0, 1, 1, 0, 0, 1, 1, 1 };
// Decode the sequence: the path will be 1-1-1-1-2-0-1
int[] stateSequence = hmm.Decode(observationSequence);
The values in this example were pretty meaningless. However, what must we get is that the state sequence 1-1-1-1-2-0-1 means that the model started at state 1, then continued on 1 for 3 times, then changed state to 2, changed to 0 and then back to 1. While not immediately obvious, this can be used to classify segments of a sequence, effectively performing sequence segmentation.
Suppose, for example, if our observation sequence were comprised of a sequence of voice utterances. The decoding algorithm is able to attach an integer label to each of the utterances in the sequence. With some effort, we could agglomerate utterances with common labels which could be interpreted as phonemes with increased similarities within the spoken words.
Learning From Sequences
So, up to now, we have either created models with random parameters, or have manually specified the values we wanted. But most often, what we will really be wanting to do is to learn our model automatically from some information source.
And here we have many ways to do it.
At first, we have to decide if we are willing to use a supervised or unsupervised learning algorithm. A supervised learning algorithm, in the context of hidden Markov models, expects the sequence of hidden states associated with each sequence of observations will be available during training. An unsupervised learning algorithm does not.

Examples of supervised learning algorithms is the plain Maximum Likelihood estimate, and an example of unsupervised learning algorithm is the Baum-Welch algorithm and the Viterbi Learning algorithm (although the mechanism of work of the Viterbi learning would seem more like an semi-supervised learning algorithm). The picture below shows some of the learning classes available within the Accord.NET Framework. Note there are separate classes for discrete and generic models for increased efficiency on the simpler discrete case.

Now let's see an example of learning a discrete and an equivalent continuous model using a Baum-Welch algorithm. Those are the most common usage scenarios for the framework:
// Suppose a set of sequences with something in
// common. From the example below, it is natural
// to consider those all start with zero, growing
// sequentially until reaching the maximum symbol 3
int[][] inputSequences =
{
new[] { 0, 1, 2, 3 },
new[] { 0, 0, 0, 1, 1, 2, 2, 3, 3 },
new[] { 0, 0, 1, 2, 2, 2, 3, 3 },
new[] { 0, 1, 2, 3, 3, 3, 3 },
};
// Now we create a hidden Markov model with arbitrary probabilities
HiddenMarkovModel hmm = new HiddenMarkovModel(states: 4, symbols: 4);
// Create a Baum-Welch learning algorithm to teach it
BaumWelchLearning teacher = new BaumWelchLearning(hmm);
// and call its Run method to start learning
double error = teacher.Run(inputSequences);
// Let's now check the probability of some sequences:
double prob1 = Math.Exp(hmm.Evaluate(new[] { 0, 1, 2, 3 })); // 0.013294354967987107
double prob2 = Math.Exp(hmm.Evaluate(new[] { 0, 0, 1, 2, 2, 3 })); // 0.002261813011419950
double prob3 = Math.Exp(hmm.Evaluate(new[] { 0, 0, 1, 2, 3, 3 })); // 0.002908045300397080
// Now those obviously violate the form of the training set:
double prob4 = Math.Exp(hmm.Evaluate(new[] { 3, 2, 1, 0 })); // 0.000000000000000000
double prob5 = Math.Exp(hmm.Evaluate(new[] { 0, 0, 1, 3, 1, 1 })); // 0.000000000113151816
Now here lies an interesting observation. The output values are not exactly probabilities, but likelihoods. Likelihoods can be seen as unnormalized probabilities, and as such, can not tell us much when they are taken alone and out of context. However, they can be compared with the other likelihoods. In the example above, the likelihood of the sequences similar to the ones in the training set are far greater (at least 7 orders of magnitude) than the likelihood of the sequences which clearly do not fit in the model.
And this will be really useful to create sequence classifiers in the next sections of this article.
State-Transition Topologies
A common characteristic often defined for hidden Markov models is their state-transition topology. Consider, for example, the case where we are analyzing sequences in time, such as spoken words. It may be useful to assume that once we are in a given state, we cannot travel back in time to a previously seem state. Thus state transitions are only allowed forward.

Example of state-transition topologies. Left: Ergodic. Right: Forward-only
A topology where one can only go forward is called Forward. A topology where all states can be reached from any state in the model is called Ergodic. To define those topologies, all we have to do is to set the initial transitions matrix A accordingly: upper or left triangular for forward-only topologies, all values higher than zero for ergodic. But there are a few other customizations, such as band-forward matrices and random or equiprobable initializations. For this reason, the framework provides the ITopology specification and many concrete types implementing the basic topologies, illustrated below:

To initialize a model using any of those topology specifications, simply create an ITopology object and pass it to the constructor of a hidden Markov model. It will know what to do with it! 
Sequence Classification
Up to now, we have seen what a hidden Markov model is, what it does and how it can be created. But what if we have many kinds of sequences, and we would like to differentiate between them? For example, consider we have pinch-and-zoom gestures, swipe gestures, and other kind of gestures. As we have seen in the introduction of this article, each of those can be seen as sequence of multidimensional points in some space of coordinates. Suppose we wish to distinguish between them: we would like a method which could return a "1" for pinch-and-zoom, "2" for swipe and "3" for something else. To solve this problem, we need a sequence classifier.
But how can we create one?

Let's get back to that black-box representation of a hidden Markov model. In that representation, we give a sequence of observations on one side of the box and it gives its probability on the other side. If we estimate a different model for each kind of sequence (i.e., one model for pinch-and-zoom, other model for swipe, ...) then we would have three models able to give us the different likelihoods for gesture to be labeled.
Now remember likelihoods can be compared among them: if we choose the model with higher likelihood to be the best choice for the label of this new gesture, we will have a method for sequence classification - more specifically, we will have what is commonly referred as the maximum likelihood classifier.
However, the likelihood of an observation happening given a class model is different from the likelihood of the class being of the sequence given. Choosing the maximum likelihood may not be the optimum choice for all problems - such as in the case, for example, of unbalanced proportion of classes or in the case we have only a few training observations for each sequence. One possible solution? To multiply each likelihood generated by each model by some factor: add this simple trick while multiplying by a guess of the class probabilities and we have a Bayesian maximum a posteriori classifier.
In the maximum likelihood (ML) decision rule, we take the likelihood of the sequence as if it was the probability of the class given the sequence. The maximum likelihood decision rule can be stated as:

meaning "we choose the class ωj as the estimated label for the sequence if it is the class which results in the maximum probability output by the formula. Each model ω<sub>j</sub> gives us an estimate of the probability p(x|ω<sub>j</sub>), so we can just replace each p(x|ω<sub>j</sub>) with the likelihood given as output by the model. See the picture below for a schematic representation of this process.

The maximum a posteriori decision rule, on the other hand, attempts to select the class with maximum probability given the sequence, which is much more logical. However, there is no safe bridge connecting the individual model likelihoods given as output by our models to the posterior probabilities we are so interested. There is the Bayes rule, however, while the formula and theory works perfectly, often we do not have a reliable way of estimating the required class probabilities p(ω<sub>j</sub>). The Bayes rule states that:

which means we can achieve a maximum a posteriori (MAP) decision rule by taking:

which seems a much more reasonable goal, assuming we can figure out the true estimates of the probabilities involved. One interesting thing to note is that the ML and the MAP decision criteria are completely equivalent in the case we chose equal prior probabilities for p(ω<sub>j</sub>) - or, in other words, use non-informative priors.
Going to the actual implementation of the aforementioned models and formulas, again there will be separate classes for discrete and generic distribution models. The HiddenMarkovClassifier and the HiddenMarkovClassifier<TDistribution> are both implementers of the IHiddenMarkovClassifier interface.

As it can be seen, they have a vector of IHiddenMarkovModels each; HiddenMarkovModels, in the case of the discrete classifier, and HiddenMarkovModels<TDistribution>, in case of the generic version. We also have the possibility of specifying prior probabilities (which can be seen as just scaling factors) by adjusting the Priors vector of double-precision floating-point values.
The properties, Sensitivity and Threshold are used for Threshold Models, which are a way to incorporate rejection in those models, but which will be left outside the scope of this article.
To learn a hidden Markov classifier, all we have to do is teach the inner Markov models inside the classifier on training samples which are respective to a single classification label. This means each model will be trained locally on its own sequences, having no knowledge of any other sibling models and their sequences. As we will see shortly, the hidden Markov classifiers are generative models, in which each model attempts to estimate a separate density model which should then be combined using the Bayes rule.

To accomplish this inner model learning, we can use the HiddenMarkovClassifierLearning classes. Those classes simply apply any chosen learning algorithm to the inner models, but allow for a great deal of flexibility. The learning algorithms can be created, configured and tuned individually for each model through the use of lambda expressions.
// Suppose we would like to learn how to classify the
// following set of sequences among three class labels:
int[][] inputSequences =
{
// First class of sequences: starts and
// ends with zeros, ones in the middle:
new[] { 0, 1, 1, 1, 0 },
new[] { 0, 0, 1, 1, 0, 0 },
new[] { 0, 1, 1, 1, 1, 0 },
// Second class of sequences: starts with
// twos and switches to ones until the end.
new[] { 2, 2, 2, 2, 1, 1, 1, 1, 1 },
new[] { 2, 2, 1, 2, 1, 1, 1, 1, 1 },
new[] { 2, 2, 2, 2, 2, 1, 1, 1, 1 },
// Third class of sequences: can start
// with any symbols, but ends with three.
new[] { 0, 0, 1, 1, 3, 3, 3, 3 },
new[] { 0, 0, 0, 3, 3, 3, 3 },
new[] { 1, 0, 1, 2, 2, 2, 3, 3 },
new[] { 1, 1, 2, 3, 3, 3, 3 },
new[] { 0, 0, 1, 1, 3, 3, 3, 3 },
new[] { 2, 2, 0, 3, 3, 3, 3 },
new[] { 1, 0, 1, 2, 3, 3, 3, 3 },
new[] { 1, 1, 2, 3, 3, 3, 3 },
};
// Now consider their respective class labels
int[] outputLabels =
{
/* Sequences 1-3 are from class 0: */ 0, 0, 0,
/* Sequences 4-6 are from class 1: */ 1, 1, 1,
/* Sequences 7-14 are from class 2: */ 2, 2, 2, 2, 2, 2, 2, 2
};
// We will use a single topology for all inner models, but we
// could also have explicitled different topologies for each:
ITopology forward = new Forward(states: 3);
// Now we create a hidden Markov classifier with the given topology
HiddenMarkovClassifier classifier = new HiddenMarkovClassifier(classes: 3,
topology: forward, symbols: 4);
// And create an algorithms to teach each of the inner models
var teacher = new HiddenMarkovClassifierLearning(classifier,
// We can specify individual training options for each inner model:
modelIndex => new BaumWelchLearning(classifier.Models[modelIndex])
{
Tolerance = 0.001, // iterate until log-likelihood changes less than 0.001
Iterations = 0 // don't place an upper limit on the number of iterations
});
// Then let's call its Run method to start learning
double error = teacher.Run(inputSequences, outputLabels);
// After training has finished, we can check the
// output classification label for some sequences.
int y1 = classifier.Compute(new[] { 0, 1, 1, 1, 0 }); // output is y1 = 0
int y2 = classifier.Compute(new[] { 0, 0, 1, 1, 0, 0 }); // output is y1 = 0
int y3 = classifier.Compute(new[] { 2, 2, 2, 2, 1, 1 }); // output is y2 = 1
int y4 = classifier.Compute(new[] { 2, 2, 1, 1 }); // output is y2 = 1
int y5 = classifier.Compute(new[] { 0, 0, 1, 3, 3, 3 }); // output is y3 = 2
int y6 = classifier.Compute(new[] { 2, 0, 2, 2, 3, 3 }); // output is y3 = 2
As it can be seen, the classifier was able to correctly classify every sequence we tested in the example above. But this doesn't mean it will be always correct.
Using the Code
Some examples have already been shown, however, let's show a concrete example of a sample application using hidden Markov model classifiers with continuous multivariate Gaussian (Normal) densities, one of the most requested uses for the framework.
Suppose we would like to detect mouse gestures.
Mouse gestures can be seen as sequences of 2D points defined in the screen coordinate space. As 2D points, I really meant they can be concretely represented by System.Collection.Generic.Lists of System.Drawing.Points objects - or anything else implementing the IEnumerable interface containing Points.


The gestures represented above have started on the red mark and ended on the blue mark. As soon as one have clicked the mouse, the gesture starts drawing in red and ends in blue. This is only to give us a time orientation when seeing the gesture. The gesture, itself, is stored as an ordered array of Point objects.
Before feeding those sequences of Point objects into our classifier learning algorithm, we have to transform them into sequences of double arrays. Each point is transformed into a double[] { x, y } containing the x and y coordinates of the point. The complete gesture are then stored as double[][] array containing each of the aforementioned points.
As the next step, we create our models:
hmm = new HiddenMarkovClassifier<MultivariateNormalDistribution>(numberOfClasses,
new Forward(states), new MultivariateNormalDistribution(2), classes);
Here, we will be considering a fixed number of states, arbitrarily fixed on 5. Supposedly one could base this on some a priori knowledge or other assumptions on what is about to be modeled, but often one would have to tune those to see what may work better.
After the model have been created, we can create a learning algorithm to train the classifier.
// Create the learning algorithm for the ensemble classifier
var teacher = new HiddenMarkovClassifierLearning<MultivariateNormalDistribution>(hmm,
// Train each model using the selected convergence criteria
i => new BaumWelchLearning<MultivariateNormalDistribution>(hmm.Models[i])
{
Tolerance = tolerance,
Iterations = iterations,
FittingOptions = new NormalOptions()
{
Regularization = 1e-5
}
}
);
And this is all which is needed to create our recognition models. Now, if you wish, please download the sample application available in the top of this article so we can get started. The application performs gesture recognition using the mouse. In fact, you could use it for other things as well - such as signature recognition. It is just a sample application on how to use hidden Markov models. The application is shown below:

After the application has been opened, you will be granted with a drawing canvas. You can click on the canvas you can start drawing any gesture you would like. Gestures start red, then gradually switch to blue. This gives an information about the time-orientation of the gesture. After you have finished drawing your gesture, tell the application what you have drawn by writing in box right after the "What's this" text mark.


After you have registered a few gestures, you are ready to learn a classifier. In order to do so, click the button "Learn a Hidden Markov Model classifier". The classifier will learn (using default learning settings) and will immediately attempt to classify the set of gestures you created. Gestures marked in green will have been successfully recognized by the classifier.


Now, if you start drawing another gesture, you will notice that once you release the mouse button the application will attempt to classify your gesture and will also ask if the answer was correct. You can try a few times and reinforce learning by adding more examples of gestures it didn't classify correctly. Click the "Learn a Hidden Markov Model Classifier" button to learn the gestures again.
Now, you will see that eventually some gestures just can't be recognized properly. If you are curious how we can improve the sequence classifiers, head on to the next article in the series, Part II: Hidden Conditional Random Fields.
Conclusion
In this article, we explored what a Hidden Markov Models is and what it can do. After a brief theory, the article had shown how to create, learn and use HMMs created by the Accord.NET Framework. The sample application shown in the article is part of the Accord.NET Framework Sample Applications, and demonstrates how to use continuous-density, Gaussian, HMMs to recognize gestures drawn in the screen with the mouse.
History
- 6th February, 2013 - Article submission
- 11th March, 2013 - Included links to the second article
- 3rd December, 2014 - Fixed all links that were broken after the project webpage moved
See Also
- The Accord.NET Framework: Machine learning, image processing and scientific computing for .NET
- Haar-feature object detection in C# (The Viola-Jones Classifier)
- Handwriting Recognition using Kernel Discriminant Analysis
- Handwriting Recognition Revisited: Kernel Support Vector Machines
- Automatic Image Stitching with Accord.NET
- Kernel Functions for Machine Learning Applications
- Principal Component Analysis (PCA)
- Kernel Principal Component Analysis (KPCA)
- Linear Discriminant Analysis (LDA)
- Non-Linear Discriminant Analysis with Kernels (KDA)
- Logistic Regression Analysis